免费vip电影网站怎么做简洁大方的网站
nvm 全名 node.js version management,是一个 nodejs 的版本管理工具。通过它可以安装和切换不同版本的 nodejs。
注:如果已经安装了 nodejs 需先卸载后再安装 nvm
为了确保 nodejs 已彻底删除,可以看看安装目录中是否有 node 文件夹,有的话一起删除。再看看 "C:\Users\用户名" 文件夹下有没有 .npmrc 以及 .yarnrc 等都删除掉。再看看环境变量中有没有 node 相关的,有的话也一起删除掉。
下载 nvm 并安装
1、到 GitHub 下载最新的 nvm 版本,找到 nvm-setup.zip 并下载
2、解压缩后双击 nvm-setup.exe 文件进行安装
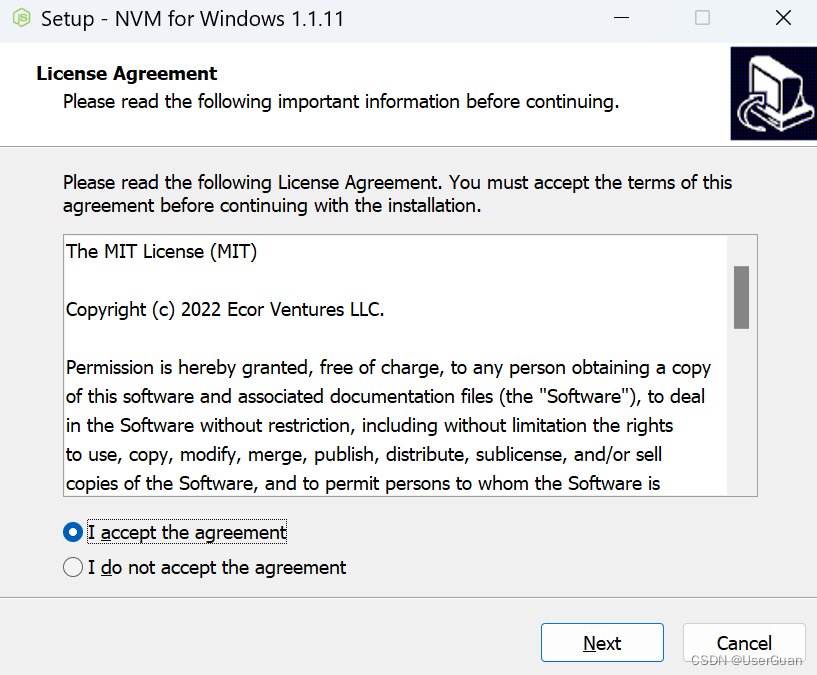
3、点击 Next,选择 nvm 安装路径
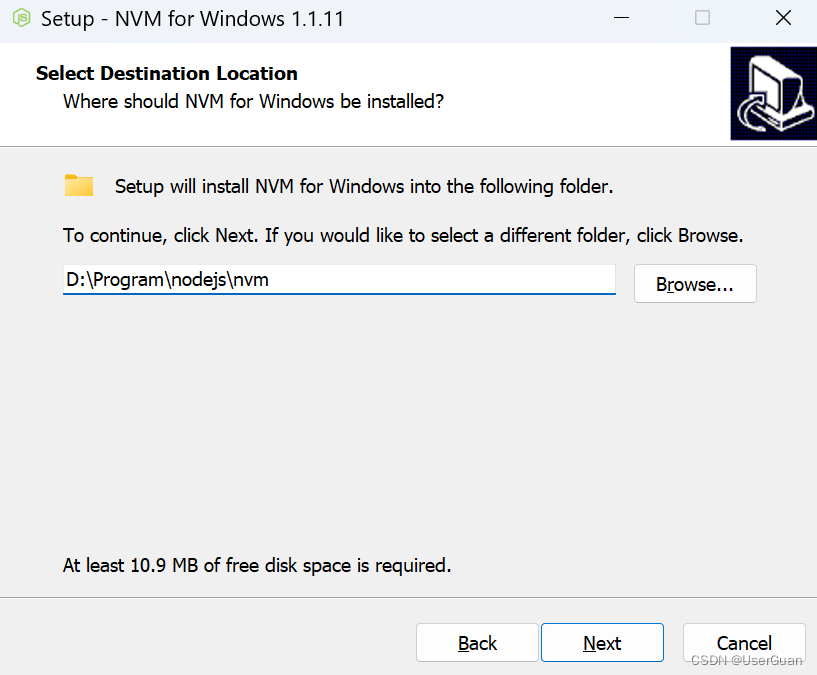
4、点击 Next,选择 nodejs 安装路径
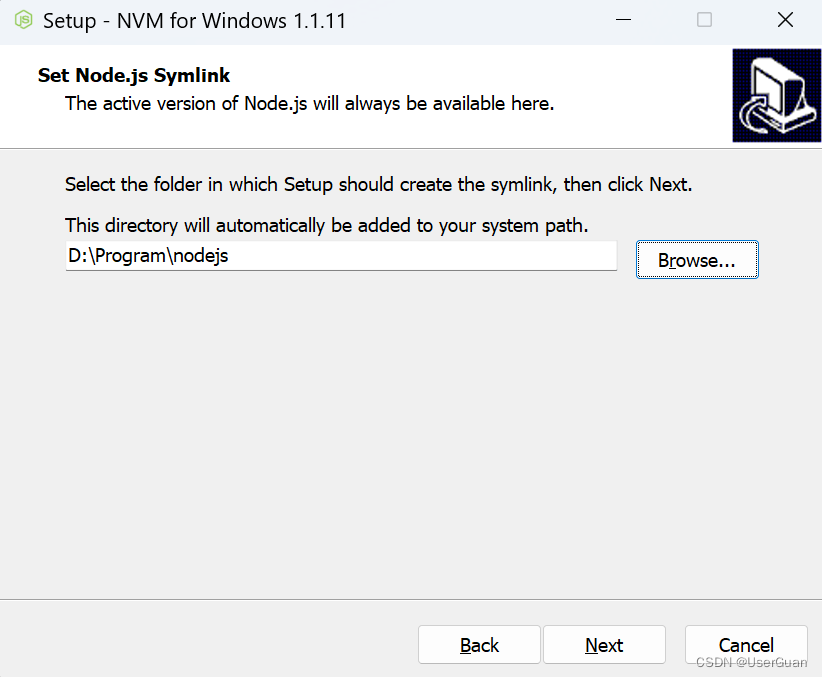
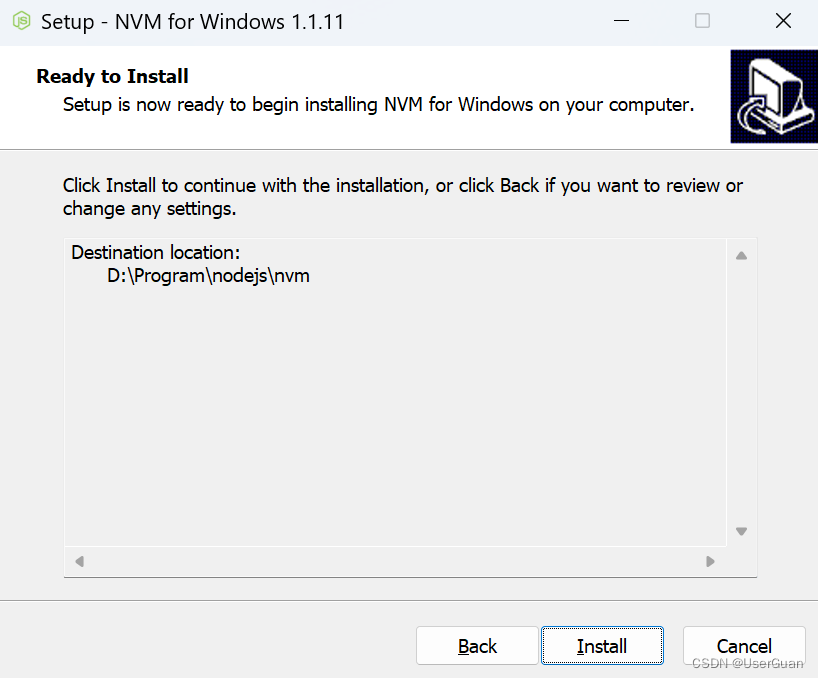
5、点击 Install,确认安装即可
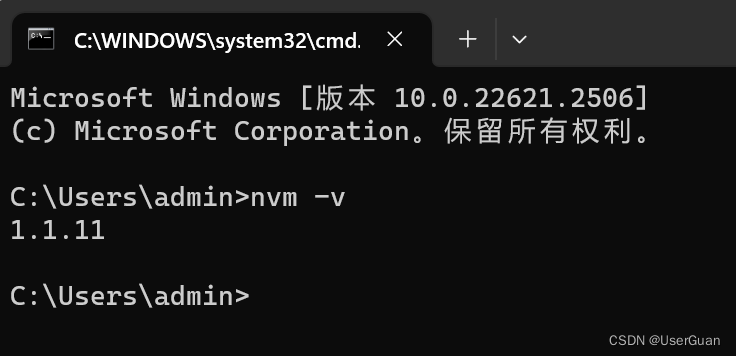
6、安装完成后在终端输入 nvm -v,能查到版本号,说明安装成功了
配置路径和下载源
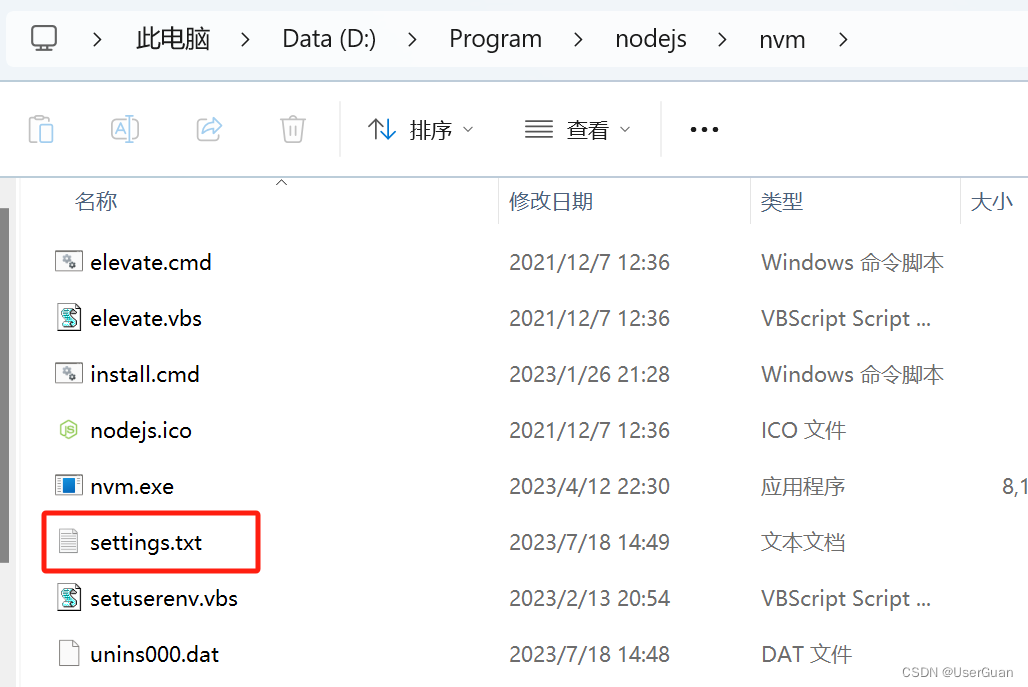
1、安装成功后打开 nvm 的安装目录,找到 settings.txt 文件
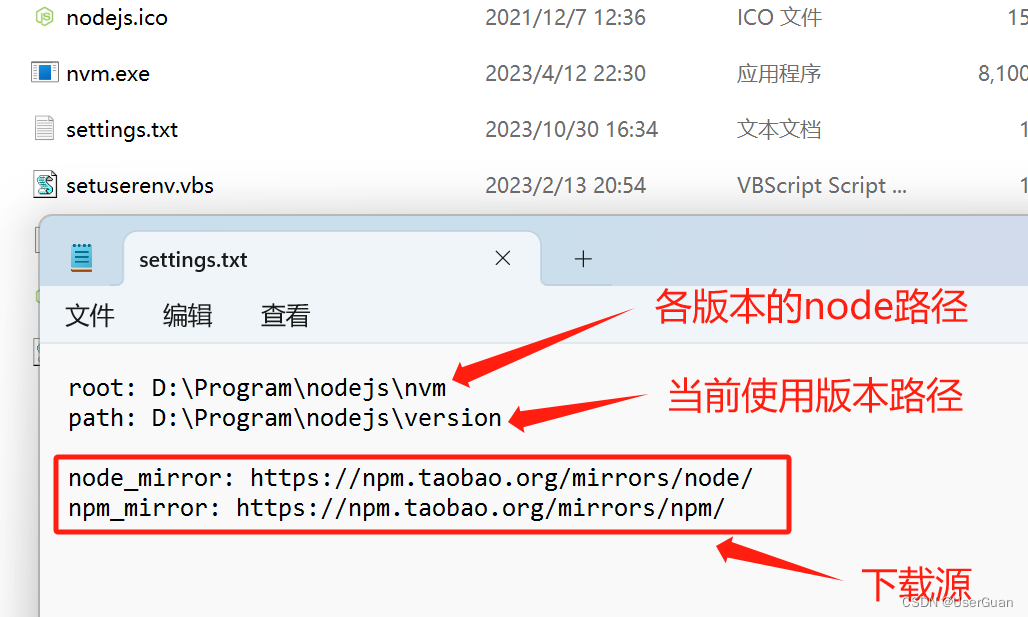
2、配置下载源
root: D:\Program\nodejs\nvm
path: D:\Program\nodejs\versionnode_mirror: https://npm.taobao.org/mirrors/node/
npm_mirror: https://npm.taobao.org/mirrors/npm/
3、配置环境变量
系统变量中
NVM_HOMENVM_SYMLINKPath 中
%NVM_HOME%%NVM_SYMLINK%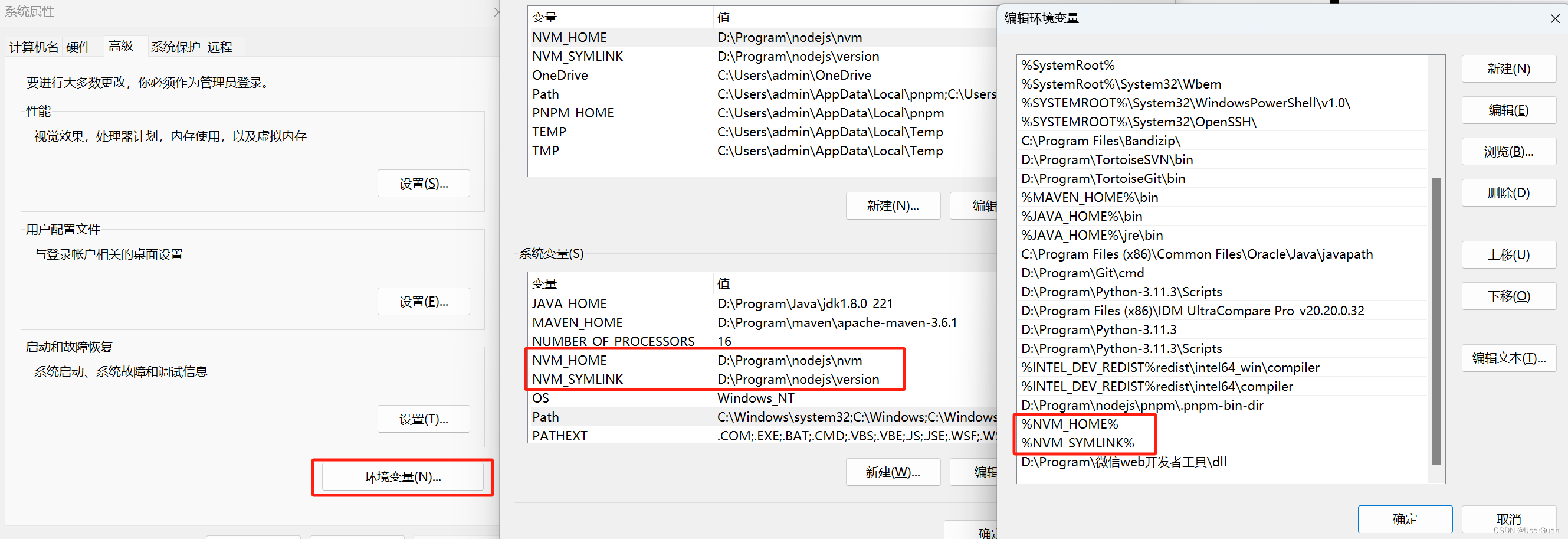
使用 nvm 安装 node
在终端输入 nvm list available,查看网络可以安装的版本
nvm list available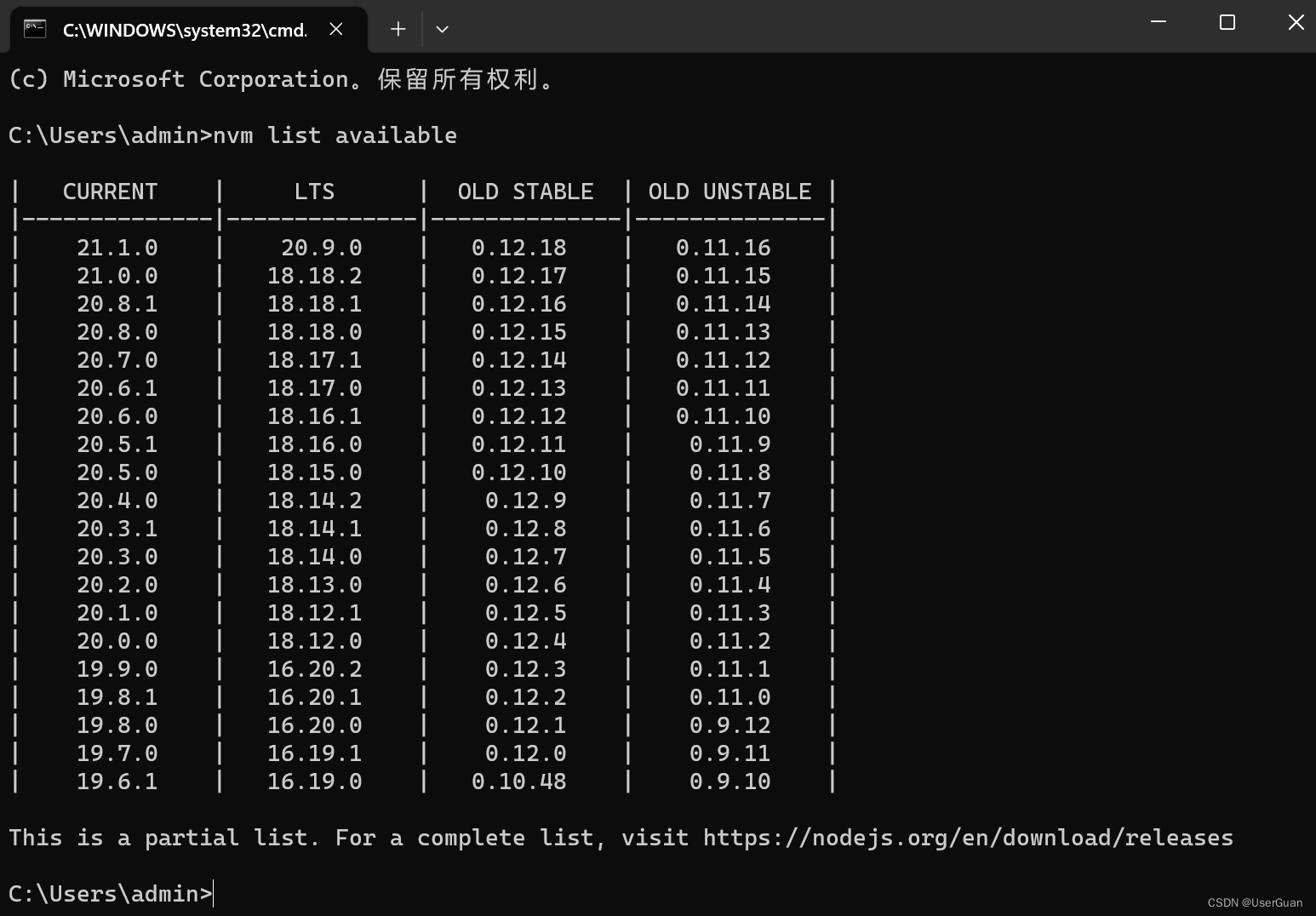
在终端输入 nvm install xx.xx.x 选择一个版本安装,如:nvm install 14.21.3
nvm install 14.21.3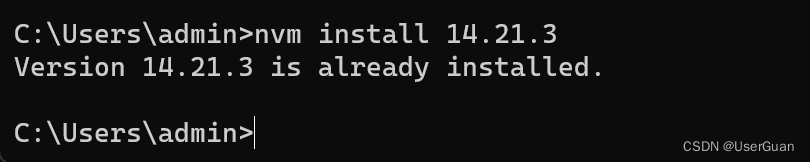
在终端输入 nvm list 查看已经安装的 node,*号表示当前使用的 node 版本
nvm list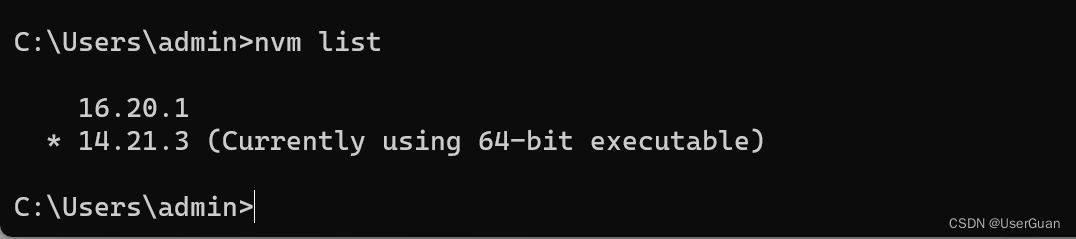
nvm 常用命令
| 命令 | 说明 |
|---|---|
| nvm list | 查看已经安装的版本 |
| nvm list installed | 查看已经安装的版本 |
| nvm list available | 查看网络可以安装的版本 |
| nvm arch | 查看当前系统的位数和当前 nodejs 的位数 |
| nvm install [arch] | 安装指定版本的 node 并且可以指定平台 version 版本号 arch 平台 |
| nvm on | 打开 nodejs 版本控制 |
| nvm off | 关闭 nodejs 版本控制 |
| nvm proxy [url] | 查看和设置代理 |
| nvm node_mirror [url] | 设置或查看 setting.txt 中的 node_mirror,如果不设置,默认是: https://nodejs.org/dist/ |
| nvm npm_mirror [url] | 设置或查看 setting.txt 中的 npm_mirror,如果不设置,默认是: https://github.com/npm/npm/archive/ |
| nvm uninstall | 卸载指定的版本 |
| nvm use [version] [arch] | 切换指定的 node 版本和位数 |
| nvm root [path] | 设置和查看 root 路径 |
| nvm version | 查看当前的版本 |