自已做网站网站后台管理器怎么做

一. 项目介绍
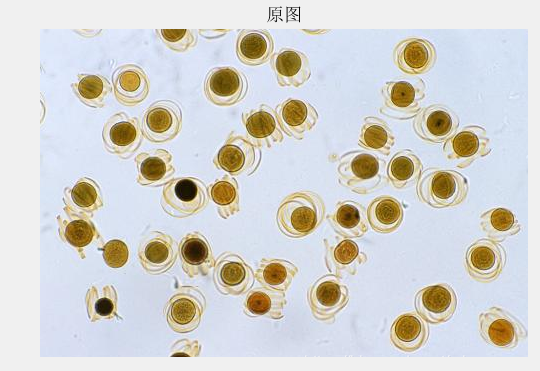
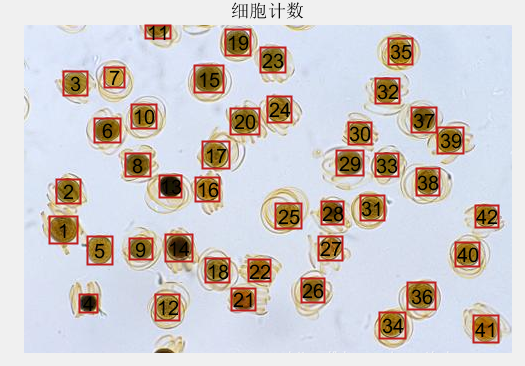
使用MATLAB编写的细胞图像分割及计数系统,实现了对图像内细胞的计数,以及对每个细胞周长和面积的测量,并分别展示了分割后的每个细胞的图像。实验步骤共分为图像预处理、图像预分割、空洞填充、黏连细胞分割、细胞个数统计、细胞特征统计及显示。
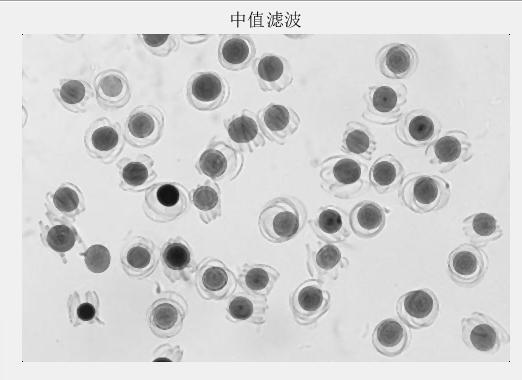
1.图像预处理:使用中值滤波对细胞图像进行保边去噪的处理。
2.预分割:用大津法Otsu进行二值化预分割,将细胞作为前景分割出来。
3.孔洞填充:对分割后的二值图,实施开运算,充细胞中的孔洞,使轻微粘连细胞分开及细小的细胞消失。
4.细胞个数统计及显示:首先删除掉边缘上的细胞,再利用四连通区域标记算法统计分割后非粘连细胞的个数,最后在原图上标记出分割好的细胞,并标号。
二. 相关算法原理
1.中值滤波
中值滤波(Median Filtering)是一种非线性数字滤波技术,广泛用于信号处理和图像处理领域,特别是在去除噪声方面。它的主要思想是通过使用滑动窗口将信号或图像中的每一个数据点用其邻域内所有数据点的中值来替换,从而有效地去除脉冲噪声(即椒盐噪声)。
2.大津法Otsu
大津法(Otsu's Method)是一种用于图像分割的自动阈值选择方法。它是由日本学者大津于1979年提出的,常用于将灰度图像转换为二值图像。大津法通过最大化类间方差来确定最佳阈值,从而将图像分为前景和背景两部分。
3.开闭运算
在形态学图像处理中,开运算和闭运算是两种基本的操作,主要用于处理二值图像。这些运算可以去除噪声、分离连通部分、平滑图像轮廓等。开运算和闭运算是基于膨胀(dilation)和腐蚀(erosion)操作的组合。
三.实验结果


完整代码获取
Matlab图像处理——细胞图像的分割和计数显示
最后:
小编会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!