做爰视频网站网站安全建设思考
分析原因
众所周知,在JavaScript中计算两个十进制数的和,有时候会出现令人惊讶的结果,主要原因是计算机将数据存储为二进制所引起的,所以这并不是javascript存在的缺陷,而在其他语言中也有类似的问题。
例如下面的例子:
我们在计算 0.1 + 0.1 的到的结果是 0.2,但是计算 0.1 + 0.2 的结果并不是0.3,而是0.30000000000000004
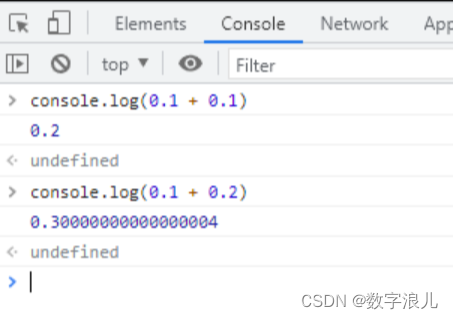
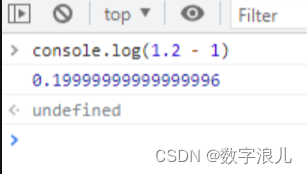
我们在计算 1.2 - 1 的结果并不是0.2,而是0.19999999999999996
不过这并不是JavaScript独有的,其他编程语言也会存在同样的问题。
解决办法:我们可以使用toPrecision凑整后再使用parentFloat,比如计算1.6385000000000001
let parse = parseFloat(1.6385000000000001.toPrecision(12))
console.log(parse === 1.6385) // true
接下来我们封装成方法使用
/**@param: 浮点小数@precise: 转换后有几位数
*/
function precision(num, precise) {return parseFloat(num.toPrecision(precise));
}precision(1.6385000000000001, 1) // 2
precision(1.6385000000000001, 2) // 1.6
precision(1.6385000000000001, 3) // 1.64
其原理就相当一数学中的四舍五入。