文化传播网站建设wordpress首页显示摘要数字
400G光模块是目前高速传输领域中的一种先进产品,被广泛应用于高性能数据中心、通信网络、大规模计算、云计算等领域。本文将从400G光模块的定义、技术、产品型号、应用场景以及未来发展方向进行详细介绍。
一、什么是400G光模块?
400G光模块是指传输速率达到400Gbps的光模块产品。目前主流的封装类型是QSFP-DD(Quad Small Form-factor Pluggable Double Density),它是一种高速光模块接口规范,QSFP接口的升级版本,支持400G的高速传输。以光纤作为信号传输媒介,通过将数字信号转换成光信号,在光纤中传输。

二、400G光模块技术
400G光模块的技术主要包括PAM4调制技术、COB封装技术、DSP数字信号处理技术、微波集成电路技术、高速电接口技术等。
PAM4调制技术是400G光模块实现高速传输的核心技术,它采用4级脉冲振幅调制方式,将传统的2进制数字信号调制扩展到4级,实现了400G的传输速率。
COB封装技术是一种新型的封装技术,它采用芯片直接焊接在基板上,不需要使用封装外壳,可以实现更高的信号传输速率和更小的体积。
DSP数字信号处理技术是400G光模块中用来实现信号处理和解码的技术,它可以对光信号进行调制、解调和误码纠正等操作,提高光模块的传输速率和信号质量。
微波集成电路技术是一种高频电路设计技术,可以将多个电路集成在一个芯片上,实现高速、低功耗、小尺寸的高频电路设计。
高速电接口技术是400G光模块与外界设备连接的技术,它包括各种不同的接口类型,例如QSFP-DD、OSFP等,用来实现不同设备之间的连接和数据传输。
三、400G光模块的产品型号分类
根据不同的规格和接口类型,400G光模块的产品型号分类主要包括SR8、DR4、FR4、LR4、LR8和ER4等几种类型。
其中,SR8适用于短距离数据传输,DR4适用于中距离数据传输,FR4适用于长距离数据传输,LR4适用于超长距离数据传输,LR8适用于更长距离的数据传输,而ER4则适用于极长距离数据传输。
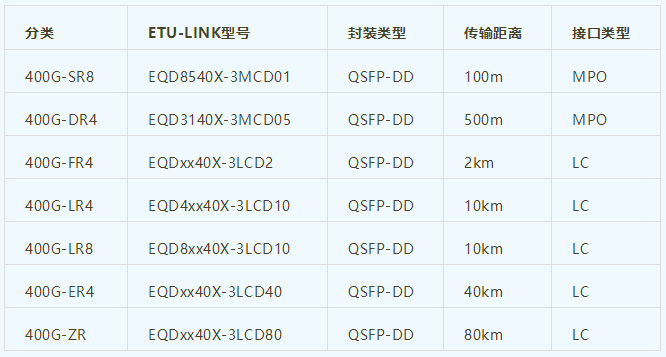
以上是目前市场上比较常见的400G光模块产品型号,随着技术的不断发展,未来可能还会涌现出更多新的型号。
四、400G光模块的应用场景
400G光模块适用于运营商的宽带接入、宽带网络、数据中心互联、云计算等领域。在数据中心方面,随着云计算和大数据技术的发展,对于数据中心的可扩展性、可靠性和低延迟性等要求越来越高,400G光模块能够满足这些要求。此外,400G光模块也适用于高速传输和长距离传输等场景。
五、400G光模块的未来发展方向
随着数据中心、企业网络和电信运营商的需求不断增加,400G光模块市场将持续增长。随着技术的不断进步,400G光模块的成本将不断下降,同时性能也将不断提高。在未来,400G光模块的应用场景将进一步扩大,包括物联网、5G等领域。
六、易天光模块厂家
易天光通信(ETU-LINK)是一家专业生产光模块的厂家,公司拥有自己的研发团队和生产基地,能够提供高质量、高性能的光模块产品,包括400G光模块、100G光模块、40G光模块等。公司已经通过了多项国际认证,包括ISO9001、CE、FCC、ROHS等,产品远销全球,深受客户的信赖。
结语: 400G光模块是未来网络发展的趋势,易天光通信ETU-LINK致力于为客户提供高质量、高性能的光模块产品,让客户可以更好地应对不断变化的市场需求。希望本文能够为读者提供一些有价值的信息,让大家对于400G光模块有更深入的了解。