iis添加网站主机名西宁建设网站
1. js入门
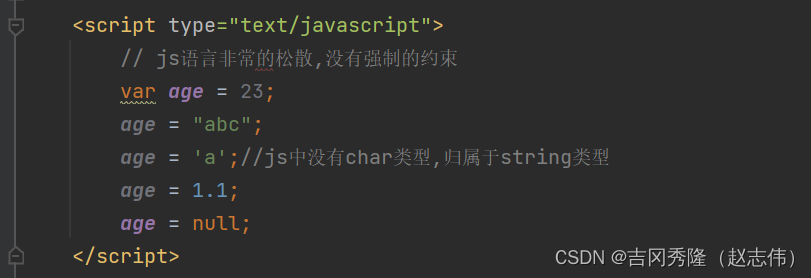
1.1 js是弱类型语言
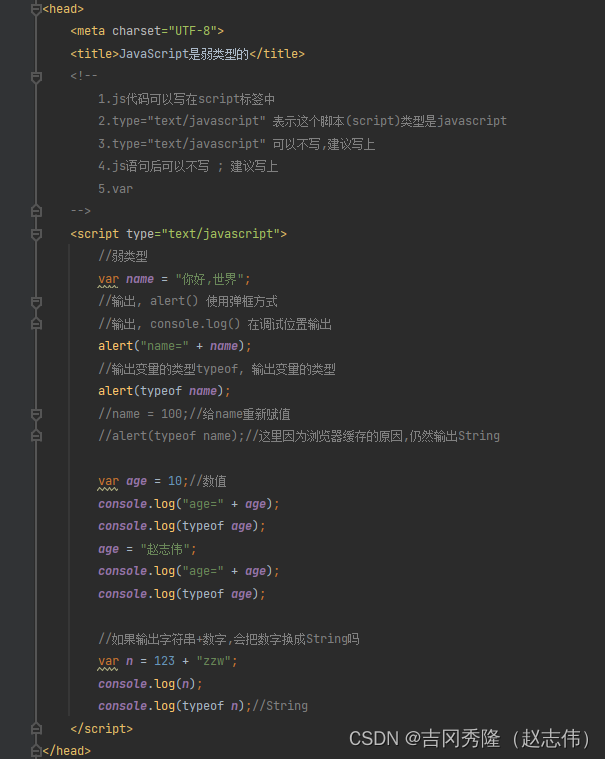
1.2 js使用方式
1.2.1 在script中写
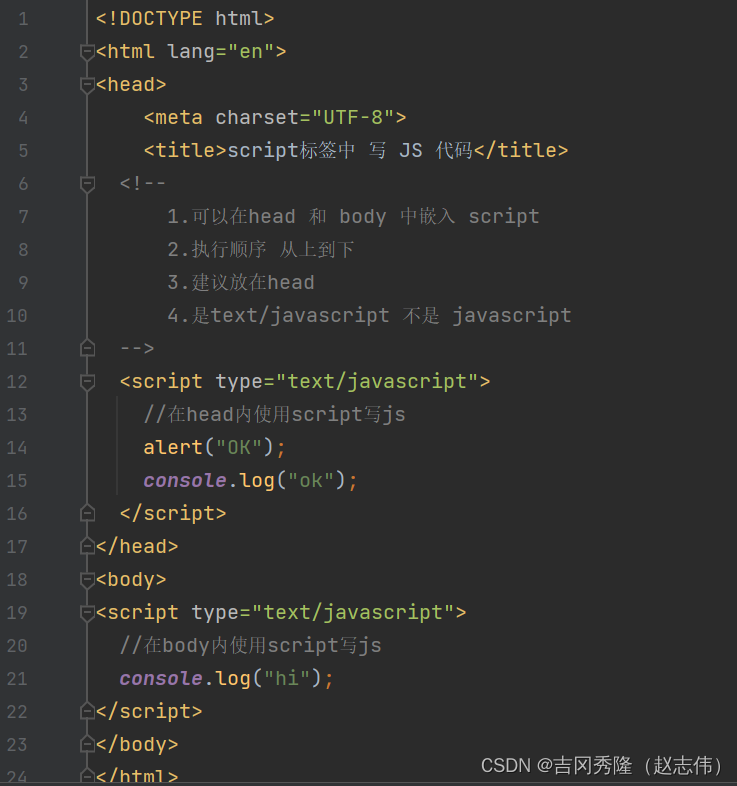
1.2.2 引入js文件
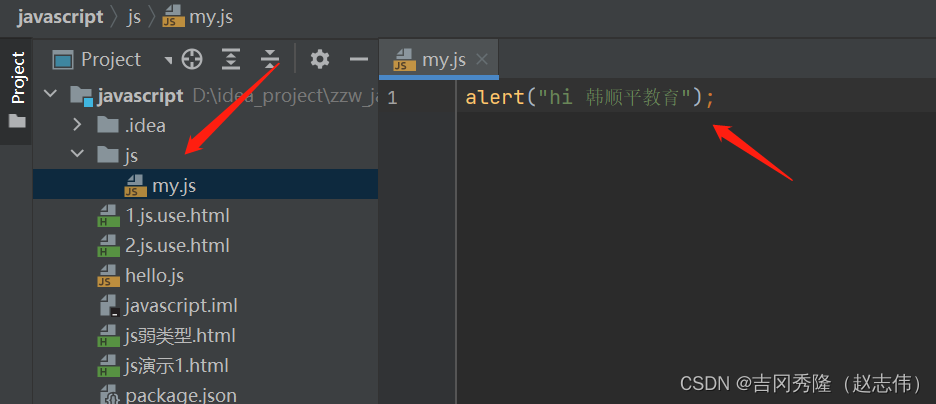
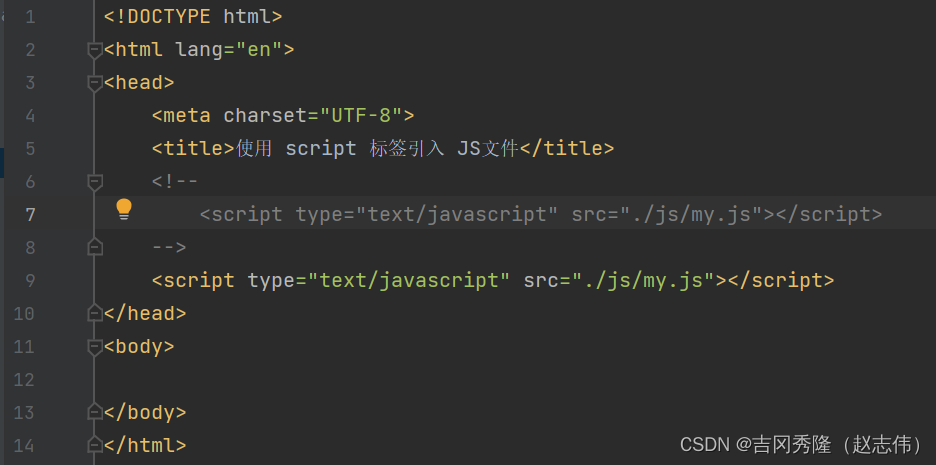
1.2.3 优先级
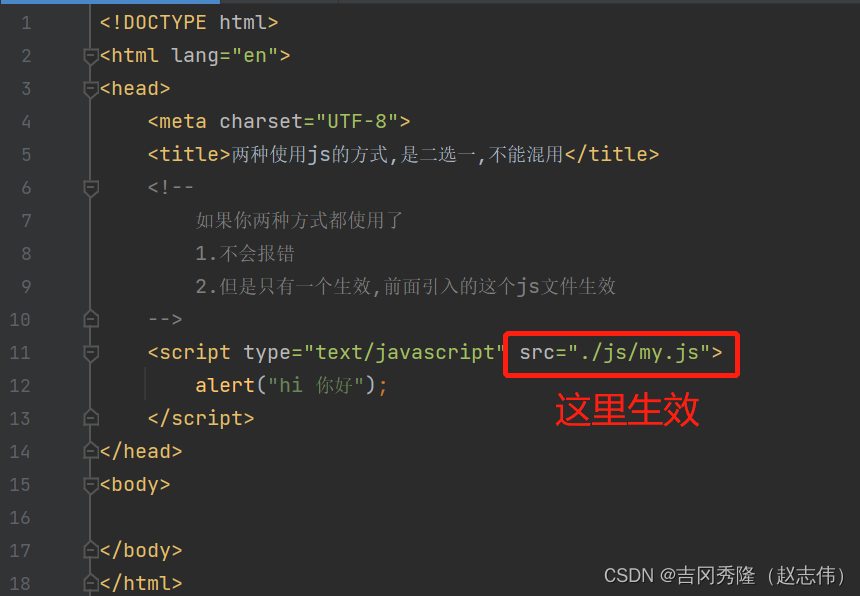
1.3 js查错方式
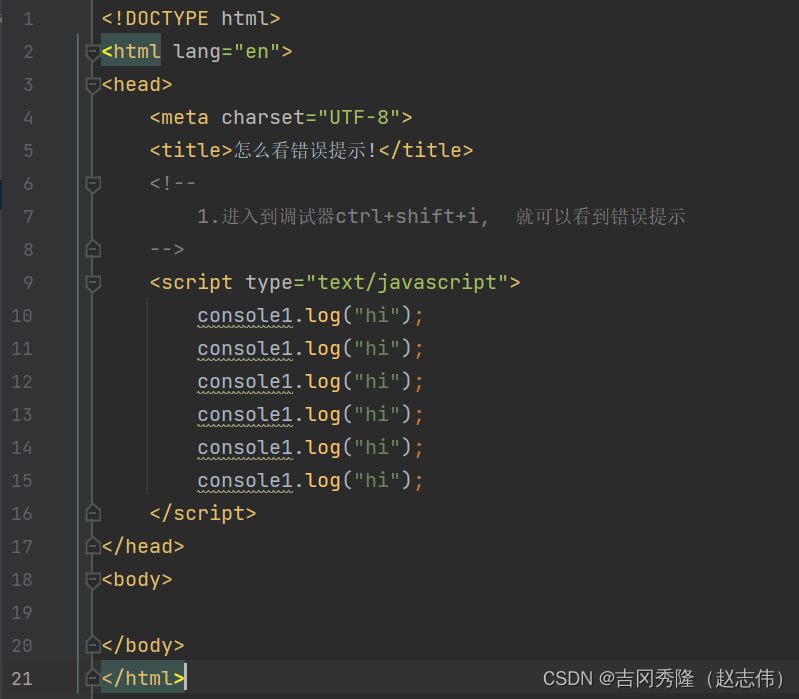
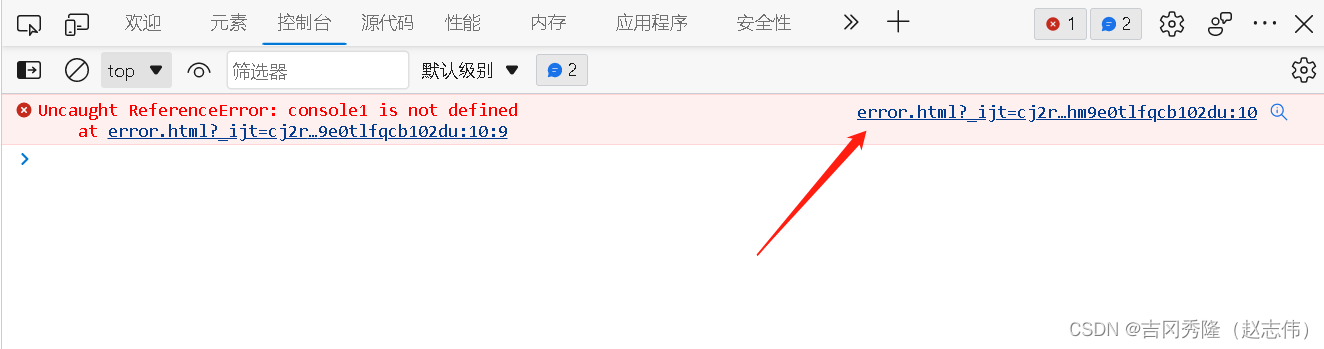
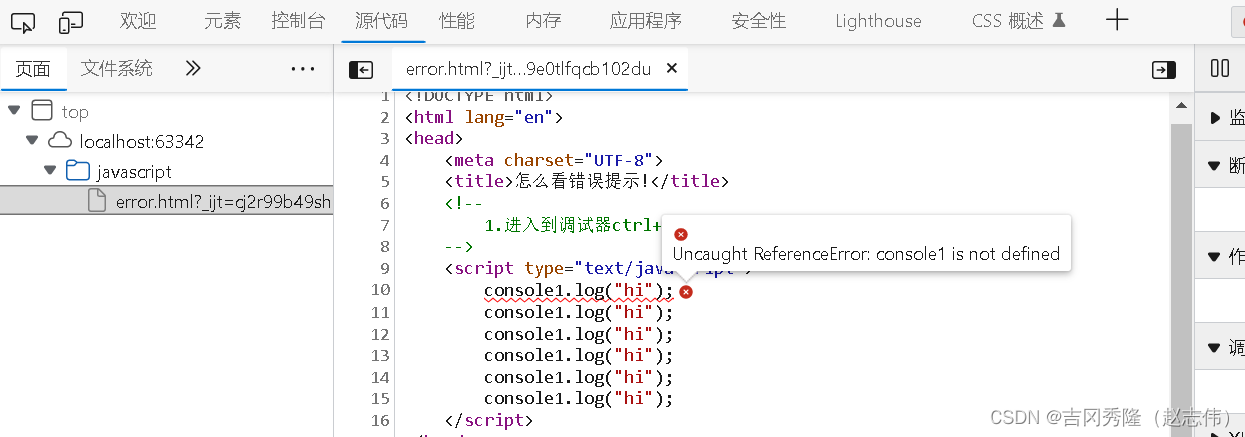
1.4 js变量定义
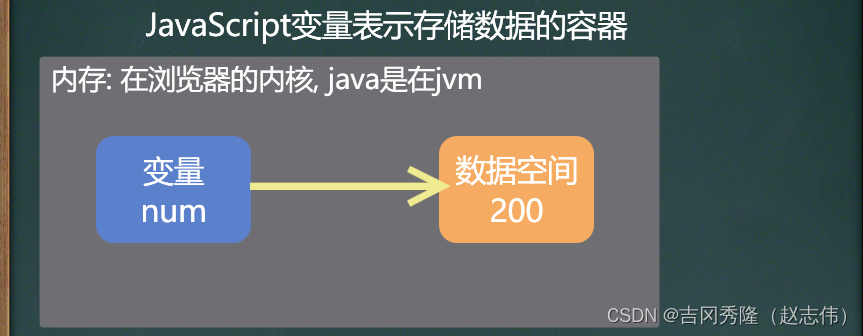
1.4 js数据类型
| 数据类型 | 英文表示 | 示例 |
|---|---|---|
| 数值类型 | number | 1.1 1 |
| 字符串类型 | string | ‘a’ ‘abc’ “abc” |
| 对象类型 | object | |
| 布尔类型 | boolean | number |
| 函数类型 | function | number |
1.4.1 特殊值
| 特殊值 | 含义 |
|---|---|
| undefined | 变量未赋初始值时,默认undefined |
| null | 空值 |
| NaN | Not a Number 非数值 |
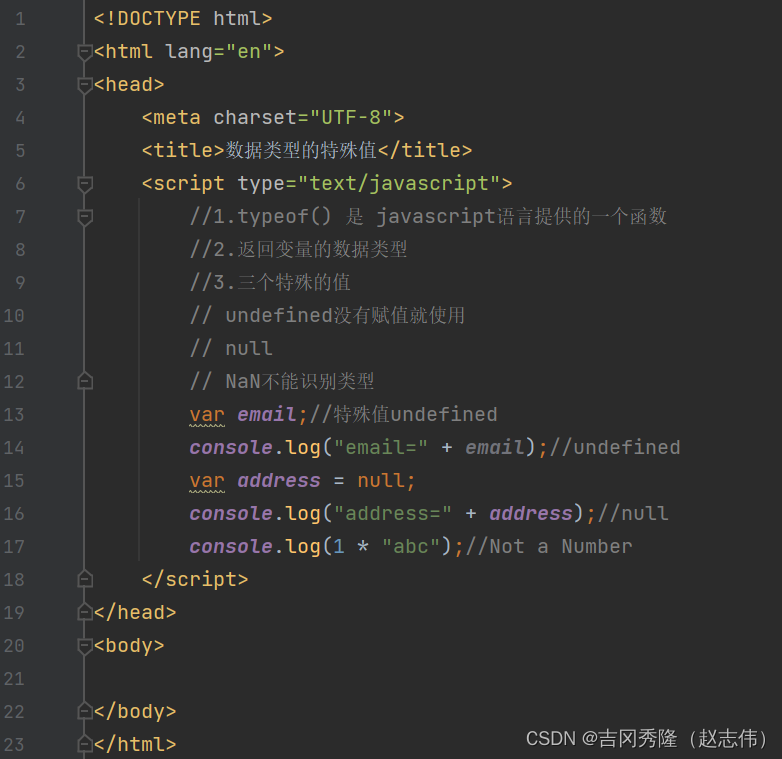
1.4.2 注意事项
String字符串[可以用双引号括起来,也可以单引号括起来]
“a book of javascript”, ‘abc’, “a”
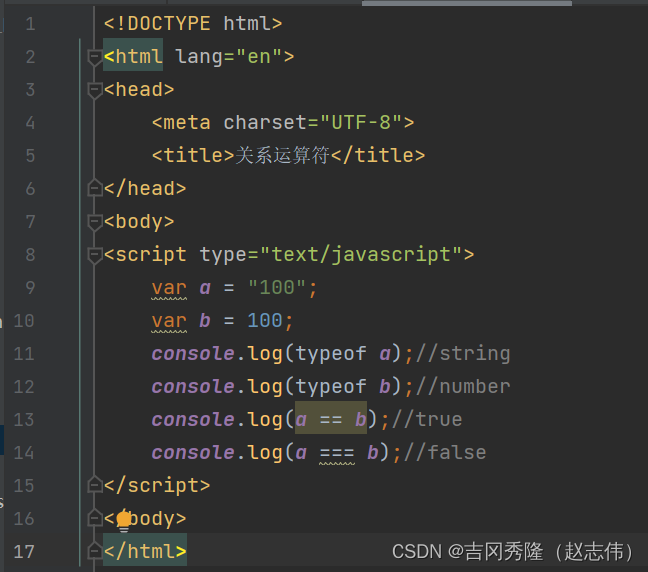
1.5 js运算符
给定: x = 5
| 运算符 | 描述 | 例子 |
|---|---|---|
| == | 等于(只比较值) | x == 5 为true,x == "5"为true, x == 8为false |
| === | 全等(同时比较值和类型) | x === 5 为true; x === "5"为false |
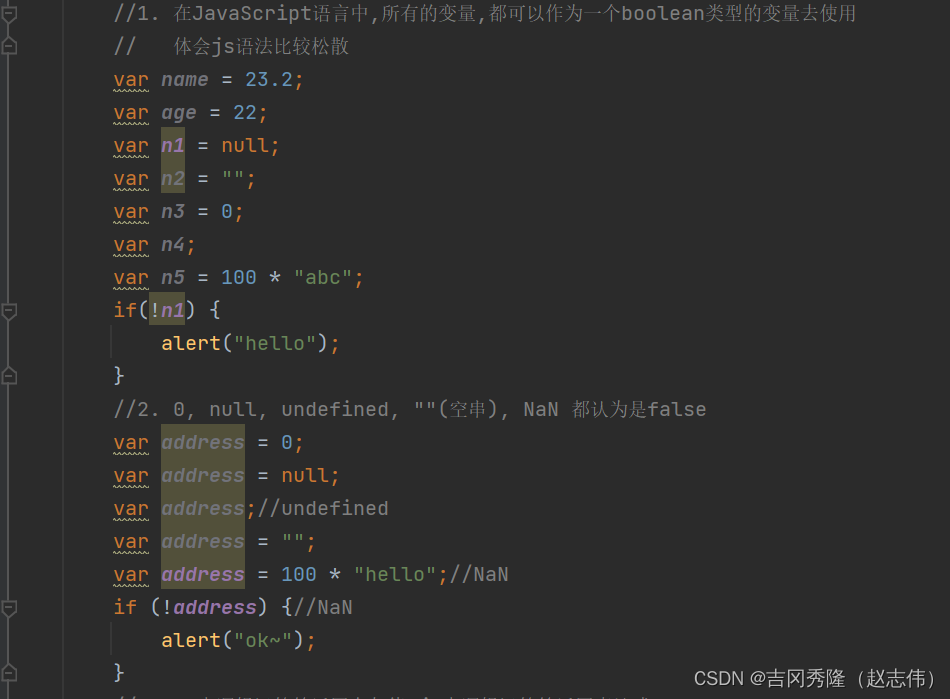
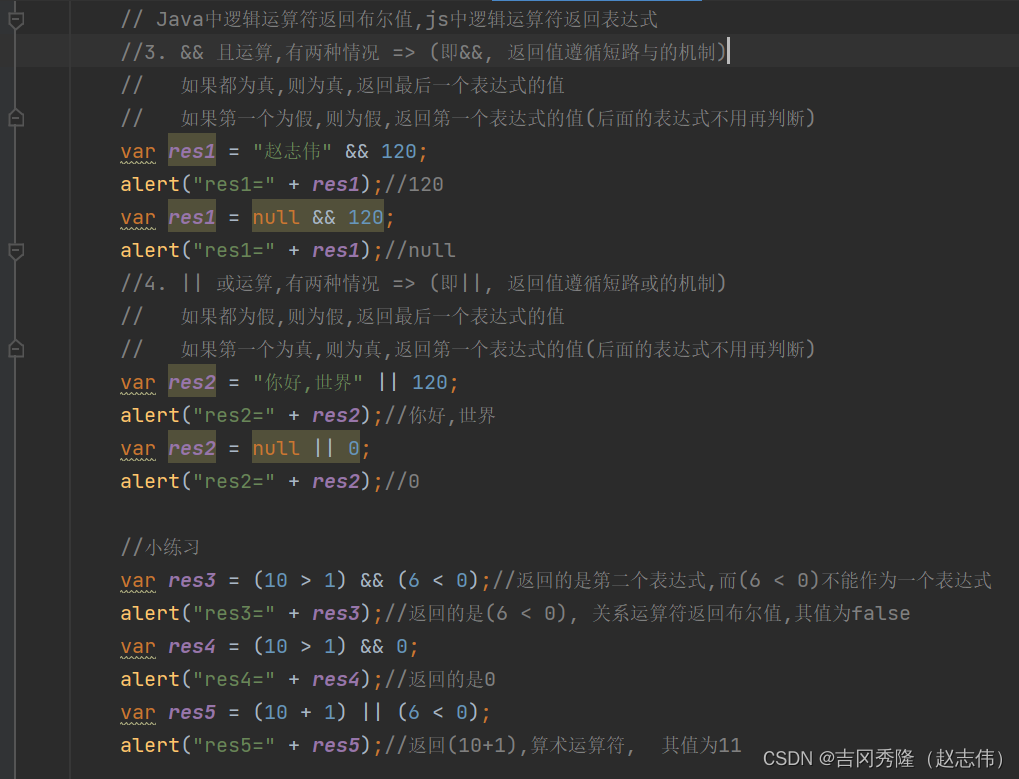
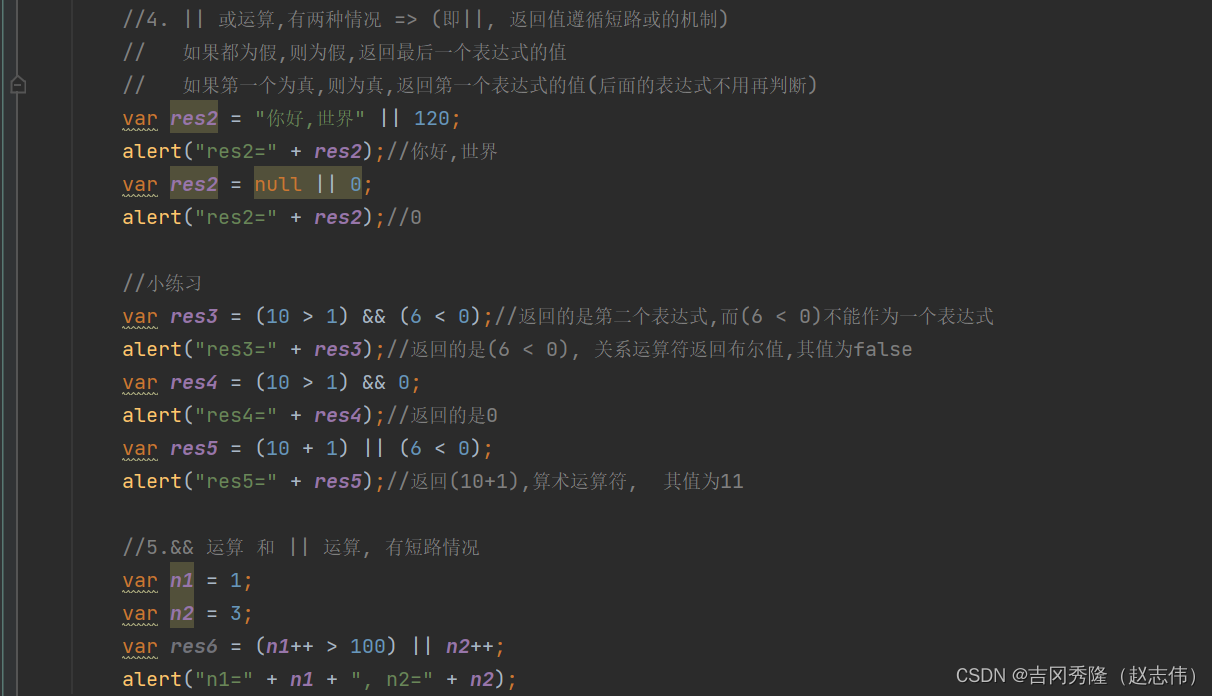
1.5.1 逻辑运算符
给定: x=6 和 y=3
| 运算符 | 描述 | 例子 |
|---|---|---|
| && | and | 描述 |
| || | or | 描述 |
| ! | not | 描述 |
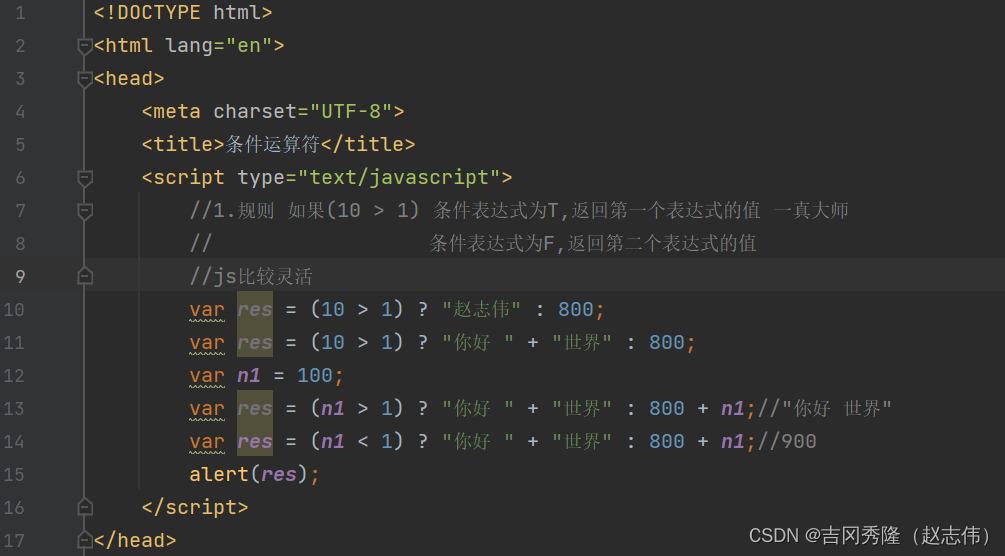
1.5.2 三元运算符
1.6 js数组
1.6.1 定义方式
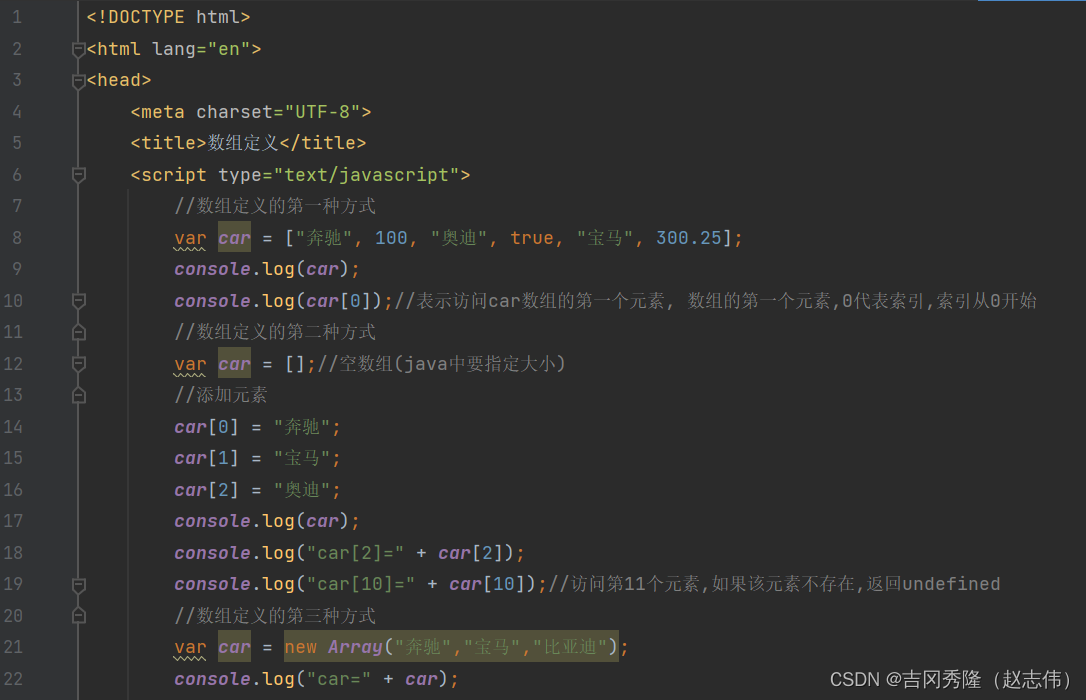
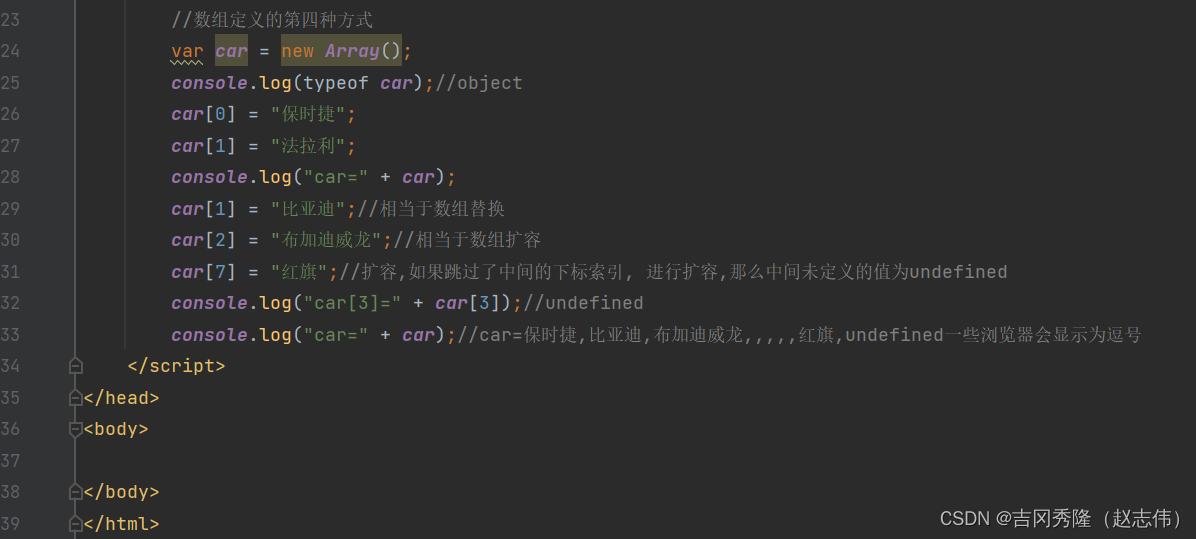
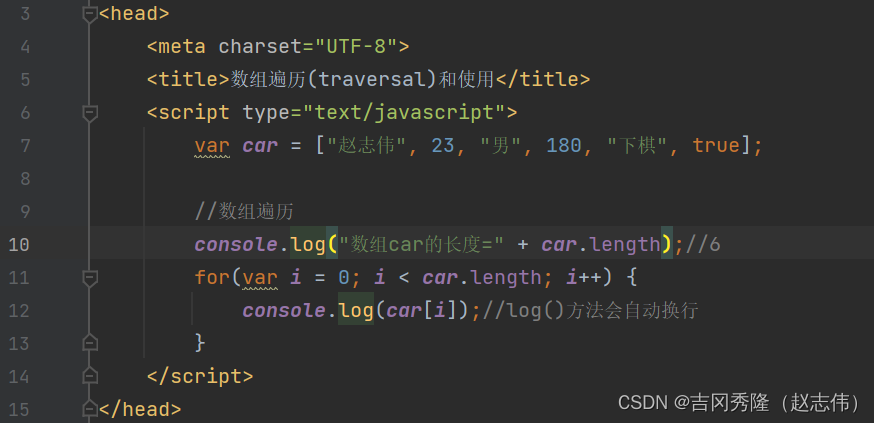
1.6.2 数组遍历
1.7 js函数
1.7.1 函数入门

1.7.2 函数使用方式
1.7.1.1 使用方式一
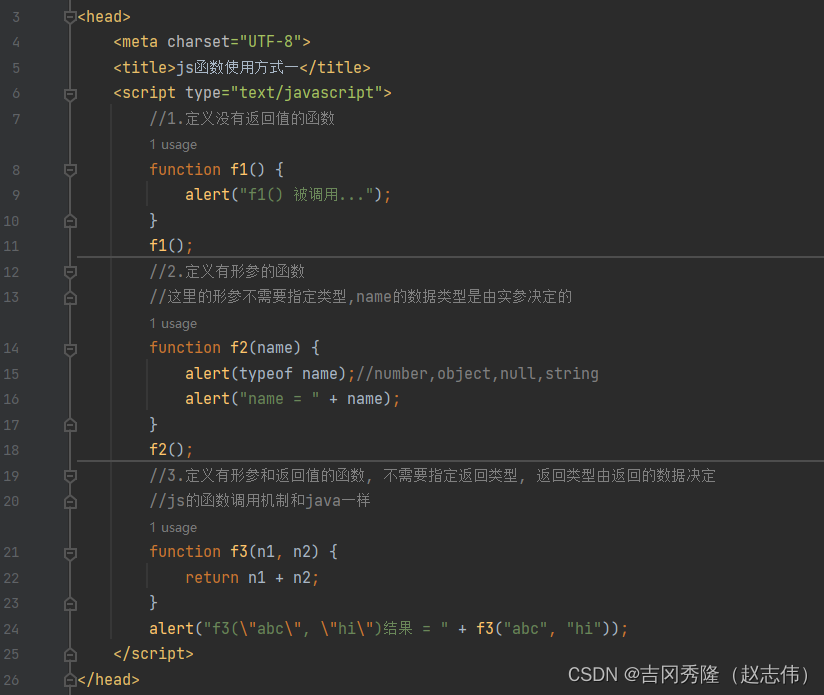
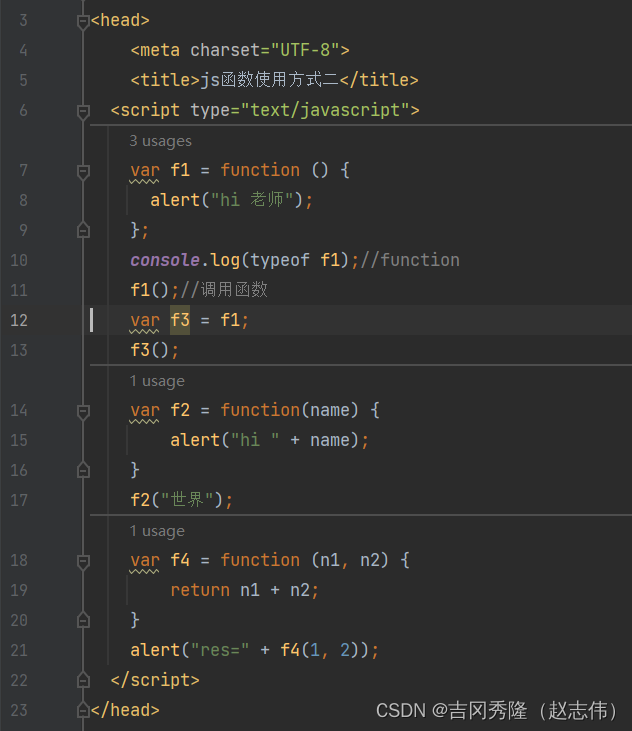
1.7.1.2 使用方式二
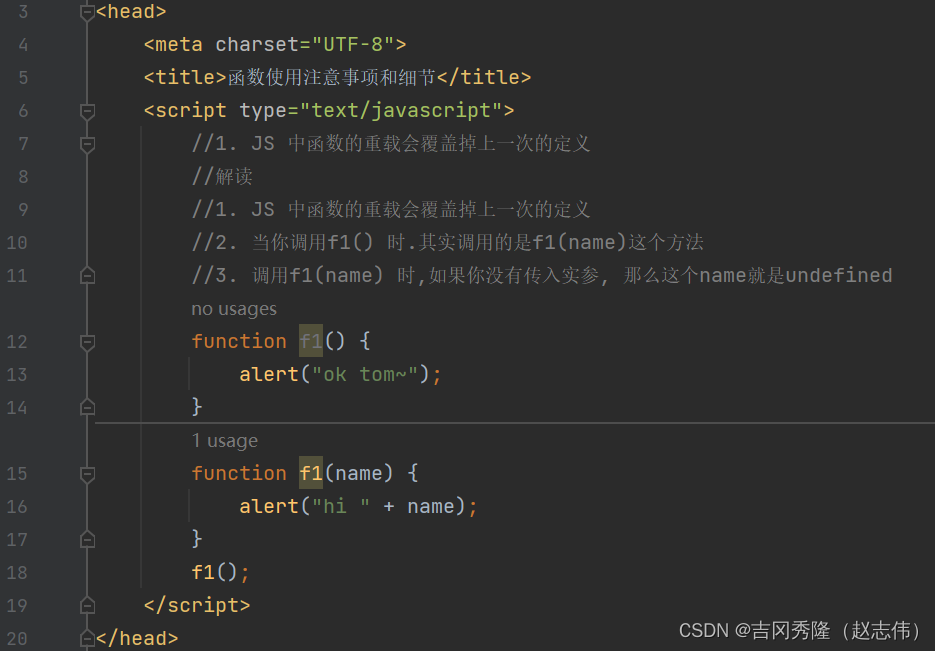
1.7.3 函数注意事项
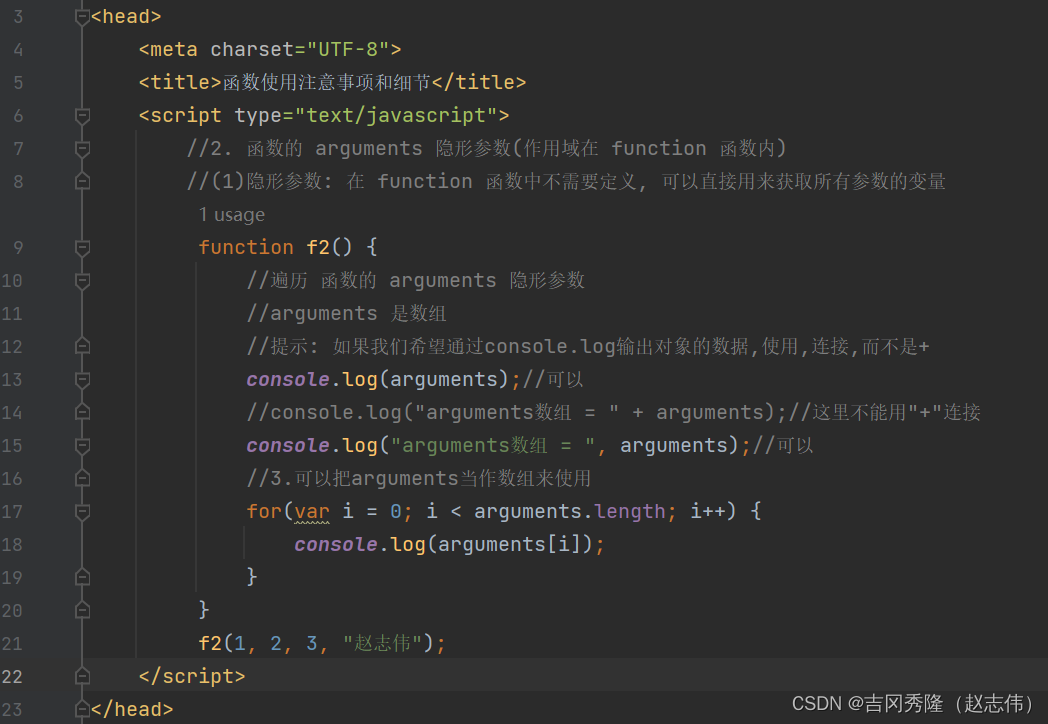

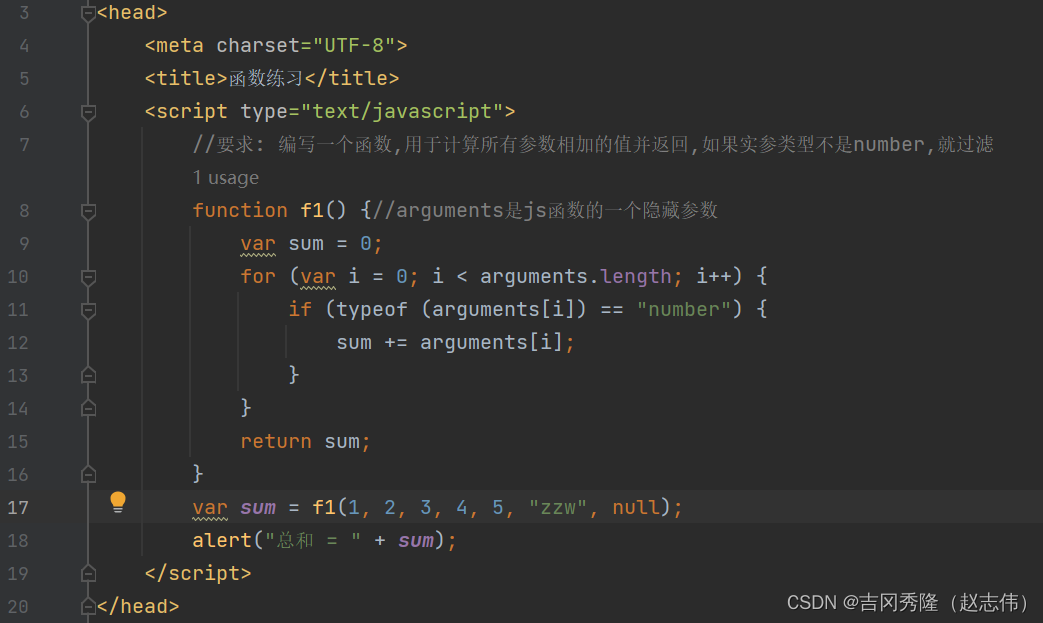
1.7.4 函数练习题
1.8 定义对象
1.8.1 使用object定义
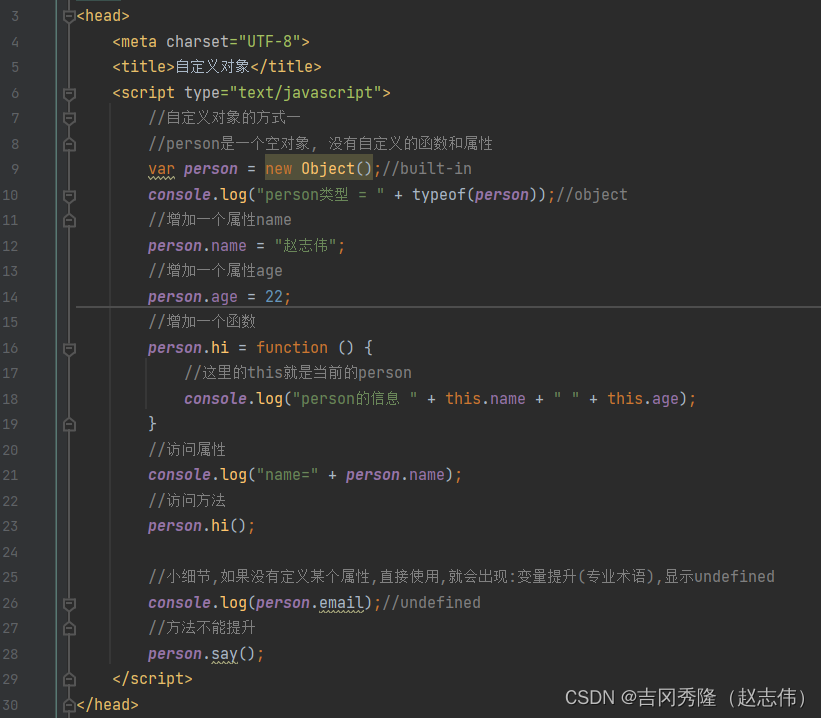
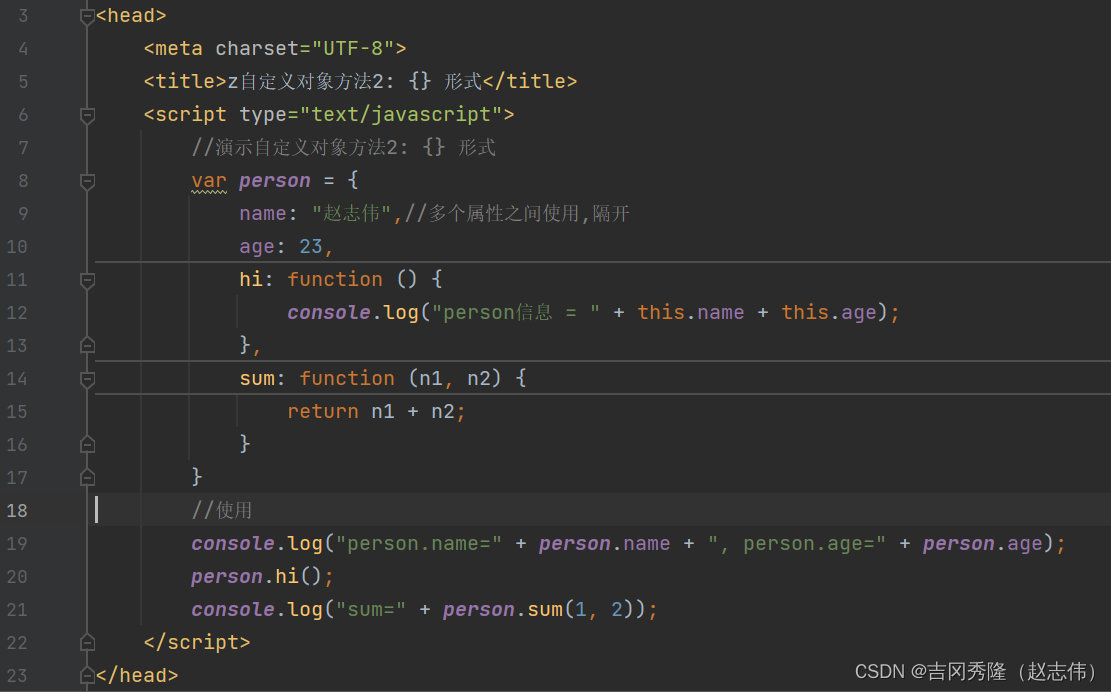
1.8.2 使用{}定义
1.9 事件
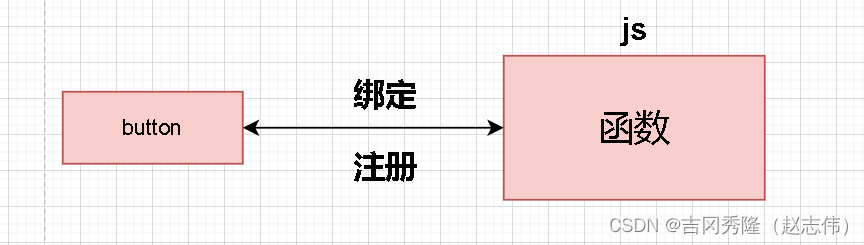
- 事件的注册(绑定)
事件注册(绑定),当事件响应(触发)后要浏览器执行哪些操作代码,叫做事件注册或事件绑定; - 静态注册事件
通过html标签的事件属性直接赋予事件响应后的代码,这种方式叫做静态注册; - 动态注册事件(dom)
通过 js 代码得到标签的 dom 对象,然后再通过 dom 对象.事件名 = function () {} 这种形式叫做动态注册
步骤:(1)获取标签对象dom对象; (2)标签对象.事件名 = function() {}
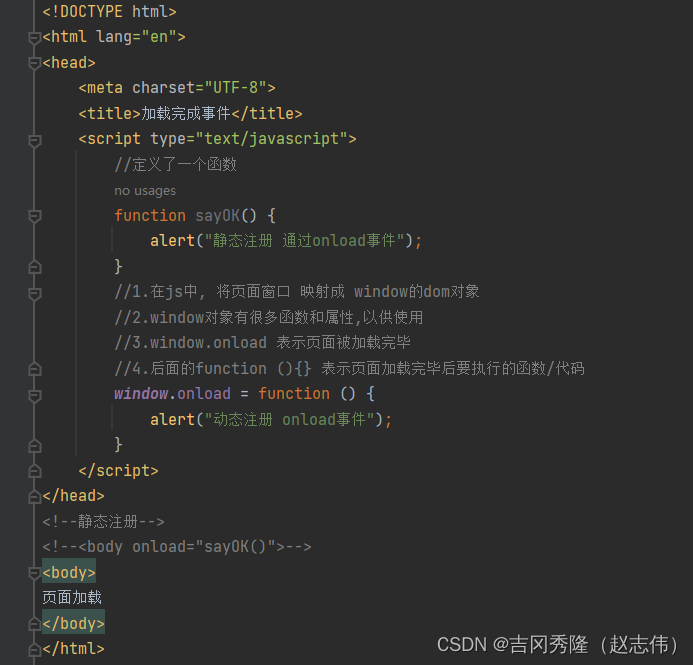
1.9.1 onload事件
1.9.3 onclick事件
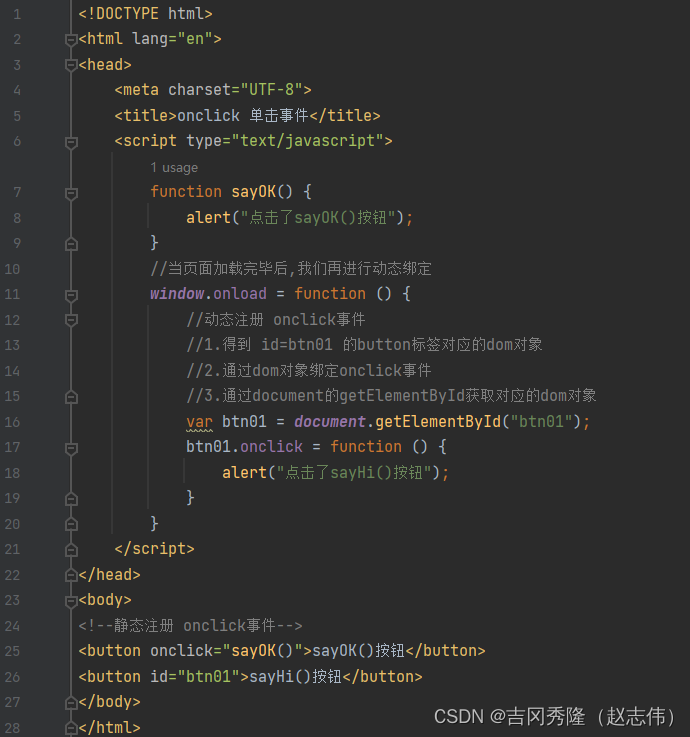
1.9.4 失去焦点事件
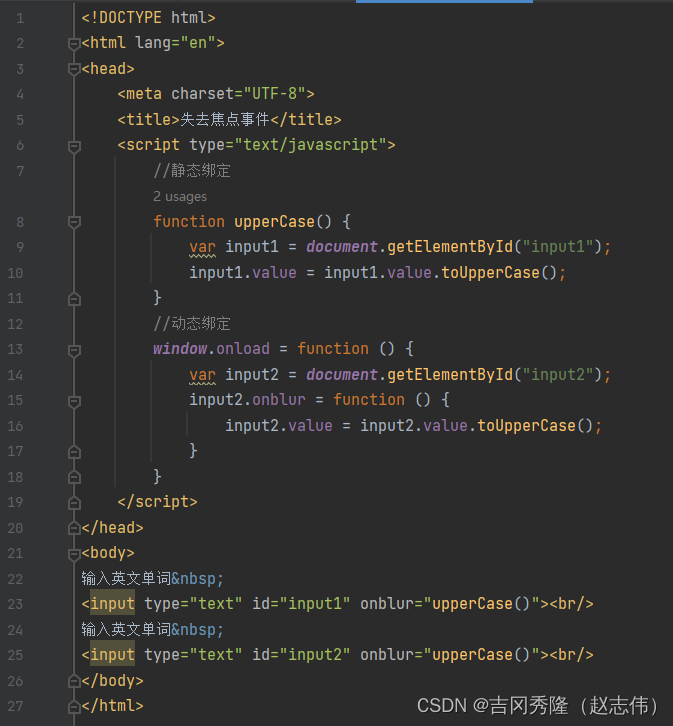
1.9.5 内容发生改变事件

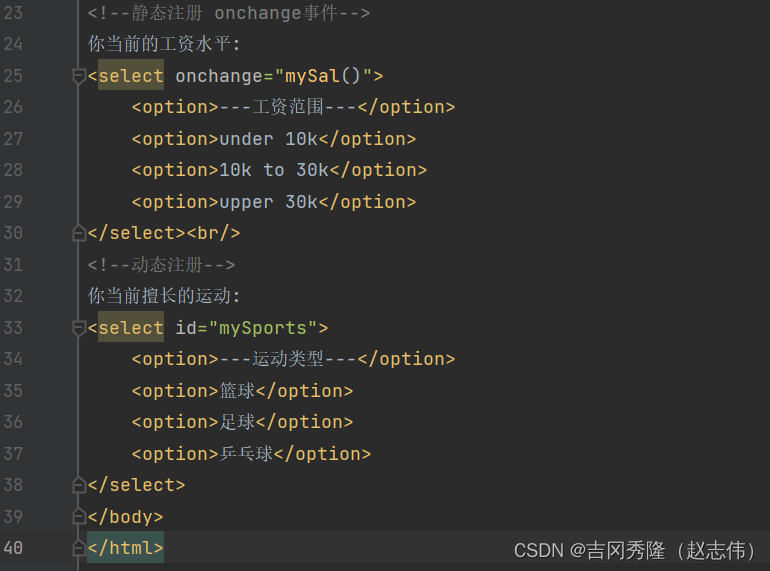
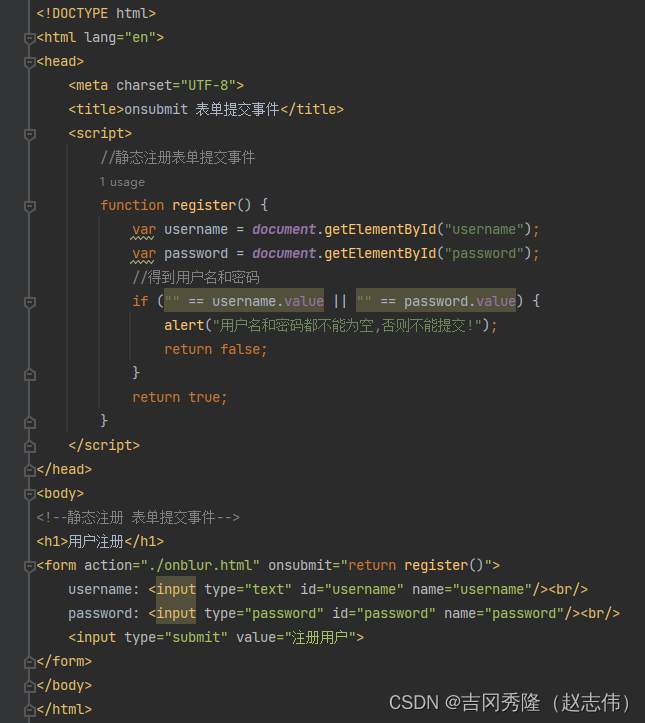
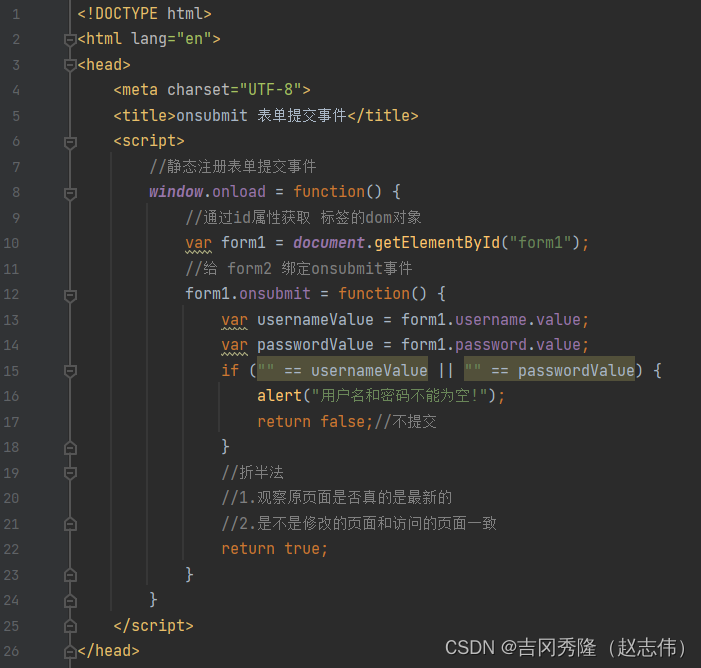
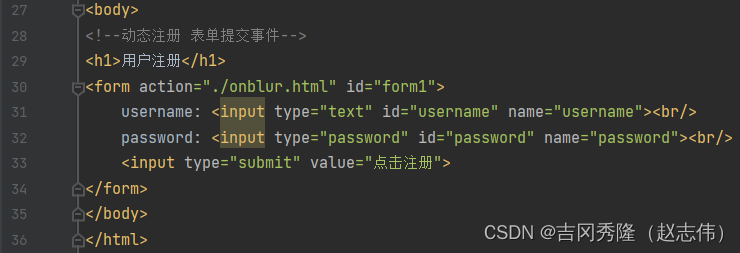
1.9.6 表单提交事件
1.9.6.1 静态注册
1.9.6.2 动态注册
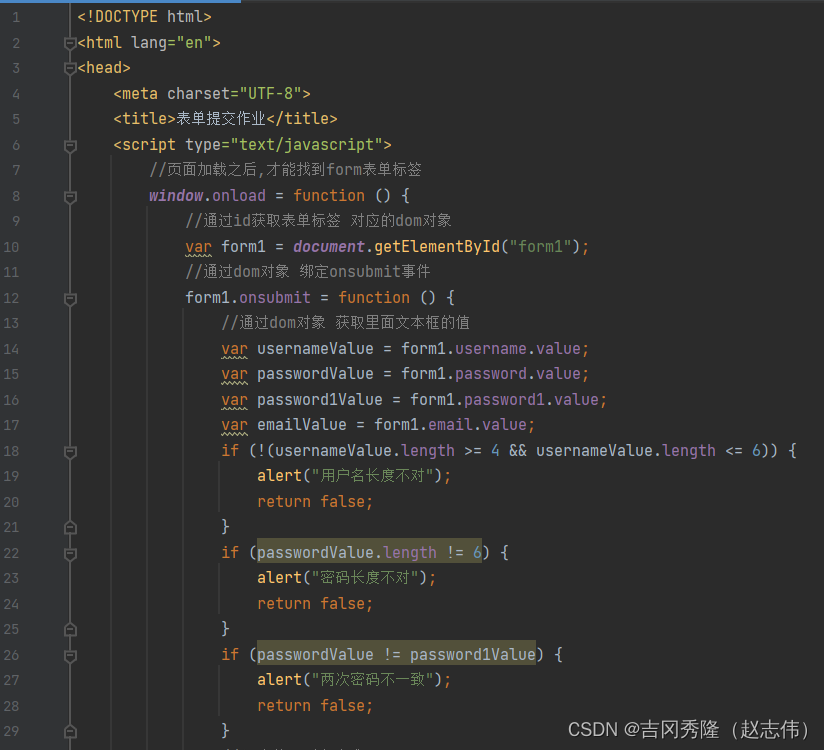
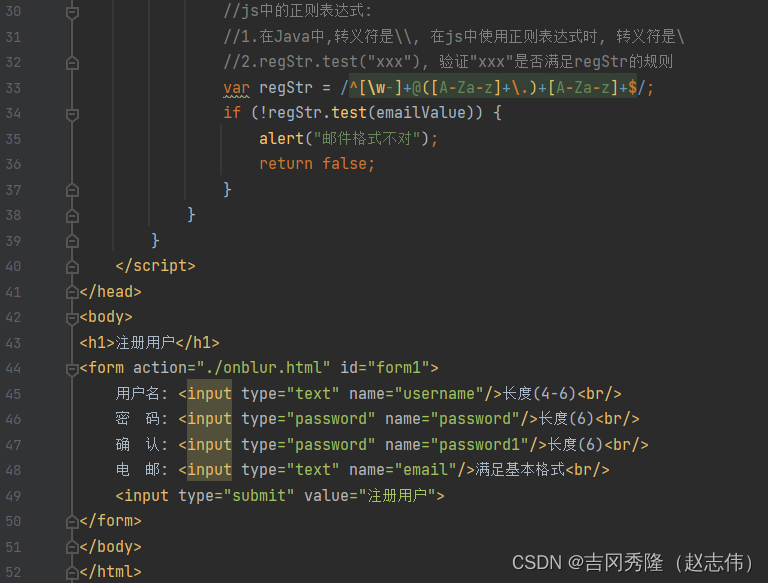
1.9.6.3 表单作业
2. dom对象
- DOM 全称是 Document Object Model 文档对象模型;
- 就是将文档中的标签, 属性, 文本转换成对象来管理;
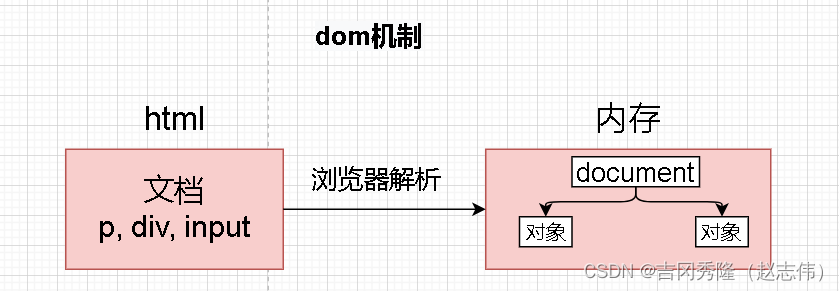
2.1 文档对象模型
- 当网页被加载时, 浏览器会创建页面的文档对象模型(Document Object Model)
- html dom 树
2.2 document对象
- document 它管理了所有的HTML 文档内容;
- document 它是一种树结构的文档;
- 有层级关系, 在 dom中把所有的标签都 对象化;
- 通过document 可以访问所有的标签对象;
2.2.1 应用实例一
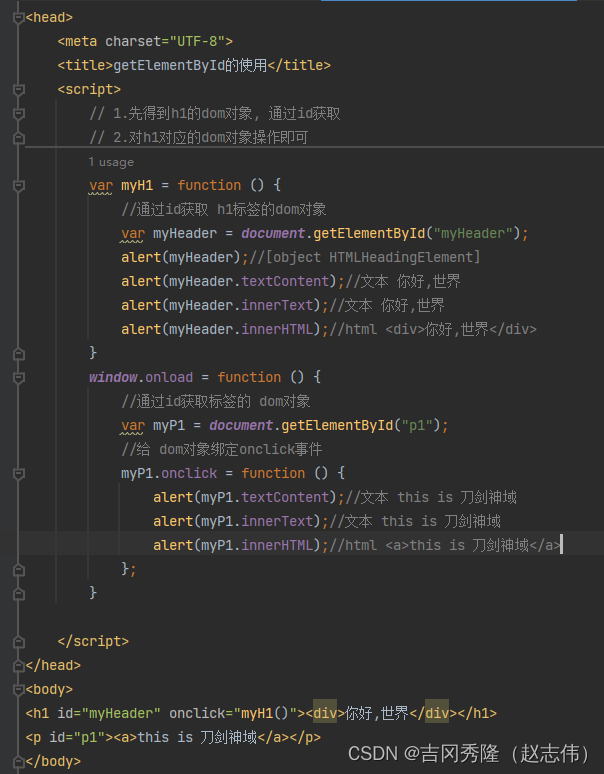
2.2.2 应用实例二
- 静态注册
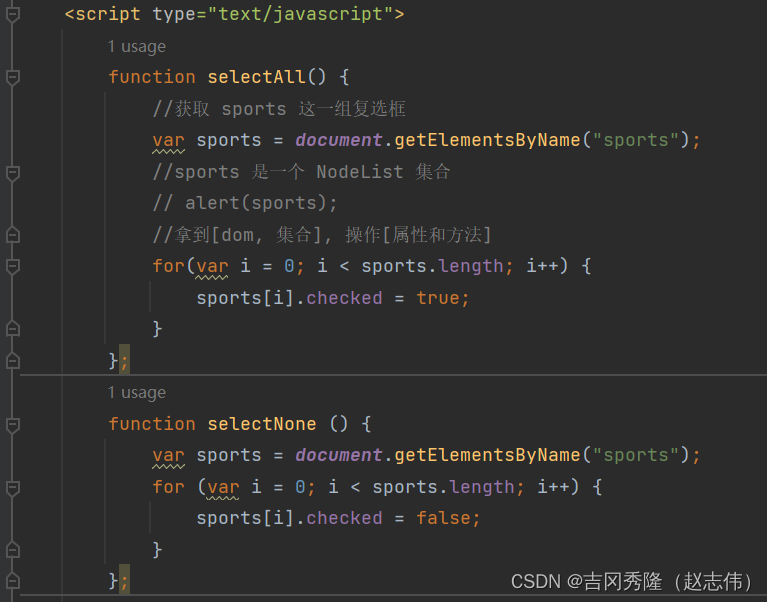
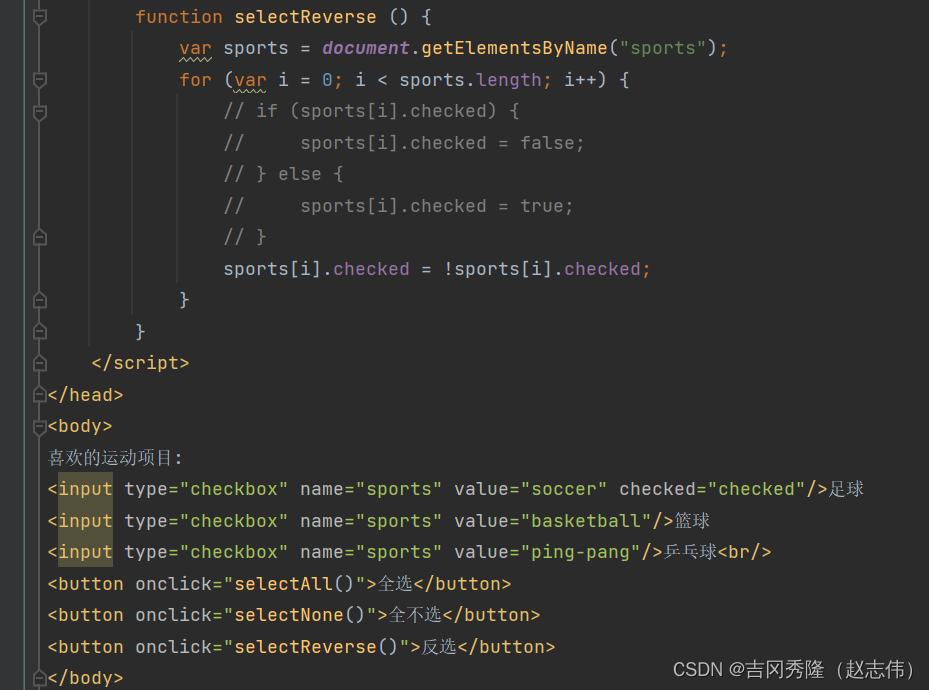
– 动态注册
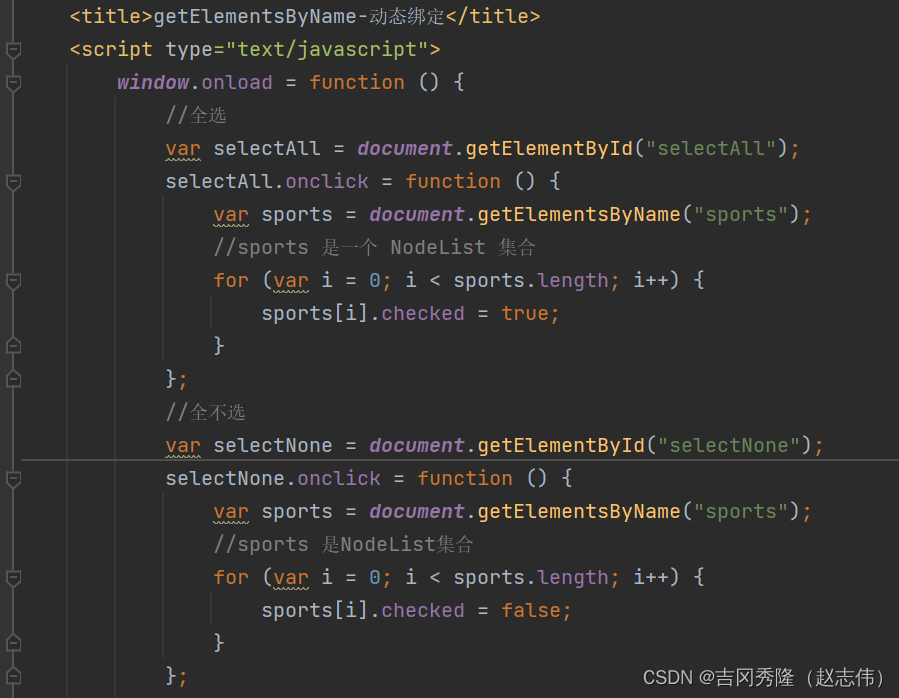
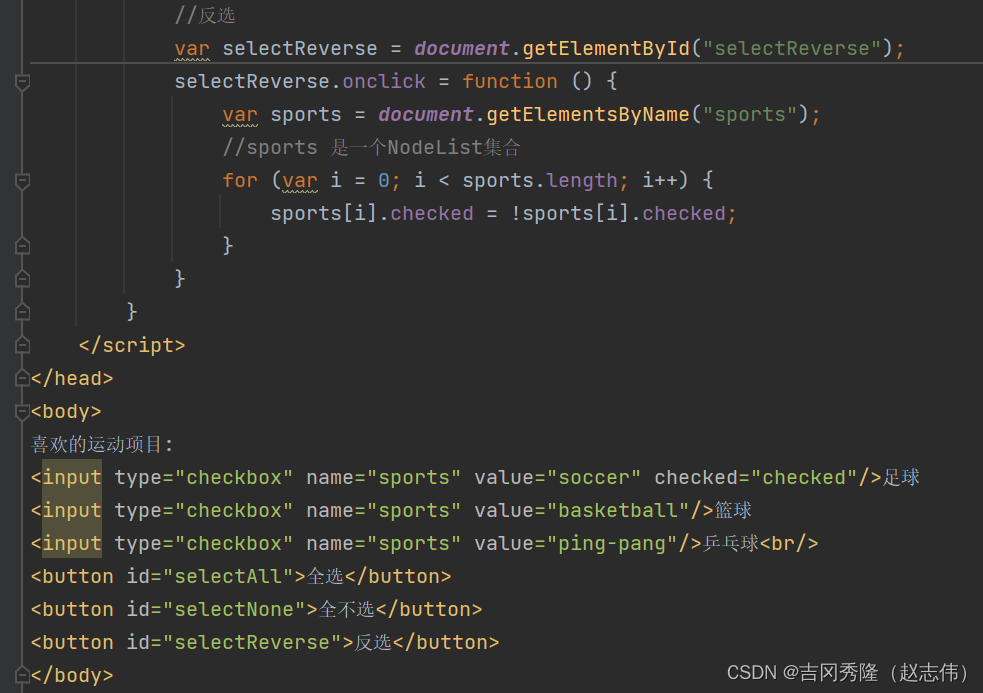
2.2.3 应用示例三
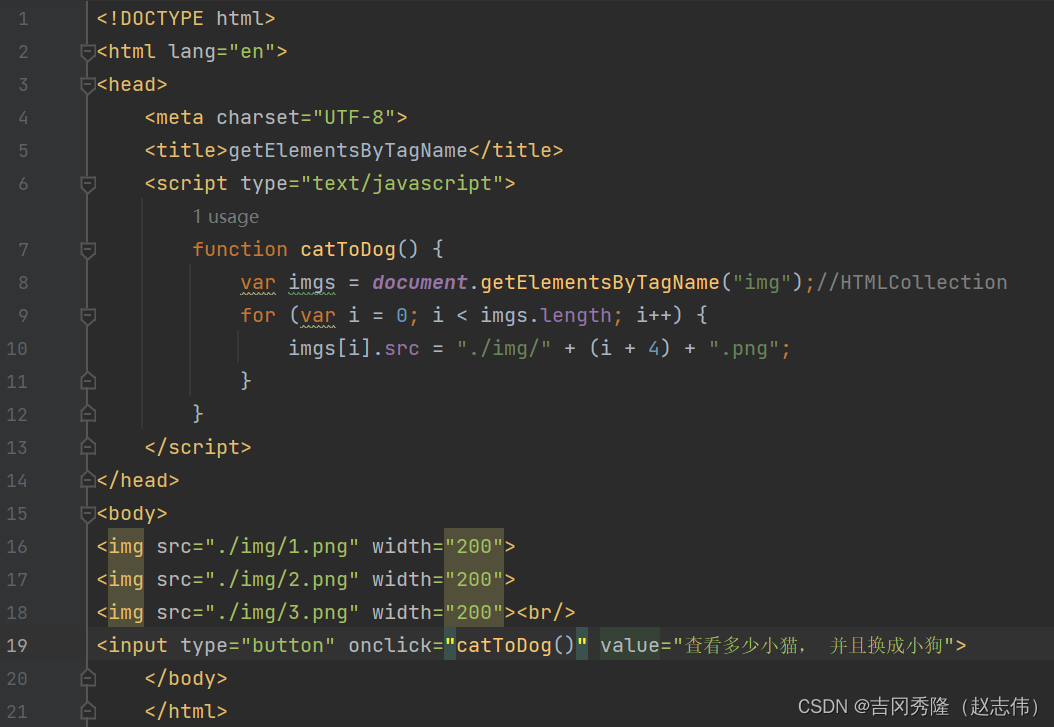
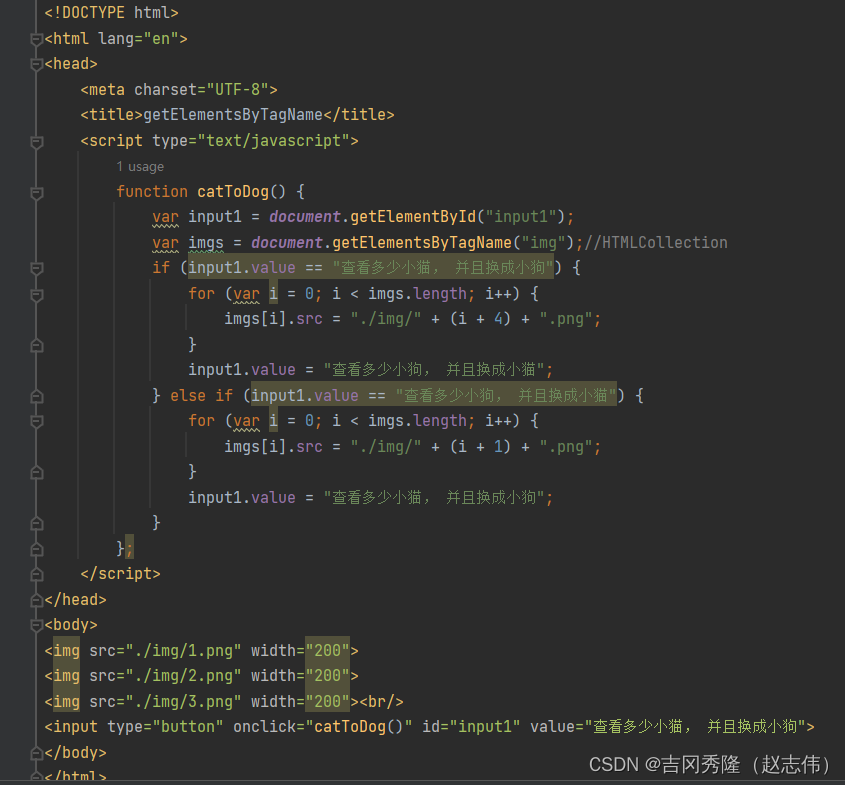
- 升级版:做到猫狗切换
思路:根据value值判断选择具体的执行方法
2.2.4 应用案例四
2.3 DOM节点
在HTML DOM(文档对象模型)中,每个部分都是节点
- 文档 本身是文档节点;
- 所有 HTML元素 是元素节点;
- 所有 HTML属性 是属性节点;
- HTML元素内的 文本 是文本节点;
- 注释是 注释 节点;
2.3.1 节点常用方法
2.3.1.1通过id获取节点
2.3.1.2获取所有option节点
2.3.1.3通过name获取节点
2.3.1.4获取指定dom对象下的子节点
2.3.1.5获取第一个节点
2.3.1.6获取父节点
2.3.1.7获取兄弟节点
2.3.1.8设置文本域内容
<!DOCTYPE html>
<html>
<head><meta charset="UTF-8"><title>演示HTML DOM 相关方法</title><link rel="stylesheet" type="text/css" href="style/css.css"/><script type="text/javascript">//动态注册window.onload = function () {//查找id=java节点var btn01 = document.getElementById("btn01");//绑定onclick事件btn01.onclick = function () {var java = document.getElementById("java");alert("java节点文本 = " + java.innerText);};//查找所有option节点var btn02 = document.getElementById("btn02");btn02.onclick = function () {//id --> getElementById()//name --> getElementsByName()//元素标签 --> getElementsByTagName()var options = document.getElementsByTagName("option");//HTMLCollectionfor (var i = 0; i < options.length; i++) {alert("options[" + (i + 1) + "] = " + options[i].innerText);}};//查找name=sport节点var btn03 = document.getElementById("btn03");btn03.onclick = function () {var sports = document.getElementsByName("sport");// alert(sports);//NodeListfor (var i = 0; i < sports.length; i++) {if (sports[i].checked) {alert("运动是 = " + sports[i].value);}}}//查找id=language下所有li节点var btn04 = document.getElementById("btn04");btn04.onclick = function () {var lis = document.getElementById("language").getElementsByTagName("li");// alert("lis=" + lis);//HTMLCollectionfor (var i = 0; i < lis.length; i++) {alert("lis[" + (i + 1) + "] = " + lis[i].innerText);}};//返回id=sel01的所有子节点var btn05 = document.getElementById("btn05");btn05.onclick = function () {//var options = document.getElementById("sel01").getElementsByTagName("option");//alert(options.length);//5 不算换行符//1. 如果使用document.getElementById("sel01").childNodes; 获取的是[object Text],[object HTMLOptionElement]//2. 如果不希望得到 text对象, 需要将所有的内容放在一行var childNodes = document.getElementById("sel01").childNodes;//alert(childNodes);//NodeList//alert(childNodes.length);//11, 加上文本, 在这里换行符属于文本[object Text]for (var i = 0; i < childNodes.length; i++) {//alert(childNodes[i]);//HTMLOptionElementif (childNodes[i].innerText != undefined && childNodes[i].selected) {alert("女友有 = " + childNodes[i].innerText);}}alert("===============还有一个方法===============");//1.sel01 是 HTMLSelectElement => 本身具有集合的特点var sel01 = document.getElementById("sel01");alert(sel01);//HTMLSelectElementalert(sel01[0]);//HTMLOptionElementfor (var i = 0; i < sel01.length; i++) {alert("sel01[" + (i + 1) + "] = " + sel01[i].innerText);}};//返回id=sel01 的第一个子节点var btn06 = document.getElementById("btn06");btn06.onclick = function () {var sel01 = document.getElementById("sel01");var childNodes = sel01.childNodes;alert(childNodes[0]);//object Textvar firstChild = sel01.firstChild;alert(firstChild);//object Text]alert(sel01[0]);//直接得到第一个option节点 object HTMLOptionElement}//返回id=java的父节点var btn07 = document.getElementById("btn07");btn07.onclick = function () {var java = document.getElementById("java");alert(java);//HTMLLIElementvar parentNode = java.parentNode;alert(parentNode);//HTMLUListElementalert(parentNode.innerText);alert(parentNode.innerHTML);//<li id="java">Java</li>var childNodes = parentNode.childNodes;alert(childNodes.length);//7for (var i = 0; i < childNodes.length; i++) {if (childNodes[i].innerText != undefined) {//换行符[文本]也算一个节点alert("childNodes[" + (i + 1) + "] = " + childNodes[i].innerText);}}var parentElement = java.parentElement;alert(parentElement);//HTMLUListElement};//返回id=ct的前后兄弟节点var btn08 = document.getElementById("btn08");btn08.onclick = function () {var ct = document.getElementById("ct");alert(ct.previousSibling);//Text[换行符]alert(ct.previousSibling.previousSibling);//HtmlOptionElementalert(ct.previousSibling.previousSibling.innerText);//霞燕alert(ct.nextSibling);//Text[换行符]alert(ct.nextSibling.nextSibling);//HTMLOptionElementalert(ct.nextSibling.nextSibling.innerText);//秋枫};//读取id=ct的value属性值var btn09 = document.getElementById("btn09");btn09.onclick = function () {var ct = document.getElementById("ct");alert(ct.value);ct.innerText = "春桃姑娘";//修改文本域};//设置#person的文本域var btn10 = document.getElementById("btn10");btn10.onclick = function () {var person = document.getElementById("person");person.innerText = "刀剑神域";//设置文本域}};</script>
</head>
<body>
<div id="total"><div class="inner"><p>你喜欢的运动项目:</p><input type="checkbox" name="sport" value="soccer" checked="checked"/>足球<input type="checkbox" name="sport" value="basketball" checked="checked"/>蓝球<input type="checkbox" name="sport" value="pingPang" checked="checked"/>乒乓球<hr/><p>你当前的女友是谁:</p><select id="sel01"><option>--女友--</option><option>霞燕</option><option id="ct" value="春桃姑娘">春桃</option><option>秋枫</option><option>冬梅</option></select><hr/><p>你的编程语言:</p><ul id="language"><li id="java">Java</li><li>Python</li><li>Go语言</li></ul><br/><br/><hr/><p>个人介绍:</p><textarea name="person" id="person">个人介绍</textarea></div>
</div>
<div id="btnList"><div><button id="btn01">查找id=java节点</button></div><div><button id="btn02">查找所有option节点</button></div><div><button id="btn03">查找name=sport节点</button></div><div><button id="btn04">查找id=language下所有li节点</button></div><div><button id="btn05">返回id=sel01的所有子节点</button></div><div><button id="btn06">返回id=sel01的第一个子节点</button></div><div><button id="btn07">返回id=java的父节点</button></div><div><button id="btn08">返回id=ct的前后兄弟节点</button></div><div><button id="btn09">读取id=ct的value属性值</button></div><div><button id="btn10">设置#person的文本域</button></div>
</div>
</body>
</html>2.4 js dom 乌龟吃鸡游戏


2.4.1 静态注册实现
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>tortoise-hen碰撞游戏</title><script type="text/javascript">//公鸡的坐标var hen_xPos = 200;var hen_yPos = 200;//乌龟图片的宽度和高度var tortoise_width = 94;var tortoise_height = 67;//公鸡图片的宽度和高度var hen_width = 76;var hen_height = 73;function move(obj) {//object HTMLButtonElementvar tortoise = document.getElementById("tortoise");var tortoise_left = tortoise.style.left;//100px 值传递var tortoise_top = tortoise.style.top;//130px 值传递var tortoise_xPos = parseInt(tortoise_left.substring(0, tortoise_left.indexOf("p")));var tortoise_yPos = parseInt(tortoise_top.substring(0, tortoise_top.indexOf("p")));//通过button的 dom对象,获取innerTextswitch (obj.innerText) {case "向上走":tortoise_yPos -= 10;tortoise.style.top =tortoise_yPos + "px";break;case "向下走":tortoise_yPos += 10;tortoise.style.top = tortoise_yPos + 'px';break;case "向左走":tortoise_xPos -= 10;tortoise.style.left = tortoise_xPos + "px";break;case "向右走":tortoise_xPos += 10;tortoise.style.left = tortoise_xPos + "px";break;}//走完之后再判断//4.1 得到乌龟左和公鸡左的距离,纵向距离y// (1)如果乌龟在公鸡上面, 如果纵向距离y < 乌龟图片的高度时, 说明它们可能在纵向发生重叠, 使用 yy 来记录// (2) 吐过乌龟在公鸡下面,如果纵向距离y < 公鸡图片的高度时, 说明它们可能在纵向发生重叠, 使用 yy 来记录// 4.2 得到乌龟和公鸡左上角的距离, 横向距离x// (1)如果乌龟在公鸡左面, 如果横向距离x < 乌龟图片的宽度时, 说明它们可能在横向发生重叠, 使用 xx 来记录// (2)如果乌龟在公鸡右面, 如果横向距离x < 公鸡图片的宽度时, 说明它们可能在横向发生重叠, 使用 xx 来记录var y = Math.abs(tortoise_yPos - hen_yPos);var x = Math.abs(tortoise_xPos - hen_xPos);var yy = 0;//var xx = 0;//默认横向没有重叠if (tortoise_yPos < hen_yPos) {//乌龟在上if (y < tortoise_height) {yy = 1;}} else {//乌龟在下if (y < hen_height) {yy = 1;}}if (tortoise_xPos < hen_xPos) {//乌龟在左if (x < tortoise_width) {xx = 1;}} else {//乌龟在右if (x < hen_width) {xx = 1;}}if (xx && yy) {//js中 0默认是falsealert("发生碰撞");tortoise.style.left = 100 + "px";tortoise.style.top = 130 + "px";}}</script>
</head>
<body>
<table><tr><td></td><!--1.this表示的是你点击的这个button, 而且已经是一个dom对象3.可以通过dom对象操作属性和方法--><td><button onclick="move(this)">向上走</button><!--静态注册传参 只能用单引号--></td><td></td></tr><tr><td><button onclick="move(this)">向左走</button></td><td></td><td><button onclick="move(this)">向右走</button></td></tr><tr><td></td><td><button onclick="move(this)">向下走</button></td><td></td></tr>
</table>
<img src="./img/1.bmp" id="tortoise" style="position: absolute; left: 100px; top: 130px;" border="1">
<img src="./img/2.bmp" style="position: absolute; left: 200px; top: 200px;" border="1">
</body>
</html>