生活做爰网站做一个网页版面多少钱
N32G430 内部Flash的读写操作
1、主存储区最大为 64KB,也称作主闪存存储器,包含 32 个 Page,用于用户程序的存放和运行,以及数 据存储。
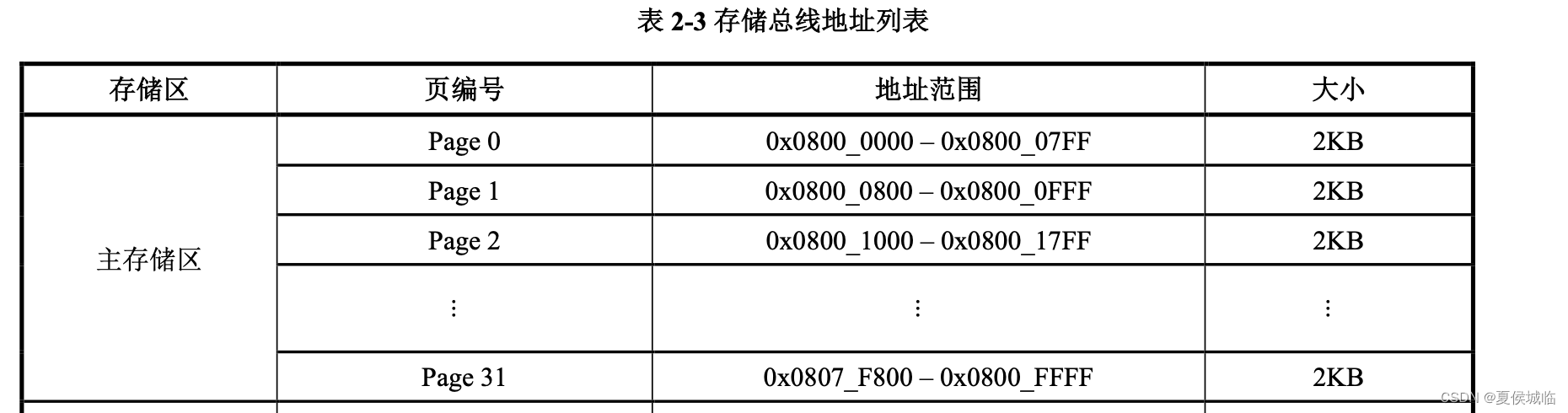
每一页的大小为2K字节
2、IAP 升级我们将64K的flash分区如下:
Boot 0x8000000 – 0x8004000 16KB
Settings 0x8004000 – 0x8006000 8KB
App 0x8006000 – 0x800B000 20KB
Download 0x800B000 – 0x800FFFF 20KB
3、我们在程序里从0x8004000地址往flash写入一行字符串,然后再从flash读出。
新增flash.c flash.h文件
代码如下:
#include "flash.h"// 擦除函数
void n32_flash_erase(uint32_t start_addr, uint32_t end_addr)
{int page_num = 0; FLASH_Unlock();/* erase the flash pages */while(start_addr < end_addr){page_num = (start_addr - N32_FLASH_BASE) / FLASH_PAGE_SIZE;if (FLASH_EOP != FLASH_One_Page_Erase(page_num * FLASH_PAGE_SIZE)){Max_Info("Flash EraseOnePage Error. Please Deal With This Error Promptly\r\n");FLASH_Lock();return;}start_addr += FLASH_PAGE_SIZE;}FLASH_Lock();
}// 写函数
MI_BOOL n32_flash_write(MI_U32 dest_addr, MI_U8 *src, MI_U32 Len)
{MI_U32 i = 0;FLASH_Unlock();for(i = 0; i < Len; i += 4){/* Device voltage range supposed to be [2.7V to 3.6V], the operation willbe done by byte */if(FLASH_EOP == FLASH_Word_Program((MI_U32)(dest_addr+i), *(uint32_t*)(src+i))){/* Check the written value */if(*(uint32_t *)(src + i) != *(uint32_t*)(dest_addr+i)){/* Flash content doesn't match SRAM content */FLASH_Lock(); return -1;}}else{FLASH_Lock(); /* Error occurred while writing data in Flash memory */return -1;}}FLASH_Lock(); return 0;
}// 读函数
MI_BOOL n32_flash_read(MI_U32 dest_addr, MI_U8* buff, MI_U32 Len)
{MI_U32 i;for(i = 0; i < Len; i++){buff[i] = *(__IO MI_U8*)(dest_addr + i);}/* Return a valid address to avoid HardFault */return 0;
}
flash.h
#ifndef __FLASH_H__
#define __FLASH_H__#include "type.h"
#include "main.h"#define BOOT_START_ADDRESS 0x08000000U
#define BOOT_END_ADDRESS 0x08004000U
#define BOOT_SIZE = BOOT_END_ADDRESS - BOOT_START_ADDRESS#define SETTINGS_START_ADDRESS 0x08004000U
#define SETTINGS_END_ADDRESS 0x08006000U
#define SETTINGS_SIZE = SETTINGS_END_ADDRESS - SETTINGS_START_ADDRESS#define APP_START_ADDRESS 0x08006000U
#define APP_END_ADDRESS 0x0800B000U
#define APP_SIZE = APP_END_ADDRESS - APP_START_ADDRESS#define DOWNLOAD_START_ADDRESS 0x0800B000U
#define DOWNLOAD_END_ADDRESS 0x0800FFFFU
#define DOWNLOAD_SIZE DOWNLOAD_END_ADDRESS - DOWNLOAD_START_ADDRESS/* FLASH大小 : 64K */
#define N32_FLASH_SIZE 0x00010000UL
/* FLASH起始地址 */
#define N32_FLASH_BASE 0x08000000UL
/* FLASH结束地址 */
#define N32_FLASH_END (STM32_FLASH_BASE | STM32_FLASH_SIZE)#define FLASH_PAGE_SIZE ((uint32_t)0x800)#define STM32_FLASH_PAGE_NUM (STM32_FLASH_SIZE / FLASH_PAGE_SIZE)void n32_flash_erase(uint32_t start_addr, uint32_t end_addr) ;
MI_BOOL n32_flash_read(MI_U32 dest_addr, MI_U8* buff, MI_U32 Len);
MI_BOOL n32_flash_write(MI_U32 dest_addr, MI_U8 *src, MI_U32 Len);
#endif // __FLASH_H__
main.c
#include <string.h>
#include "main.h"
#include "bsp_led.h"
#include "bsp_delay.h"
#include "usart.h"
#include "timer.h"
#include "pwm.h"
#include "key_input.h"
#include "flash.h"
/***\*\name main.*\*\fun main function.*\*\param none.*\*\return none.
**/
int main(void)
{led_init();usart1_init();usart2_init();timer6_init();tim2_pwm_init();key_input_init();/* Delay 1s */SysTick_Delay_Ms(1000);n32_flash_erase(SETTINGS_START_ADDRESS,SETTINGS_END_ADDRESS);MI_CHAR *data = "hello n32g430c8l7";MI_U8 r_data[24]= {0};SysTick_Delay_Ms(1000);n32_flash_write(SETTINGS_START_ADDRESS,(MI_U8 * )data,strlen(data));SysTick_Delay_Ms(1000);n32_flash_read(SETTINGS_START_ADDRESS,r_data,strlen(data));Max_Info("n32_flash_read == %s\r\n",r_data);while(1){}
}
烧入程序后打印如下:
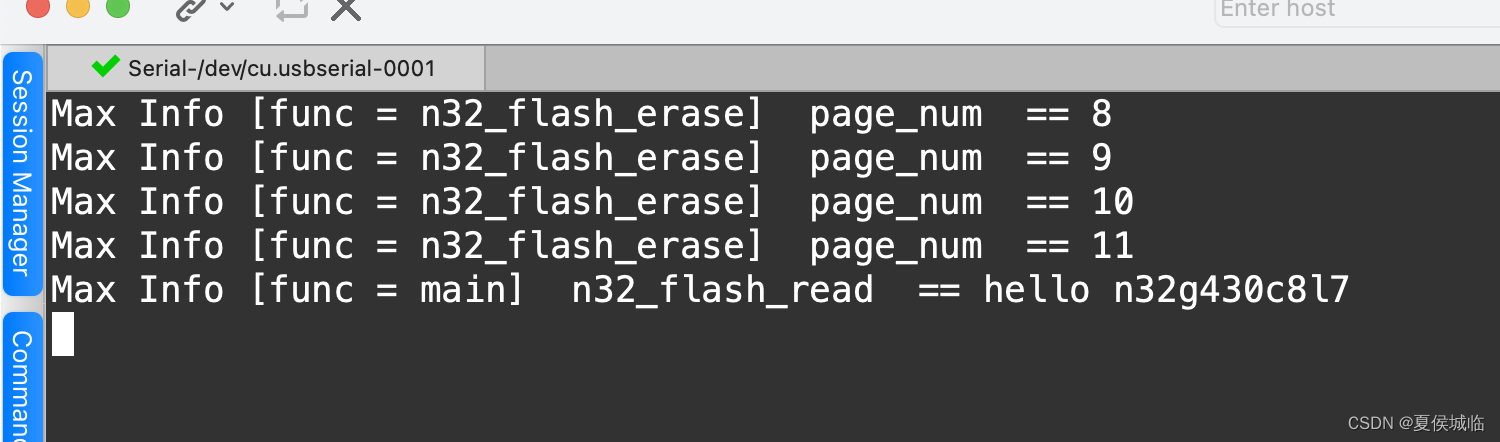
擦除4页8k大小,
读出我们写入的字符串。