申请个人主页网站山东省建设厅招标网站首页
PaddleHub
便捷地获取PaddlePaddle生态下的预训练模型,完成模型的管理和一键预测。配合使用Fine-tune API,可以基于大规模预训练模型快速完成迁移学习,让预训练模型能更好地服务于用户特定场景的应用
零基础快速开始WindowsLinuxMac
PaddleHub 首页图像 - 文字识别chinese_ocr_db_crnn_server
chinese_ocr_db_crnn_server
类别图像 - 文字识别
网络Differentiable Binarization+CRNN
数据集icdar2015数据集
模型概述
chinese_ocr_db_crnn_server Module用于识别图片当中的汉字。其基于chinese_text_detection_db_server检测得到的文本框,继续识别文本框中的中文文字。之后对检测文本框进行角度分类。最终识别文字算法采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module是一个通用的OCR模型,支持直接预测。
选择模型版本进行安装
1.2.0 (最新版)
$ hub install chinese_ocr_db_crnn_server==1.2.0chinese_ocr_db_crnn_server
| 模型名称 | chinese_ocr_db_crnn_server |
|---|---|
| 类别 | 图像-文字识别 |
| 网络 | Differentiable Binarization+RCNN |
| 数据集 | icdar2015数据集 |
| 是否支持Fine-tuning | 否 |
| 模型大小 | 116MB |
| 最新更新日期 | 2021-05-31 |
| 数据指标 | mAP@0.98 |
一、模型基本信息
-
应用效果展示
- OCR文字识别场景在线体验
- 样例结果示例:

-
模型介绍
- chinese_ocr_db_crnn_server Module用于识别图片当中的汉字。其基于chinese_text_detection_db_server Module 检测得到的文本框,识别文本框中的中文文字。识别文字算法采用CRNN(Convolutional Recurrent Neural Network)即卷积循环神经网络。该Module是一个通用的OCR模型,支持直接预测。
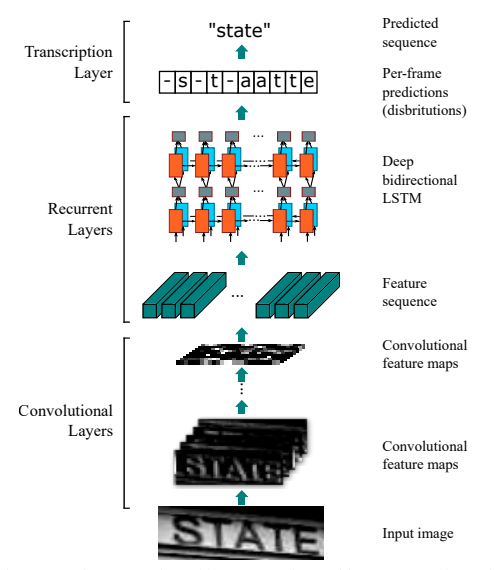
- 更多详情参考:An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition
二、安装
-
1、环境依赖
-
paddlepaddle >= 2.2.0
-
paddlehub >=2.2.0
-
shapely
-
pyclipper
-
$ pip install shapely pyclipper - 该Module依赖于第三方库shapely和pyclipper,使用该Module之前,请先安装shapely和pyclipper。
-
-
2、安装
-
$ hub install chinese_ocr_db_crnn_server
-
三、模型API预测
-
1、命令行预测
-
$ hub run chinese_ocr_db_crnn_server --input_path "/PATH/TO/IMAGE"
-
-
2、预测代码示例
-
import paddlehub as hub import cv2ocr = hub.Module(name="chinese_ocr_db_crnn_server", enable_mkldnn=True) # mkldnn加速仅在CPU下有效 result = ocr.recognize_text(images=[cv2.imread('/PATH/TO/IMAGE')])# or # result = ocr.recognize_text(paths=['/PATH/TO/IMAGE'])
-
-
3、API
-
def __init__(text_detector_module=None, enable_mkldnn=False)-
构造ChineseOCRDBCRNNServer对象
-
参数
- text_detector_module(str): 文字检测PaddleHub Module名字,如设置为None,则默认使用 chinese_text_detection_db_server Module。其作用为检测图片当中的文本。
- enable_mkldnn(bool): 是否开启mkldnn加速CPU计算。该参数仅在CPU运行下设置有效。默认为False。
-
-
def recognize_text(images=[],paths=[],use_gpu=False,output_dir='ocr_result',visualization=False,box_thresh=0.5,text_thresh=0.5,angle_classification_thresh=0.9)-
预测API,检测输入图片中的所有中文文本的位置。
-
参数
- paths (list[str]): 图片的路径;
- images (list[numpy.ndarray]): 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
- use_gpu (bool): 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
- box_thresh (float): 检测文本框置信度的阈值;
- text_thresh (float): 识别中文文本置信度的阈值;
- angle_classification_thresh(float): 文本角度分类置信度的阈值
- visualization (bool): 是否将识别结果保存为图片文件;
- output_dir (str): 图片的保存路径,默认设为 ocr_result;
-
返回
- res (list[dict]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
- data (list[dict]): 识别文本结果,列表中每一个元素为 dict,各字段为: - text(str): 识别得到的文本 - confidence(float): 识别文本结果置信度 - text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标 如果无识别结果则data为[]
- save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为''
- res (list[dict]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
-
-
四、服务部署
-
PaddleHub Serving 可以部署一个目标检测的在线服务。
-
第一步:启动PaddleHub Serving
- 运行启动命令:
-
$ hub serving start -m chinese_ocr_db_crnn_server -
这样就完成了一个目标检测的服务化API的部署,默认端口号为8866。
-
NOTE: 如使用GPU预测,则需要在启动服务之前,请设置CUDA_VISIBLE_DEVICES环境变量,否则不用设置。
-
第二步:发送预测请求
-
配置好服务端,以下数行代码即可实现发送预测请求,获取预测结果
-
import requests import json import cv2 import base64def cv2_to_base64(image):data = cv2.imencode('.jpg', image)[1]return base64.b64encode(data.tostring()).decode('utf8')# 发送HTTP请求 data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]} headers = {"Content-type": "application/json"} url = "http://127.0.0.1:8866/predict/chinese_ocr_db_crnn_server" r = requests.post(url=url, headers=headers, data=json.dumps(data))# 打印预测结果 print(r.json()["results"])
-
-
Gradio App 支持
从 PaddleHub 2.3.1 开始支持使用链接 http://127.0.0.1:8866/gradio/chinese_ocr_db_crnn_server 在浏览器中访问 chinese_ocr_db_crnn_server 的 Gradio App。
五、更新历史
-
1.0.0
初始发布
-
1.0.1
支持mkldnn加速CPU计算
-
1.1.0
使用三阶段模型(文本框检测-角度分类-文字识别)识别图片文字。
-
1.1.1
支持文本中空格识别。
-
1.1.2
修复检出字段无法超过30个问题。
-
1.1.3
移除 fluid api
-
1.2.0
添加 Gradio APP