个体户可以做开发网站业务嘛wordpress crossapple
1.熟悉、梳理、总结下
SQL Server相关知识体系。
2.日常研发过程中使用较少,随着时间的推移,很快就忘得一干二净,所以梳理总结下,以备日常使用参考
3.欢迎批评指正,跪谢一键三连!
- 总结源文件资源下载地址: SQL Server 2016常用函数实战经验总结.zip
- 总结源文件资源下载地址: SQL Server 2016常用函数实战经验总结.zip
文章目录
- 1.快速搭建`SQL Server`环境实操
- 2.基础函数及使用总结
- 3.`SQL Server`部分函数测试样例(`SQL`)
- 4.参考文章
1.快速搭建SQL Server环境实操
- 【kettle003】kettle访问SQL Server数据库并处理数据至execl文件
- 【kettle003】kettle访问SQL Server数据库并处理数据至execl文件
2.基础函数及使用总结
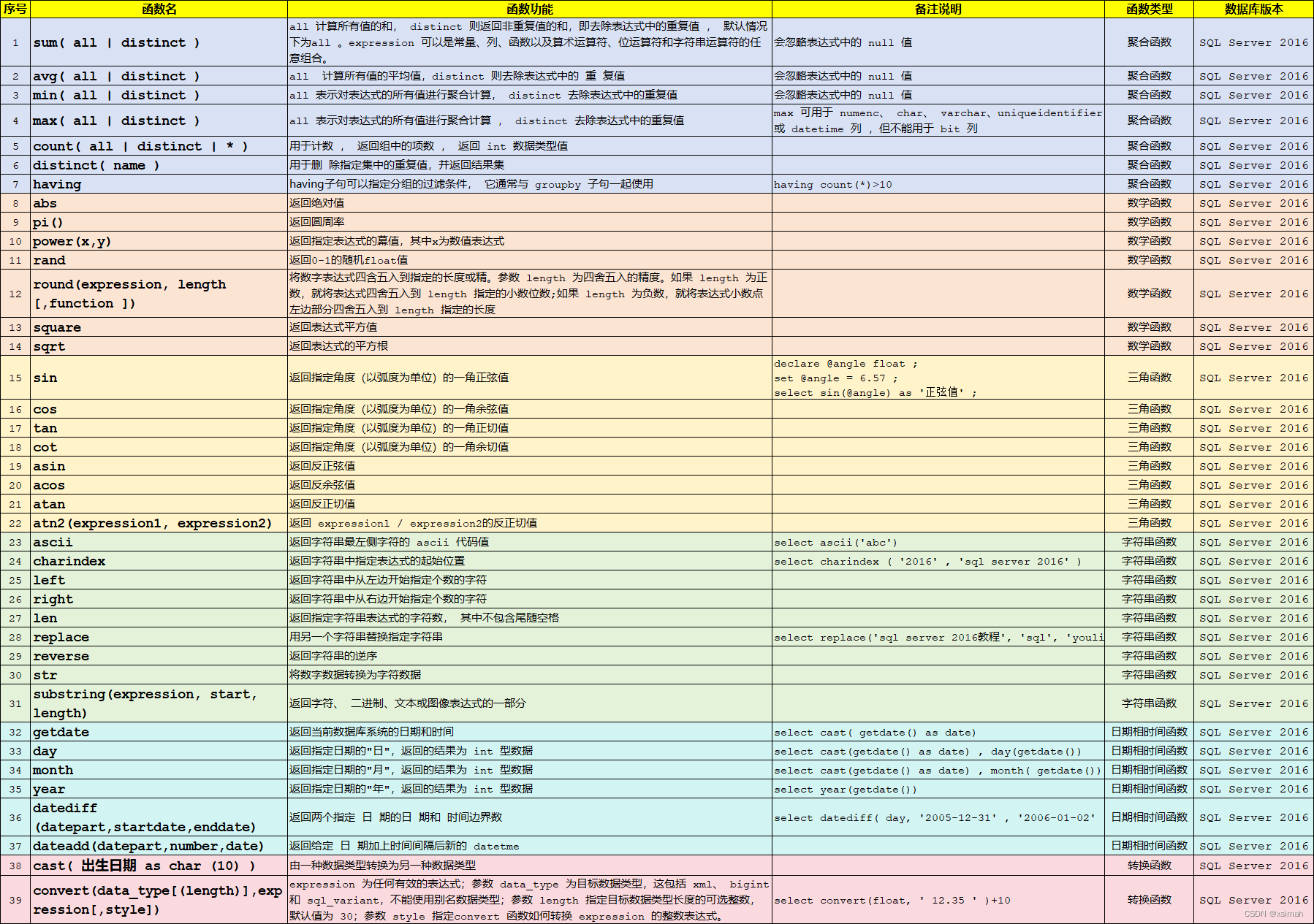
- 1.1
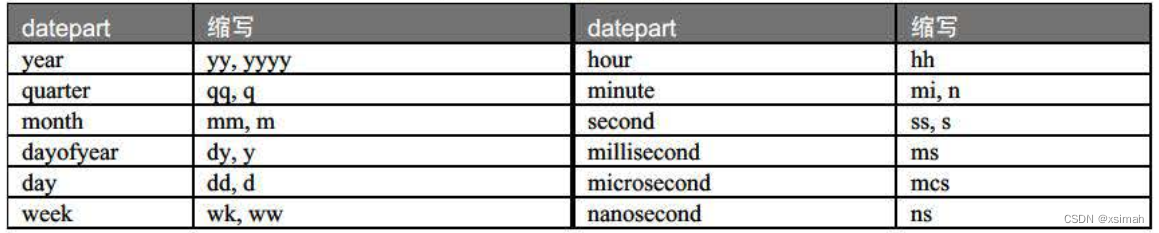
datediff-datepart格式对应关系
3.SQL Server部分函数测试样例(SQL)
-
-- sum( all | distinct ) -- avg( all | distinct ) -- min( all | distinct ) -- max( all | distinct ) -- count( all | distinct | * ) -- distinct( name ) -- having -- abs -- pi() -- power(x,y) -- rand -- round(expression, length [,function ]) -- square -- sqrt -- sin -- cos -- tan -- cot -- asin -- acos -- atan -- atn2(expression1, expression2) -- ascii -- charindex -- left -- right -- len -- replace -- reverse -- str -- substring(expression, start, length) -- getdate -- day -- month -- year -- datediff (datepart,startdate,enddate) -- dateadd(datepart,number,date) -- cast( 出生日期 as char (10) ) -- convert(data_type[(length)],expression[,style]) -- 创建数据库并指定默认字符集 create database Youli collate chinese_prc_ci_as; -- 使用新建数据库 use Youli; -- 创建测试表 create table youli_testtable (id int primary key, -- 定义id为主键name nvarchar(50), -- 定义name为可变长度字符串字段,最大长度50birthday date, -- 定义birthday为日期类型字段score float ); -- 插入一些示例数据 insert into youli_testtable (id, name, birthday, score) values (1, '张三', '1990-01-01', 80.5); insert into youli_testtable (id, name, birthday, score) values (2, '李四', '1991-02-01', 82); insert into youli_testtable (id, name, birthday, score) values (3, '王五', '1992-03-01', 93); insert into youli_testtable (id, name, birthday, score) values (4, '张三', '1990-01-01', 78); insert into youli_testtable (id, name, birthday, score) values (5, '李四', '1991-02-01', 98); insert into youli_testtable (id, name, birthday, score) values (6, '王五', '1992-03-01', 82); insert into youli_testtable (id, name, birthday, score) values (7, '李四', '1991-02-01', 98); insert into youli_testtable (id, name, birthday, score) values (8, '王五', '1992-03-01', 82);declare @angle float ; set @angle = 6.57 ; select sin(@angle) as '正弦值' ;select ascii('abc'); select charindex ( '2016' , 'sql server 2016' ); select replace('sql server 2016教程', 'sql', 'youlisql'); select cast( getdate() as date); select cast(getdate() as date) , day(getdate()); select cast(getdate() as date) , month( getdate()); select year(getdate()); select datediff( day, '2005-12-31' , '2006-01-02' ); select convert(float, ' 12.35 ' )+10;
4.参考文章
- 【kettle003】kettle访问SQL Server数据库并处理数据至execl文件
- 【kettle003】kettle访问SQL Server数据库并处理数据至execl文件