网站信息同步福田祥菱m1图片及报价
一 redis单线程与多线程
1.1 redis单线程&多线程
1.redis的单线程
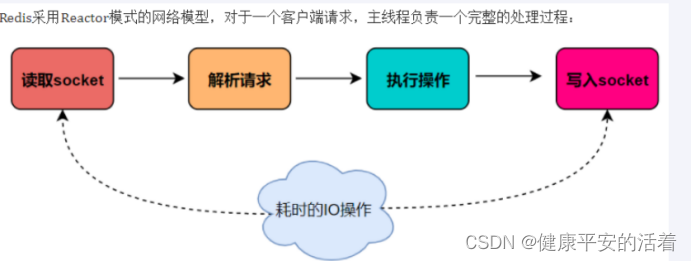
redis单线程主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取 (socket 读)、解析、执行、内容返回 (socket 写) 等都由一个顺序串行的主线程处理,这就是所谓的“单线程”。这也是Redis对外提供键值存储服务的主要流程。
但Redis的其他功能,比如持久化RDB、AOF、异步删除、集群数据同步等等,其实是由额外的线程执行的。
2.redis的多线程
从redis6.x开始采用io多路复用,让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Socket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。
也就是说就新增了多线程的功能来提高 I/O 的读写性能,使多个 socket 的读写可以并行化。
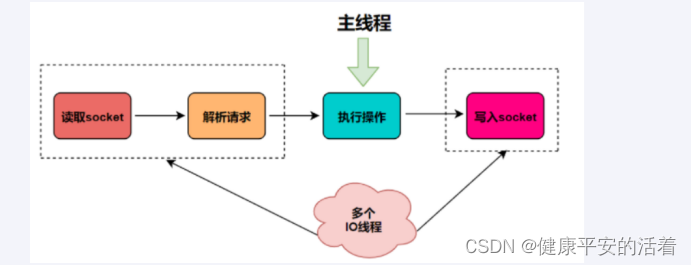
结果如下:

1.2 redis为何执行速度快
1.基于内存;2.简单的数据结构;3.基于io多路复用;4.避免上下文切换
使用一个线程来处理多个客户端请求,减少线程上下文切换带来的开销,同时避免了I/O阻塞操作。
主要原因是:IO多路复用+epoll函数使用,才是redis为什么这么快的直接原因,而不是仅仅单线程命令+redis安装在内存中。
1.3 redis单线程存在问题
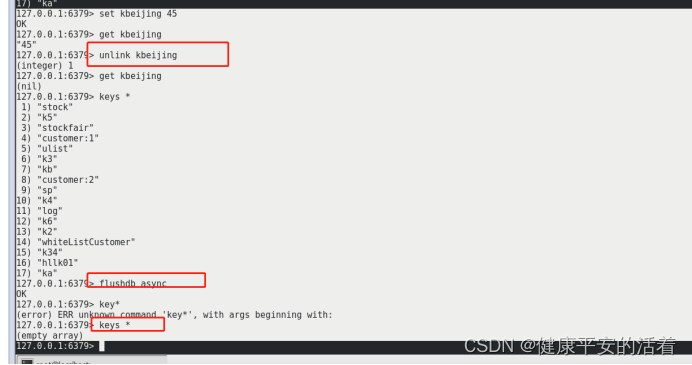
删除大key时,出现阻塞卡顿问题,针对此问题引入了多线程的异步惰性删除。
命令如下:
Unlink key
Flushdb async
Flushdb async
把删除工作交给二类后台的小弟异步来删除数据。
操作案例:
1.4 IO多路复用
1.4.1 IO多路复用
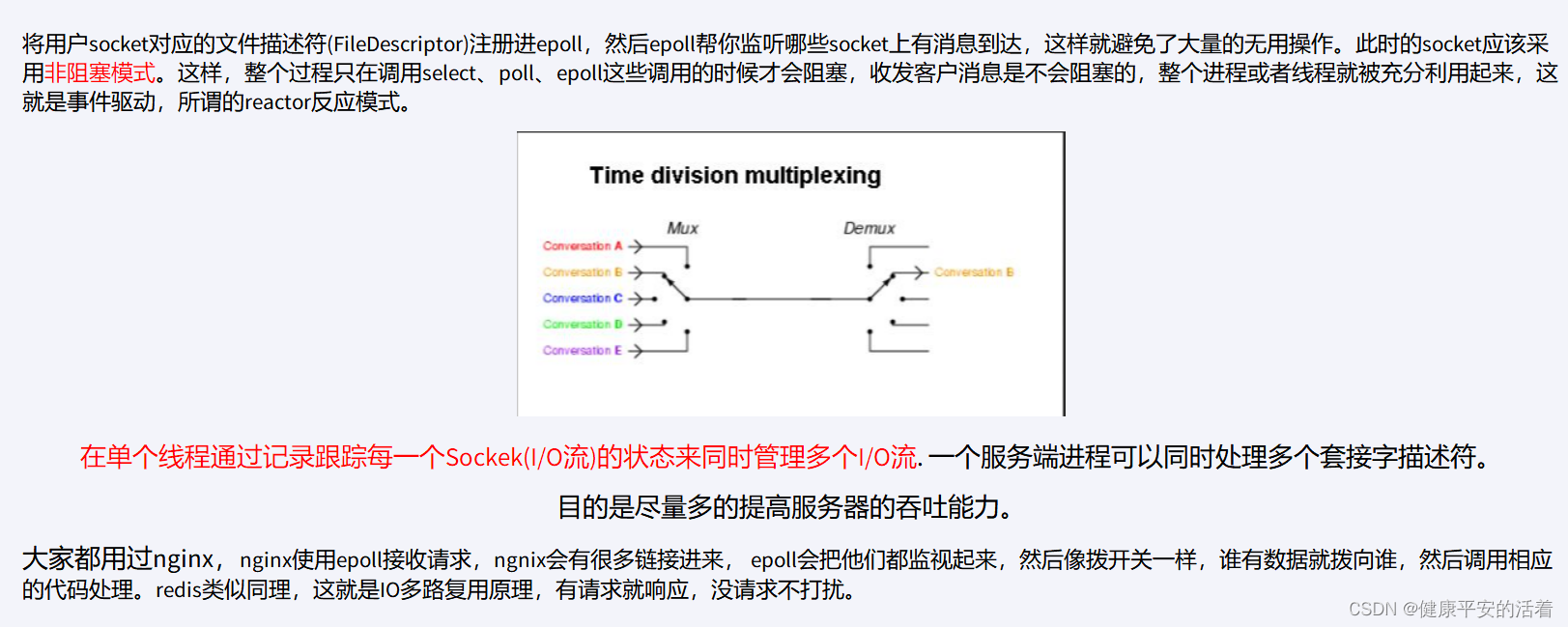
一种同步的IO模型,实现一个线程监视多个文件句柄,一旦某个文件句柄就绪就能够通知到对应应用程序进行相应的读写操作,没有文件句柄就绪时,就会阻塞应用程序,从而释放cpu资源。一个专家大夫和多个病人之间的关系。
IO:网络IO,在操作系统层面指的是内核态和用户态之间读写操作
多路:多个客户端连接。
复用:复用一个或者几个线程。
Io多路复用:单个进程能够实现处理多个客户端的连接请求。或者一个服务进程能够可以同时处理多个套接字描述符。
实现io多路复用有3种模型: select-》pll-》epoll这个阶段
1.4.2 IO多路复用的优点

1.5 redis4.0之前采用单线程原因
1.使用单线程模型是redis开发和维护更加简单。
2.使用是IO多路复用和非阻塞模型。
3.对于redis来说,主要的系统瓶颈是内存或者网络并发cpu。
1.6 redis的多线程开启
默认情况下,redis的多线程功能是没有开启的,需要进行配置
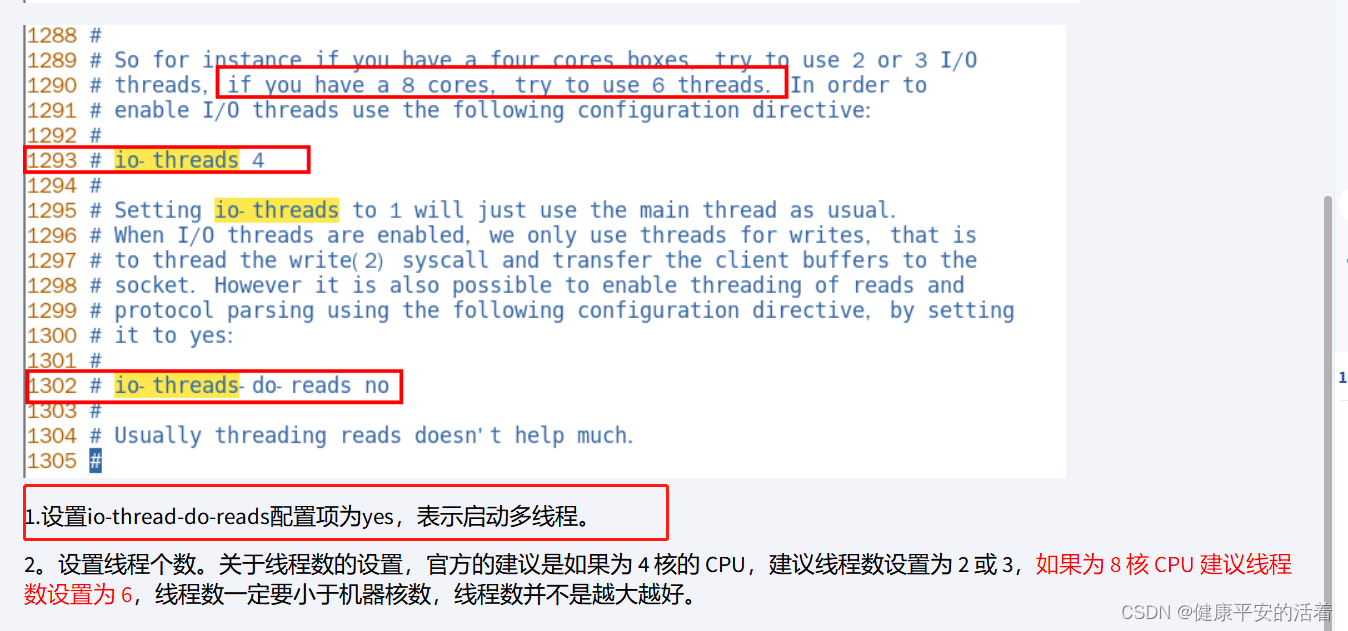
1.7 redis单线程&多线程总结
1.redis6.x之前网络IO读写和命令执行都是有一个主线程进行操作完成;但是单线程存在删除del key存储卡顿阻塞问题,redis6.x之后使用IO多路复用技术,一个线程处理多个客户端请求,网络IO的读写,解析部分使用多线程,而命令执行部分仍使用一个主线程执行,这样提供了查询效率,同时解决了删除del key卡顿问题。
2.redis基于Io多路复用和epoll函数,减少上下文切换,同时基于内存和数据结构简单 这些是redis查询块的原因
3.io多路复用:单个进程能够实现处理多个客户端的连接请求。