新乡网站建设方案建设免费网站登录网址
在日常服务器日志查看中常用到的命令有grep、tail等,有时想查看详细日志,用到vi命令,记录下来,方便查看。
操作文件:test.properites
一、查看与编辑
查看命令:vi + 文件名
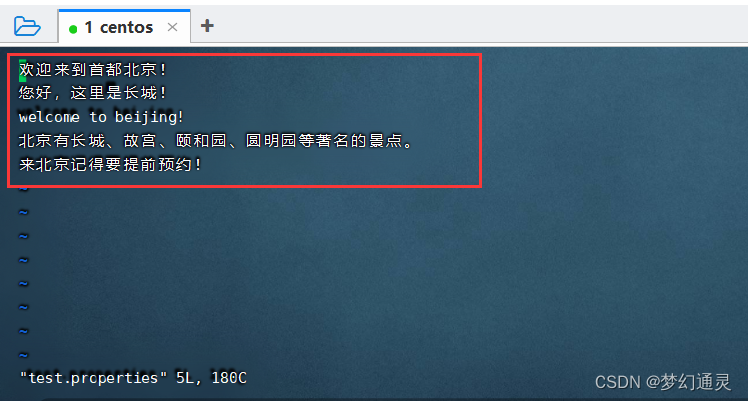
编辑命令:按键 i(insert),进入编辑模式。
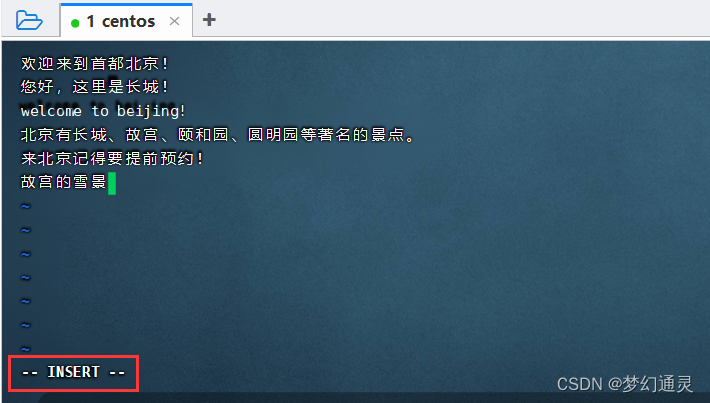
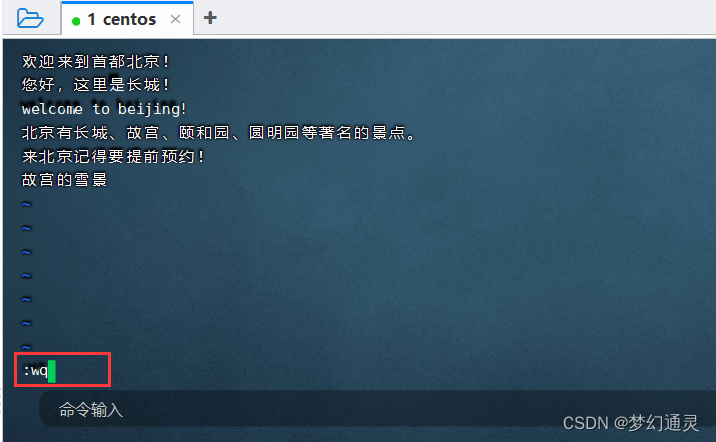
保存命令:先退出编辑 esc,再 :wq 即编辑后退出。
二、查找与跳转
vi 进入文件内部后,/ (右边shift键左侧的/键),输入查找的字即可。
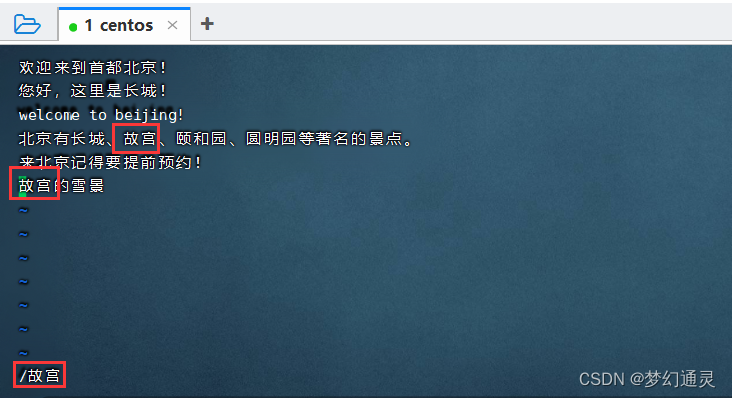
按 小写的n,从文件的头往下搜索输入的字段,到达文件底部,会提示:search hit BOTTOM, continuing at TOP,即已经到底了。
按 大写的N,从文件的下往上搜索输入的字段,到达文件顶部,会提示:search hit TOP, continuing at BOTTOM,即已经到头了。
对于大文件的查找,可能需要直接到文件末尾或开头。
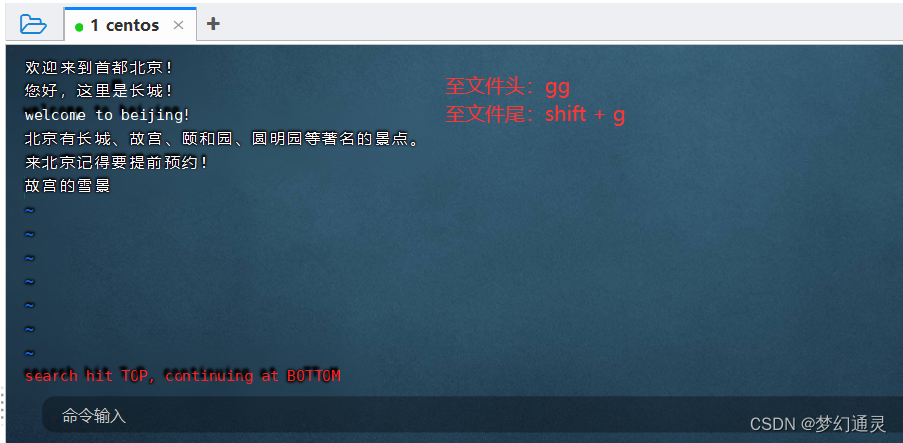
至文件末尾:大写G 或者 shift + g
至文件开头:小写gg
显示当前行号信息,可使用 快捷键 ctrl + g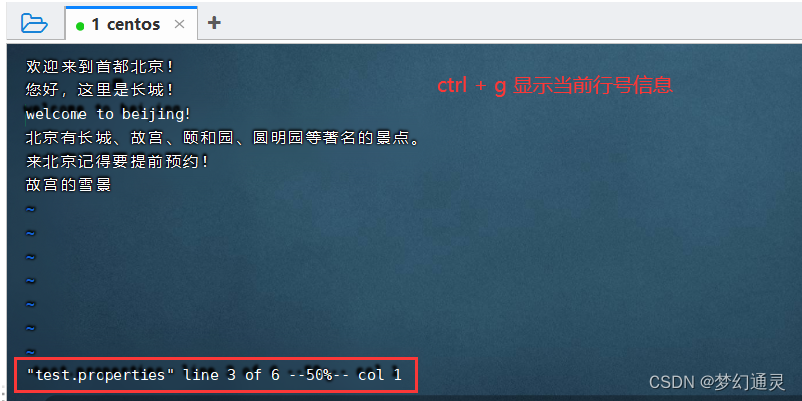
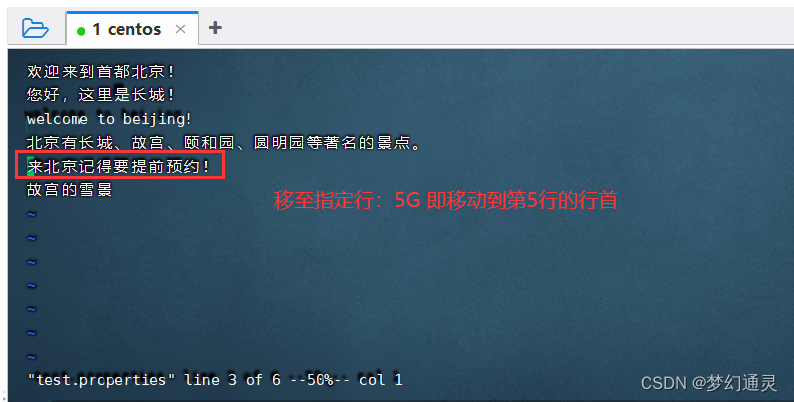
移动到指定行的行首,快捷键 行号+G
三、批量替换
对于相同字符串的批量替换,可借助正则表达式来实现。
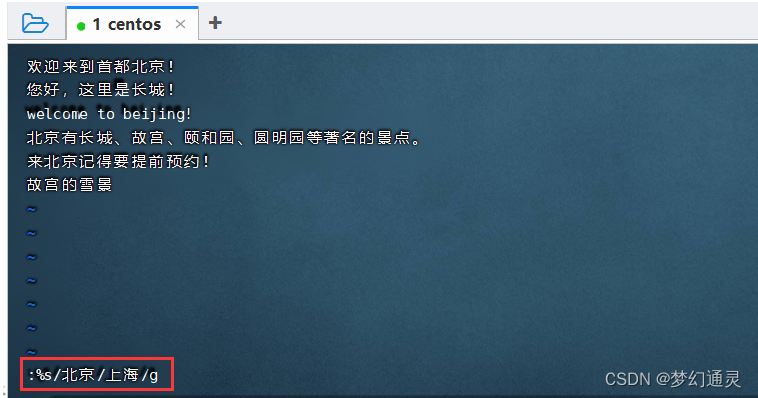
:%s/老字符串/新字符串/g,用上海替换北京,即==:%s/北京/上海/g==
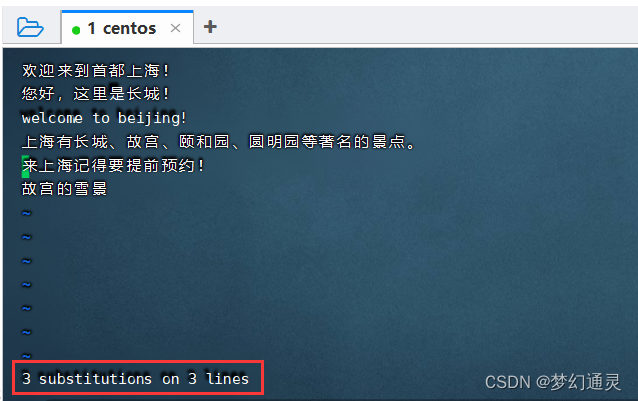
替换成功,显示替换成功的数量。
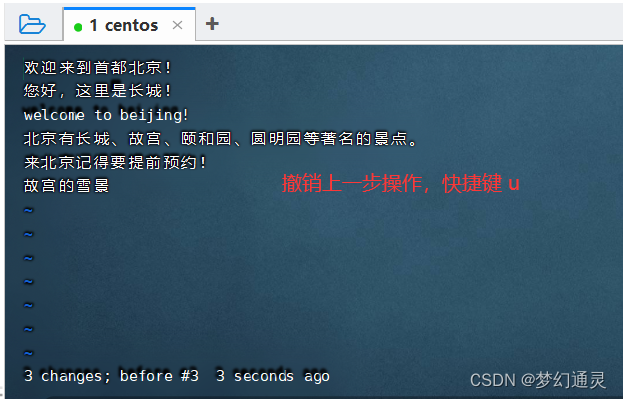
四、撤销上一步操作
在文件操作中可能有误操作,撤销上一次操作可 使用 快捷键 u 来实现。