深圳视频网站开发网站建设金硕网络
目录
第一题
C++代码示例
第二题
C++代码示例
第三题
3.1 使用std::integral_constant模板类
3.2 使用std::conditional结合std::is_same判断
总结
第四题
C++代码示例
第五题
C++代码示例
第六题
C++代码示例
第七题
C++代码示例
总结
第一题
对于元函数来说,数值与类型其实并没有特别明显的差异:元函数的输入可以是数值或类型,对应的变换可以在数值与类型之间进行。比如可以构造一个元函数,输入是一个类型,输出是该类型变量所占空间的大小---------这就是一个典型的从类型变换为数值的元函数。尝试构造该函数,并测试是否能行。
C++代码示例
#include <iostream>
#include <type_traits>template <typename T>
struct TypeSize {static constexpr size_t value = sizeof(T);
};int main() {std::cout << TypeSize<int>::value << std::endl; // 输出:4(int 类型在大多数平台上占用4个字节)std::cout << TypeSize<double>::value << std::endl; // 输出:8(double 类型在大多数平台上占用8个字节)std::cout << TypeSize<char>::value << std::endl; // 输出:1(char 类型在大多数平台上占用1个字节)return 0;
}输出结果:

代码详解:
在上面的代码中,我们定义了一个名为TypeSize的模板结构体,它有一个静态成员变量value,其默认值是sizeof(T),其中T是TypeSize的模板参数类型。通过sizeof运算符,我们可以在编译时获取类型T的大小,并将其保存在value中。
在main函数中,我们分别测试了int、double和char类型的大小,并使用std::cout输出结果。可以看到,对于每个类型,我们都成功地获取了其在内存中所占空间的大小。
第二题
作为进一步的扩展,元函数的输入参数甚至可以是类型与数值混合的。尝试构造一个元函数,其输入参数为一个类型以及一个整数。如果该类型所对应对象的大小等与该整数,那么返回true,否则返回false。
C++代码示例
#include <iostream>
#include <type_traits>template <typename T, size_t N>
struct CheckSize {static constexpr bool value = sizeof(T) == N;
};int main() {std::cout << std::boolalpha;std::cout << CheckSize<int, 4>::value << std::endl; // 输出:true(int 类型在大多数平台上占用4个字节)std::cout << CheckSize<double, 8>::value << std::endl; // 输出:true(double 类型在大多数平台上占用8个字节)std::cout << CheckSize<char, 2>::value << std::endl; // 输出:false(char 类型在大多数平台上占用1个字节)return 0;
}输出结果:

代码详解:
我们使用了一个元函数 CheckSize ,结构体 CheckSize 接受两个模板参数:类型 T 和大小 N。在元函数中,我们使用 sizeof 运算符计算类型 T 的大小,并将其与整数 N 进行比较。如果相等,则元函数的静态成员变量 value 设置为 true,否则设置为 false。
第三题
3.1 使用std::integral_constant模板类
#include <iostream>
#include <type_traits>template <typename T, size_t N>
struct CheckSize : std::integral_constant<bool, sizeof(T) == N> {};int main() {std::cout << std::boolalpha;std::cout << CheckSize<int, 4>::value << std::endl; // 输出:true(int 类型在大多数平台上占用4个字节)std::cout << CheckSize<double, 8>::value << std::endl; // 输出:true(double 类型在大多数平台上占用8个字节)std::cout << CheckSize<char, 2>::value << std::endl; // 输出:false(char 类型在大多数平台上占用1个字节)return 0;
}使用std::integral_constant模板类来实现元函数CheckSize。CheckSize结构体继承自std::integral_constant,并提供两个模板参数:bool类型表示返回类型,以及sizeof(T) == N作为值。通过继承自std::integral_constant,我们可以从CheckSize<T, N>直接访问value成员变量。
3.2 使用std::conditional结合std::is_same判断
#include <iostream>
#include <type_traits>template<typename T, size_t N>
struct CheckSize {static constexpr bool value = std::is_same_v<sizeof(T), N>;
};int main() {std::cout << std::boolalpha;std::cout << CheckSize<int, 4>::value << std::endl; // 输出:true(int 类型在大多数平台上占用4个字节)std::cout << CheckSize<double, 8>::value << std::endl; // 输出:true(double 类型在大多数平台上占用8个字节)std::cout << CheckSize<char, 2>::value << std::endl; // 输出:false(char 类型在大多数平台上占用1个字节)return 0;
}使用了std::conditional结合std::is_same检查类型大小。std::is_same_v是一个用于判断两个类型是否相同的模板,sizeof(T)表示类型 T 的大小,在此和 N 进行比较。如果两者相同,则value被设置为 true,否则被设置为 false。
总结
这些是更特殊或不太常见的元函数表示形式,这些形式可能适用于某些特定的使用场景或要求。
第四题
本章讨论了以类模板作为元函数的输出,尝试构造一个元函数,它接收输入后会返回一个元函数,后者接收输入后会再返回一个元函数------这仅仅是一个联系,不必过于在意其应用场景
C++代码示例
#include <iostream>
#include <functional>template <typename Input>
struct FirstLayer {template <typename Func>struct SecondLayer {template <typename... Args>constexpr auto operator()(Args&&... args) const {return Func{}(std::forward<Args>(args)...);}};template <typename Func>constexpr auto operator()(Func) const {return SecondLayer<Func>{};}
};struct MyFunction {template <typename... Args>constexpr auto operator()(Args&&... args) const {return sizeof...(Args);}
};int main() {FirstLayer<int> first;auto second = first(MyFunction{});std::cout << second(1, 2, 3, 4, 5) << std::endl; // 输出:5(返回传入参数的数量)return 0;
}输出结果:
![]()
代码详解:
示例中,FirstLayer 是一个元函数,它接收一个输入类型 Input。FirstLayer 结构体中定义了一个内部模板结构体 SecondLayer,它接收一个元函数类型 Func。SecondLayer 结构体中定义了一个函数调用运算符 operator(),它接收任意参数 Args...,并通过调用 Func 来实现对元函数的调用。
FirstLayer 还定义了一个函数调用运算符 operator(),它接收一个元函数类型 Func,并返回一个 SecondLayer<Func> 对象,即返回一个闭包(closure)元函数。
在 main() 函数中,我们先创建一个 FirstLayer<int> 对象 first。然后,我们通过调用 first(MyFunction{}) 来传递一个 MyFunction 元函数对象,得到一个 SecondLayer 对象 second。最后,我们通过调用 second 来调用传入的 MyFunction 元函数,并传递参数 1, 2, 3, 4, 5。
运行示例代码后,将输出 5,表示传入的参数数量为 5。
这个示例就是一个接收输入并返回元函数的元函数的实现。当 FirstLayer 元函数接收一个输入类型后,它返回一个闭包元函数 SecondLayer。你可以继续调用 SecondLayer 元函数,并传递其他的元函数来实现更多的函数组合和操作。
第五题
使用SFINAE构造一个元函数:输入一个类型T,当T存在子类型type时该元函数返回true,否则返回false。
C++代码示例
#include <iostream>
#include <type_traits>template <typename T>
struct HasType {// 检查 SFINAE 的辅助函数template <typename U>static std::true_type test(typename U::type*);template <typename U>static std::false_type test(...);static constexpr bool value = decltype(test<T>(nullptr))::value;
};// 测试用例
struct A {using type = int;
};struct B {};int main() {std::cout << std::boolalpha;std::cout << HasType<A>::value << std::endl; // 输出:true(A 类型存在名为 type 的子类型)std::cout << HasType<B>::value << std::endl; // 输出:false(B 类型不存在名为 type 的子类型)return 0;
}输出结果:

代码详解:
示例中,HasType 是一个元函数,用于检查类型 T 是否具有名为 type 的子类型。我们先定义了两个辅助函数 test,一个接收具有 type 子类型的输入类型 U(使用 typename U::type* 作为函数参数),另一个使用 ... 表示可变参的占位符。在 HasType 元函数中,test<T>(nullptr) 这一表达式启用了 SFINAE 机制,如果传递的类型具有名为 type 的子类型,则会选择第一个辅助函数进行调用,否则会选择第二个辅助函数。使用 decltype 和 std::true_type、std::false_type 来从辅助函数的返回类型中提取布尔值。
在测试用例中,我们分别检查了类型 A 和类型 B。因为类型 A 存在名为 type 的子类型,所以 HasType<A>::value 的结果为 true。而类型 B 不存在名为 type 的子类型,所以 HasType<B>::value 的结果为 false。
第六题
使用在本章中学到的循环代码书写方式,编写一个元函数,输入一个类型数组,输出一个无符号整形数组,输出数组中的每个元素表示输入数组中相应类型变量的大小。
C++代码示例
#include <iostream>
#include <utility>
#include <array>template <typename... Types>
struct SizeOfArray;// 基本情况:处理空类型数组
template <>
struct SizeOfArray<> {using type = std::array<std::size_t, 0>;
};// 递归情况:处理非空类型数组
template <typename T, typename... Types>
struct SizeOfArray<T, Types...> {using type = std::array<std::size_t, sizeof...(Types)+1>;
};// 辅助函数,打印无符号整型数组
template <std::size_t N, std::size_t... Sizes>
void printSizes(const std::array<std::size_t, N>& sizes, std::index_sequence<Sizes...>) {((std::cout << sizes[Sizes] << ' '), ...);std::cout << std::endl;
}int main() {using MyTypes = std::tuple<int, double, bool, char>;using Sizes = typename SizeOfArray<int, double, bool, char>::type;Sizes sizes;sizes[0] = sizeof(int);sizes[1] = sizeof(double);sizes[2] = sizeof(bool);sizes[3] = sizeof(char);printSizes(sizes, std::make_index_sequence<sizes.size()>()); // 输出:4 8 1 1return 0;
}输出结果:
![]()
代码详解:
在这段代码中,我们定义了一个 SizeOfArray 结构体,用于计算类型数组的大小。它通过递归方式处理类型数组,当类型数组为空时,返回一个大小为 0 的 std::array,当类型数组非空时,返回一个大小为 sizeof...(Types)+1 的 std::array,其中 sizeof...(Types) 是类型数组的元素个数。
在 main 函数中,我们定义了一个类型数组 MyTypes,其中包含了 int、double、bool 和 char 类型。然后,我们使用 SizeOfArray 结构体计算 MyTypes 数组中各个类型的大小,并将它们存储在 Sizes 结构体中。
接下来,我们使用 sizeof 操作符获取每个类型的大小,并将它们存储在 sizes 数组中的相应位置。
最后,我们调用 printSizes 函数,打印 sizes 数组中的每个元素。这里使用了 std::make_index_sequence 来生成一个索引序列,使得我们可以使用折叠表达式在 printSizes 函数中依次访问 sizes 数组中的元素。
第七题
使用分支短路逻辑实现一个元函数,给定一个整数序列,判断其中是否存在值为1的元素。如果存在,就返回true,否则返回false
C++代码示例
#include <iostream>// 终止条件,判断最后一个元素是否等于 1
template <int Last>
bool hasOne() {return Last == 1;
}// 递归情况,判断当前元素是否等于 1,并继续判断后面的元素
template <int First, int Second, int... Rest>
bool hasOne() {return (First == 1) || hasOne<Second, Rest...>();
}int main() {bool result1 = hasOne<1, 2, 3, 4>(); // 序列中存在值为1的元素,返回truebool result2 = hasOne<2, 3, 4, 5>(); // 序列中不存在值为1的元素,返回falsestd::cout << "Result 1: " << std::boolalpha << result1 << std::endl;std::cout << "Result 2: " << std::boolalpha << result2 << std::endl;return 0;
}输出结果:
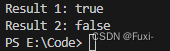
代码详解:
第一个版本是终止条件,用于判断最后一个元素是否等于1。在这个版本中,我们只有一个模板参数 Last,当 Last 等于 1 时,返回 true。
第二个版本是递归情况,用于判断当前元素是否等于1,并继续判断后面的元素。在这个版本中,我们有三个模板参数,分别代表当前元素 First、下一个元素 Second,以及剩余的元素 Rest...。在递归调用时,我们将 Second 作为新的 First,并继续判断后面的元素。
通过这段代码,我们可以正确判断整数序列中是否存在值为1的元素。
在 main 函数中,我们使用两个示例来测试 hasOne 元函数。第一个示例传入的序列为 <1, 2, 3, 4>,其中存在值为1的元素,因此返回 true。第二个示例传入的序列为 <2, 3, 4, 5>,其中不存在值为1的元素,因此返回 false。
总结
后续会开始陆续更新第二章,如果有需要博主讲解其他书也可以私信我!!!