怎样做好邯郸网站建设优对 网站开发
在应用spring 的过程中,就会涉及到bean的加载,bean的加载经历一个相当复杂的过程,bean的加载入口如下:
 使用getBean()方法进行加载Bean,最终调用的是AbstractBeanFactory.doGetBean() 进行Bean的加载。
使用getBean()方法进行加载Bean,最终调用的是AbstractBeanFactory.doGetBean() 进行Bean的加载。

doGetBean()源码如下:

从代码可看出Bean的加载过程可以分为一下几个步骤:
步骤一: 转换对应beanName
- 去除FactoryBean的修饰符,例如 name=“&aa”,则会先去除&成name=“aa”。调用BeanFactoryUtils.transformedBeanName(name) 方法进行去除"&",源代码如下:

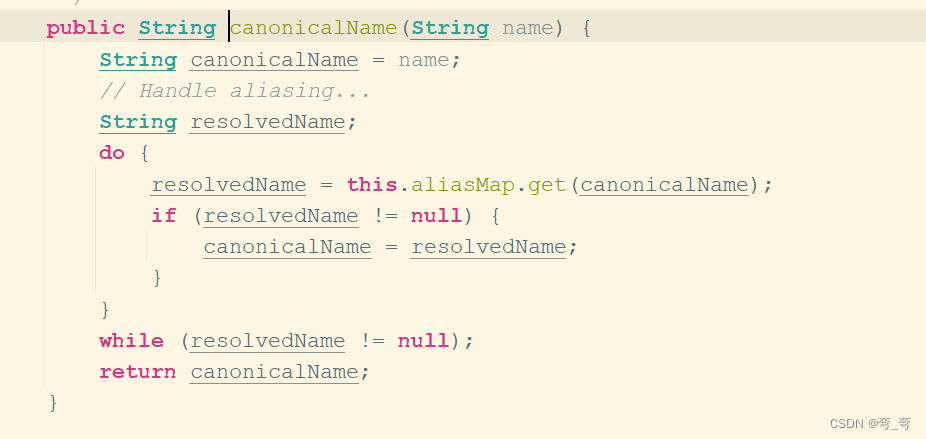
- 取指定alias 所表示的最终beanName,canonicalName()方法实现使用alias做最终的beanName,源码如下:
步骤二: 尝试从缓存中加载单例
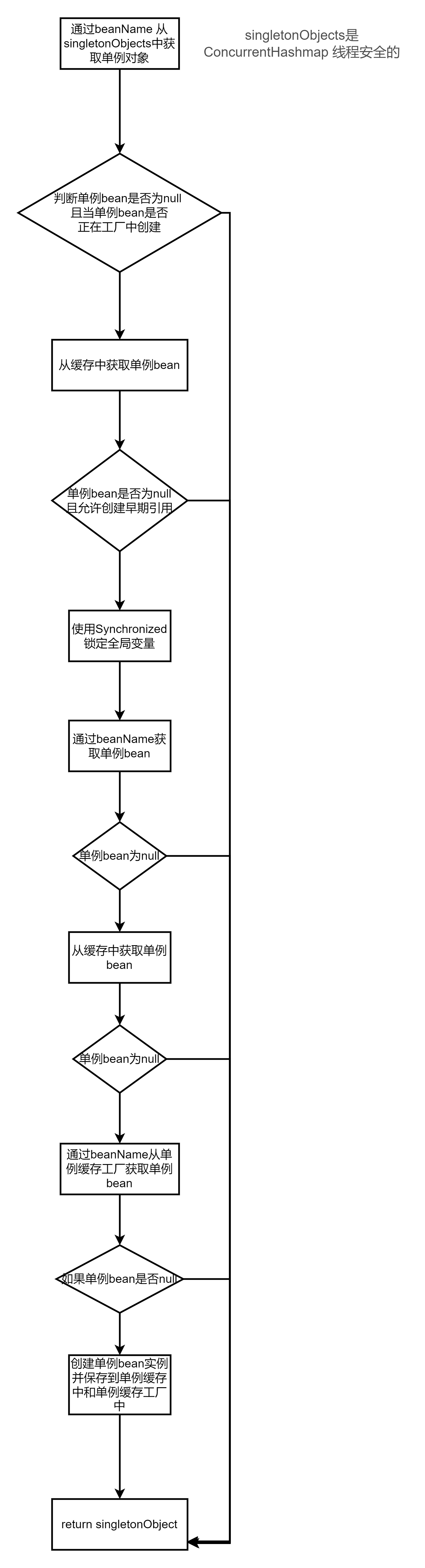
单例在Spring 的同一个容器内只会创建一次,后续在获取bean直接从单例缓存中获取,尝试从缓存中加载Bean,如果加载失败则再次尝试从SingletonFactories中加载.因为在创建单例bean的时候会存在依赖注入的情况,而在创建依赖的时候为了避免循环依赖,Spring 创建bean 的原则是不等bean创建完成就会将创建bean的ObjectFactory提早曝光加入到缓存中,当下一个bean创建时需要依赖上个bean,则直接使用ObjectFactory.尝试从缓存中加载单例由重载的getSingleton()方法进行实现,源码如下

重载的getSingle()方法设计循环依赖的检测,以及多处变量的记录存取,此方法首先尝试从singletonObject 中获取实例,如果获取不到再从earlySingletoObjects里面获取,如果还获取不到,再尝试从singletonFactories 里面获取beanName对应的ObjectFactory,然后调用ObjectFactory.getObject() 来创建bean,并放到earlySingletonObjects里面去,并且从singletonFactories 中移除ObjectFactory.源代码如下:

尝试获取单例bean的流程如下:
步骤三:bean的实例化
如果从缓存职工得到了bean的原始状态,则需要对bean进行实例化,调用getObjectForBeanInstance()方法检测当前bean是否是FactoryBean类型的bean,如果是,那么需要调用该bean对应的FactoryBean实例中的getObject()作为返回值,具体代码实现实现如下,

从代码中可以得知,getObjectForBeanInstance()做得更多的是功能性的判断,核心代码委托给getObjectFromFactoryBean()来实现了,而 getObjectForBeanInstance( )主要是完成一下几项工作:
第一: 对FactoryBean正确性的验证;
第二:对非FactoryBean不做任何处理;
第三:对bean进行转换;
第四:将从Factory中解析bean的工作委托给getObjectFromFactoryBean();
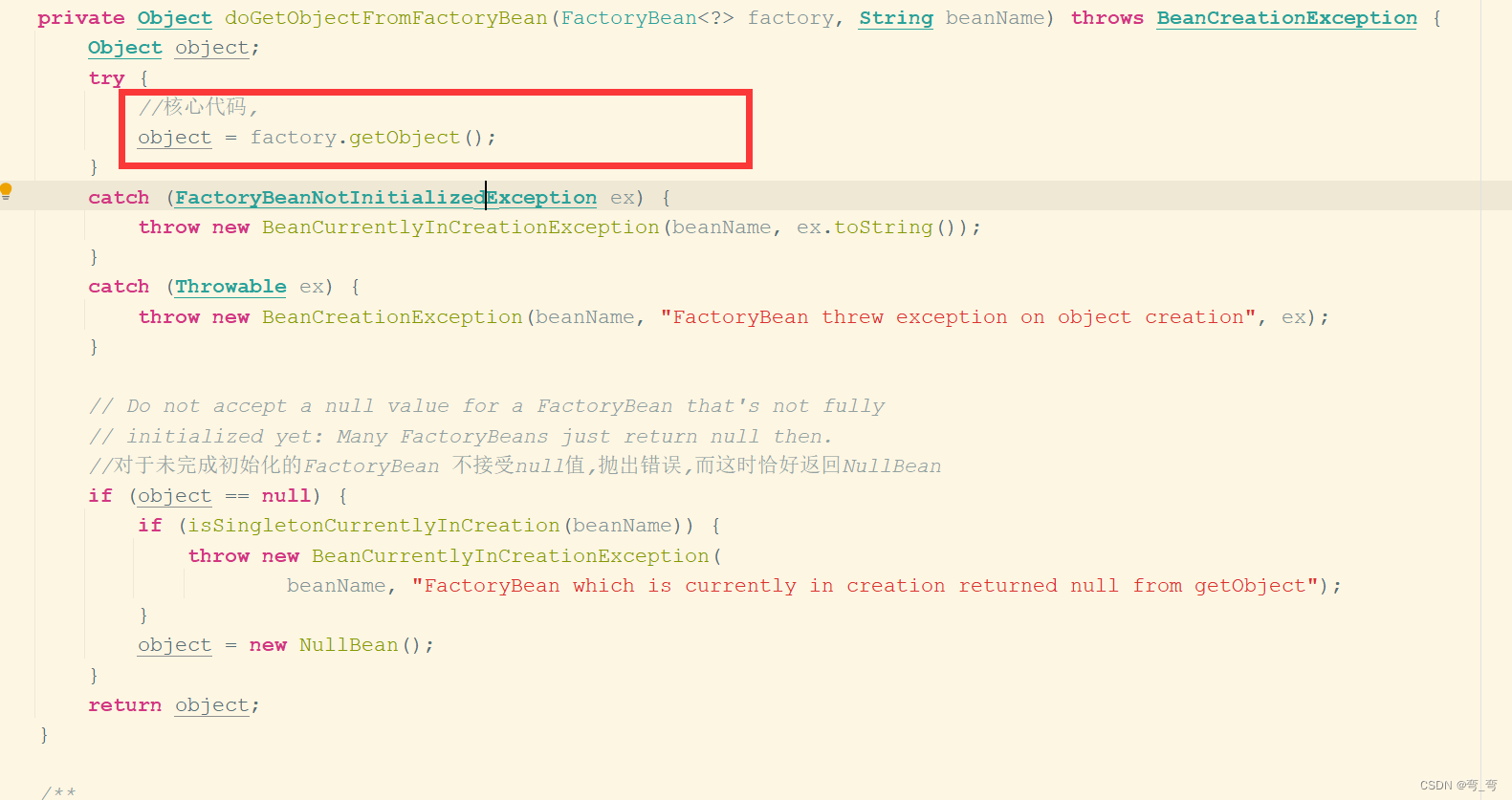
getObjectFromFactoryBean() 的作用是若 返回的bean是单例的就必须保证全局唯一, 正因使用了单例,使用功能缓存来提高性能.源代码如下:

在此方法中并没有看到核心代码 object = factory.getObject();, 而是再次调用了doGetObjectFromFactoryBean() 判断bean是否是FactoryBean类型,若是FactoryBean类型则当提取bean 时提取的并不是FactoryBean ,而是Factorybean中对应的getObject方法返回bean,doGetObjectFromFactoryBean()源代码如下:
步骤四:原型模式的依赖检查
只有在单例情况下才会尝试解决循环依赖,如果存在A中有B 的属性, B 中有A 的属性,
那么当依赖注入的时候,就会产生当A 还未创建完的时候因为对于B 的创建再次返回创建A,
造成循环依赖.

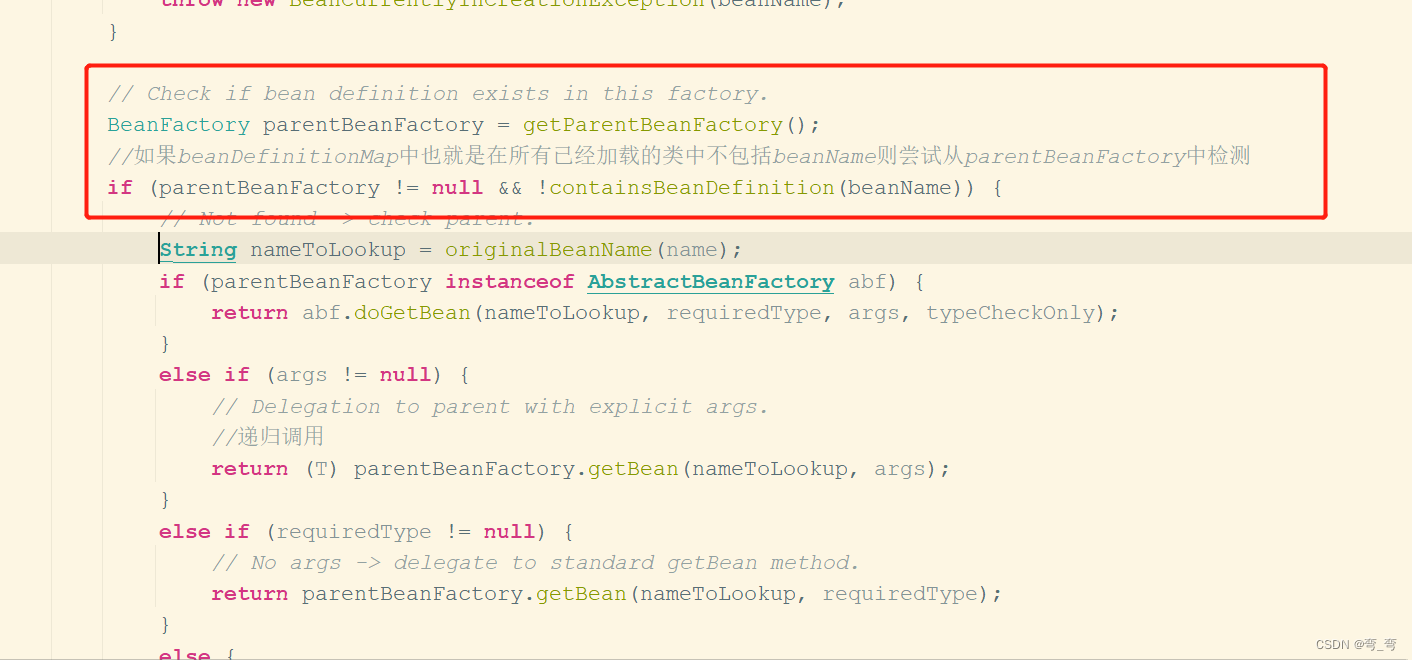
步骤五: 检测parentBeanFactory
检测如果当前加载的XML 配置文件中不包含beanName所对应的配置,就只能到parentBeanFactory 去尝试下了,然后再去递归的调用getBean方法。判断语句为:
步骤六:将存储XML配置文件的GernericBeanDefinition转换为RootBeanDefinition。
转换的原因是从XML配置文件中读取到的bean信息是存储在GernericBeanDefinition中的,而bean后续的处理是针对RootBeanDefinition的, 在转换的过程中,如果父类bean不为空的话,也会一并合并父类属性、

方法源码简单,可自行查看,
步骤七: 寻找依赖
在Sring 的加载过程中,在初始化某一个bean的时候首先会初始化这个bean所对应的依赖。

步骤八:针对不同的scope进行bean的创建
在spring中存在着不同的scope,其中默认值是singleton,Spring 会根据不同的配置进行不同的初始化策略。
