网站建设横幅标语seo营销型网站推广
前言: 大家对StarRocks 的了解可能不及 ClickHouse或者是远不及 ClickHouse 。但是大家可能听说过 Doris ,而 StarRocks 实际上原名叫做 Doris DB ,他相当于是一个加强版的也就是一个 Doris+ ,也就是说 Doris 所有的功能 StarRocks 都是有的,但是 StarRocks 有的这种加速的功能 Doris 目前是没有的。我们可以基于 Apache Doris 统一 OLAP 技术栈,满足庞大数据体量下的实时分析与极速查询。
1、什么是StarRocks?
StarRocks原名DorisDB,StarRocks 是 Apache Doris 的 Fork 版本。StarRocks 是新一代极速全场景 MPP (Massively Parallel Processing) 数据库。StarRocks 是一款高性能分析型数据仓库,使用向量化、MPP 架构、CBO、智能物化视图、可实时更新的列式存储引擎等技术实现多维、实时、高并发的数据分析。StarRocks 既支持从各类实时和离线的数据源高效导入数据,也支持直接分析数据湖上各种格式的数据。StarRocks 兼容 MySQL 协议,可使用 MySQL 客户端和常用 BI 工具对接。同时 StarRocks 具备水平扩展,高可用、高可靠、易运维等特性。广泛应用于实时数仓、OLAP 报表、数据湖分析等场景。
StarRocks 架构简洁,采用了全面向量化引擎,并配备全新设计的 CBO (Cost Based Optimizer) 优化器,查询速度(尤其是多表关联查询)远超同类产品。
-
StarRocks 能很好地支持实时数据分析,并能实现对实时更新数据的高效查询。StarRocks 还支持现代化物化视图,进一步加速查询。
-
多分布式 Join极速引擎,这个分布式 Join 目前就是 ClickHouse 比较缺乏的一个功能。如果了解 spark 或者了解 presto 的话,其实都应该知道这都是有的,就是说这个其实就是做 Shuffle ,就是把不同的 Key 给 Shuffle 到同一个 bucket 里边,然后再去做 Join ,然后右边实际上是一个更加高效的一种 Join 方式也就是提前的去做好了这个 bucket 的分类,也就是说同一个 Key,两张表相同的 Key ,全部落到同一个 bucket 的范围,然后这个 bucket 的之间肯定是没有 over lap ,所以可以放心的做这个Colocate joy ,在这个 spark 里面也叫 bucket join 。
-
使用 StarRocks,用户可以灵活构建包括大宽表、星型模型、雪花模型在内的各类模型。
-
StarRocks 兼容 MySQL 协议,支持标准 SQL 语法,易于对接使用,全系统无外部依赖,高可用,易于运维管理。StarRocks 还兼容多种主流 BI 产品,包括 Tableau、Power BI、FineBI 和 Smartbi。
2、使用Doris替换ClickHouse、Kylin和Druid
这里有一家电子商务SaaS提供商,其数据系统提供实时和离线报告、客户分割和日志分析服务。最初,他们为这些不同的目的使用了不同的OLAP引擎:
-
Apache Kylin用于离线报告:该系统为超过500万个卖家提供离线报告服务。其中的大型卖家拥有超过1000万注册会员和100,000个SKU,详细信息放在平台上的400多个数据立方体中。
-
ClickHouse用于客户分割和Top-N日志查询:这需要高频更新、高QPS和复杂的SQL。
-
Apache Druid用于实时报告:卖家通过组合不同的维度提取所需的数据,这种实时报告需要快速的数据更新、快速的查询响应和系统的强大稳定性。
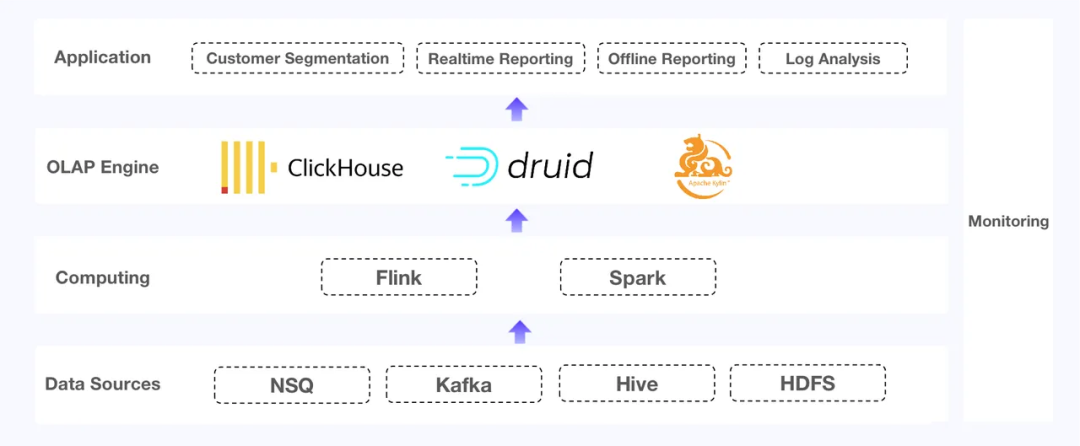
这三个组件都有各自的痛点:
-
Apache Kylin在固定表模式下运行良好,但每次添加维度时,需要创建一个新的数据立方体并在其中重新填充历史数据。
-
ClickHouse不适用于多表join处理,因此需要额外的解决方案来进行联合查询和多表连接查询。在高并发场景下,它的表现低于预期。
-
Apache Druid实现了幂等写入,因此它本身不支持数据更新或删除。这意味着当上游出现问题时,需要进行完整的数据替换。如果您从头到尾考虑所有数据备份和移动,这样的数据修复是一个多步骤的过程。此外,新摄入的数据在放入Druid中的段之前将无法用于查询。这意味着存在更长的时间窗口,从而导致上下游之间的数据不一致。
由于它们共同工作,这种架构可能太难以维护,因为它需要在开发、监控和维护方面了解所有这些组件。此外,每次用户扩展集群时,他们必须停止当前集群并迁移所有数据库和表,这不仅是一个巨大的任务,而且会对业务造成巨大的干扰。基于上述架构痛点,友赞对市面上的架构进行了调研与选型,希望选择一款能够简化当前复杂架构、统一 OLAP 技术栈的引擎。他们除了分析 OLAP 性能本身对于业务的帮助,还需要评估架构改造所带来的收益成本比,思考架构进行迁移和重构之后所带来的 ROI 是否符合预期。
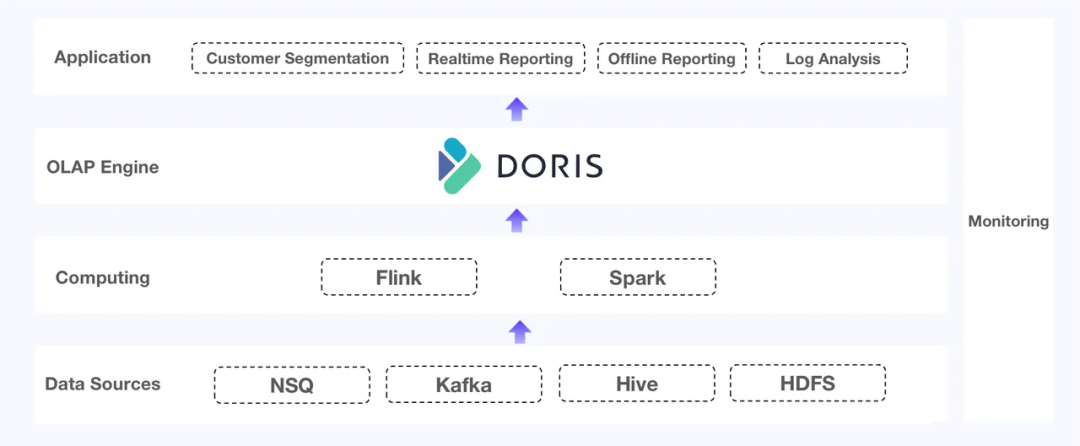
Apache Doris填补了这些空白。
-
查询性能:Doris擅长高并发查询和JOIN连接查询,并且现在配备了倒排索引以加速日志搜索。
-
数据更新:Doris的唯一键模型支持大容量更新和高频实时写入,而重复键模型和唯一键模型支持部分列更新。它还提供数据写入的恰好一次保证,并确保基表、物化视图和副本之间的一致性。
-
维护:Doris与MySQL兼容。它支持轻松扩展和轻量级模式更改。它配备了自己的集成工具,如Flink-Doris-Connector和Spark-Doris-Connector。

3、 StarRocks和ClickHouse压测性能对比
这里比较了两个组件在SQL和连接查询方案上的性能,并计算了Apache Doris的CPU和内存消耗。
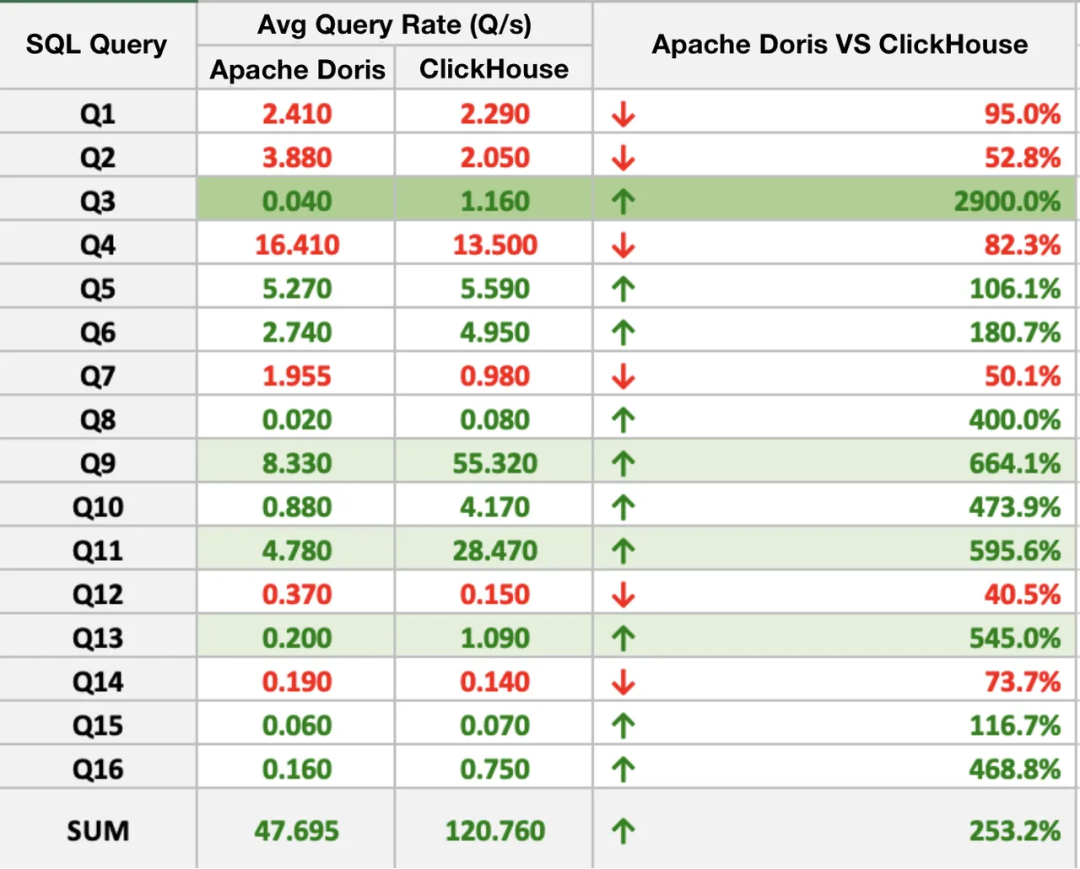
2.1 SQL查询性能
Apache Doris在16个SQL查询中的10个中表现优于ClickHouse,最大的性能差距比例接近30。总体而言,Apache Doris比ClickHouse快2~3倍。
2.2 连接查询性能
对于连接查询测试,使用了不同大小的主表和维表。
-
主表:用户活动表(40亿行)、用户属性表(250亿行)和用户属性表(960亿行)
-
维表:100万行、1000万行、5000万行、1亿行、5亿行、10亿行和25亿行。
测试包括完全连接查询和过滤连接查询。完全连接查询连接主表和维表的所有行,而过滤连接查询使用WHERE过滤器检索特定卖家ID的数据。结果如下:
主表(40亿行):
-
完全连接查询:Doris在所有维表的完全连接查询中均优于ClickHouse。随着维表变大,性能差距越来越大。最大的差距比例接近5。
-
过滤连接查询:基于卖家ID,过滤器从主表中筛选出了4100万行。对于小型维表,Doris比ClickHouse快2~3倍;对于大型维表,Doris比ClickHouse快10倍以上;对于大于1亿行的维表,ClickHouse会抛出OOM错误,而Doris则正常运行。
主表(250亿行):
-
完全连接查询:Doris在所有维表的完全连接查询中均优于ClickHouse。ClickHouse在维表大于5000万行时会产生OOM错误。
-
过滤连接查询:过滤器从主表中筛选出了5.7亿行。Doris在几秒钟内响应,而ClickHouse在连接大型维表时完成时间为几分钟,并在此过程中崩溃。
主表(960亿行):
Doris在所有查询中都表现出相对较快的性能,而ClickHouse无法执行所有查询。
在CPU和内存消耗方面,Apache Doris在所有大小的连接查询中都保持稳定的集群负载。
参考链接:
从 Clickhouse 到 Apache Doris:有赞业务场景下性能测试与迁移验证
开源大数据 OLAP 引擎最佳实践 | 学习笔记(二)-阿里云开发者社区