jsp做门户网站海报设计兼职app
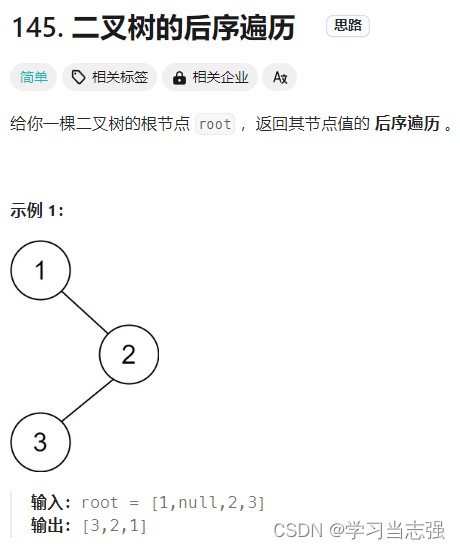
// 定义一个名为Solution的类,用于解决二叉树的后序遍历问题
class Solution { // 定义一个公共方法,输入是一个二叉树的根节点,返回一个包含后序遍历结果的整数列表 public List<Integer> postorderTraversal(TreeNode root) { // 创建一个空的整数列表,用于存储后序遍历的结果 List<Integer> res = new ArrayList<>(); // 调用私有方法postorder进行后序遍历,并将结果存储在res列表中 postorder(root, res); // 返回存储了后序遍历结果的列表 return res; } // 定义一个私有方法,输入是一个二叉树的根节点和一个用于存储结果的列表 // 该方法用于执行实际的后序遍历 void postorder(TreeNode root, List<Integer> list) { // 如果当前节点为空,则直接返回,不进行任何操作 if (root == null) { return; } // 递归地对左子树执行后序遍历 postorder(root.left, list); // 递归地对右子树执行后序遍历 postorder(root.right, list); // 在遍历完左右子树后,将当前节点的值添加到结果列表中 list.add(root.val); // 注意这一句,它确保了在遍历完左右子节点后,根节点的值才会被添加到结果列表中 }
}
在这段代码中,TreeNode 是一个自定义的二叉树节点类,它至少包含三个成员:val(节点的值),left(指向左子节点的引用),和 right(指向右子节点的引用)。
postorderTraversal 方法是公共接口,它接收一个二叉树的根节点作为参数,并返回一个包含后序遍历结果的整数列表。这个方法首先创建一个空的列表 res,然后调用私有方法 postorder 来执行实际的后序遍历,并将结果添加到 res 中。最后,它返回这个列表。
postorder 方法是一个私有递归方法,它接收一个节点和一个列表作为参数。如果节点为空,则方法直接返回。否则,它首先递归地对其左子树执行后序遍历,然后对其右子树执行后序遍历,最后将当前节点的值添加到列表中。这个过程确保了后序遍历的顺序(左-右-根)被正确地遵守。