查看公司信息的网站邯郸人才网
目录:导读
- 前言
- 一、Python编程入门到精通
- 二、接口自动化项目实战
- 三、Web自动化项目实战
- 四、App自动化项目实战
- 五、一线大厂简历
- 六、测试开发DevOps体系
- 七、常用自动化测试工具
- 八、JMeter性能测试
- 九、总结(尾部小惊喜)
前言
Python自动化测试:https://www.bilibili.com/video/BV16G411x76E/
测试基础能力
其实所有的测试大佬都是从底层基础开始的,随着时间,经验的积累慢慢变成大佬。要想稳扎稳打在测试行业深耕,成为测试大牛,首当其冲的肯定就是拥有过硬的基础,所有的基础都是根基,后期所有的发展和提升都是基于测试基础铺垫的。
所以核心的测试理论、测试用例设计方法、测试的方向、测试的分类,从简单的功能测试到高效的自动化测试、再从接口的工具使用,到性能测试。
不管是做web端的项目还是app端的移动测试,都是基于基础,基于理论,基于核心的使用方法,只有拥有过硬的基础能力才能有序的持续发展。
所以所有涉及到测试相关的基础都必须有广度的掌握,然后再进利用经验的积累,进行深度挖掘,非常熟练的使用。
独立负责项目
首先要配得上大佬的称号,必须要相其匹配拥有独立负责一个项目的能力,这里说的独立负责并不是说一个人把整个项目全部测试完,而且全局把控,全局思维,能够把整个项目的业务领域的用户分布,功能特性,使用的具体场景,要有全面的用户意识。
然后进行尽可能全面的测试覆盖。那么独立扶着一个项目上线具体要做那些事情呢?这边把大概项目的进展以及测试的阶段进行一个有序的说明:
1、参与需求评审,进行产品的确认和研发的计划,提出有意义有效益的建议,然后编写测试计划,以及测试方案,和测试策略等。
2、拿到产品原型图以及产品的需求规格说明书(也就说我们常说的需求文档)对需求进行全面的分析,比如有哪些是隐性需求,哪些是显性需求,尽可能的覆盖全面的细节的进行拆分测试点。
然后再拆分过程中,有些不明确以及不清晰的需求可能是技术相关,也可能是没有理解的需求点,要跟产品经理或者项目经理,以及开发人员去进行确认,沟通,明确,然后最终明确核心需求点,再进行有效的拆分。
3、需求拆分之后,进行测试用例的编写,然后执行,可以进行合理的分工,把控全局测试进度,测试范围,测试覆盖率等等,然后再这个阶段可以使用一些持续集成的工具,进行发布任务,管理,操控等来确保工作效率。
然后缺陷报告也就是bug要及时提交到管理平推,对提交的bug进行跟踪,回归等。
4、对整个项目要有风险的把控,延期等等,对质量和进度也要进行合理的平衡,及时反馈,根据具体实际情况进行合理的调整安排。
5、所有测试内容完毕,提交缺陷报告,分析缺陷布局,整体,合理分析项目的软肋优化提升整体的质量。
6、开始发布、上线,发布流程。把上线的步骤,完整的记录详情,确保没有操作失误。
7、公司内部进行测试,也就是常见的阿尔法测试和贝塔测试阶段,核心还是重点进行生产环境的测试,然后就行上线,线上后核心的是日志信息和数据监控,预防问题发生和避免问题出现。
最后进行线上问题的反馈流程等等,然后进行项目复盘,也就是最终的总结大会,主要对项目总体进行一个系统的评估和最终结果进行对比,来帮助后期迭代更新做优化做积淀。
框架代码能力
配套自动化框架:
接口自动化测试方向:Python+requests+pytest+yaml+alluer+Jenkins;
web自动化测试方向:Python+selenium4+pytest+POM+allure+Jenkins;
app自动化测试方向:Python+appium+POM+pytest+allure+Jenkins;
测试框架有很多种类,但是大体上都是大同小异,不管是测试的工具和框架不在于会的多,而是精通几种才是核心目的,因为主要还是以用得最多最高效为基准。
适当的也可以自己取设计测试框架进行扩展和改写加功能都行,很多测试框架都提供了相对于的扩展方式和工具。那么接下来就介绍几种比较常见而且好用的测试框架如下:
Selenium(Web自动化、爬虫)
是一个最为广泛用于Web应用程序自动化(ui自动化)测试的框架,几乎可以模拟用户所有对浏览器进行的操作。
特点:
开源软件:源代码开放可以根据需要来增加工具的某些功能;
跨平台:linux 、windows 、mac;
核心功能:就是可以在多个浏览器上进行自动化测试;
多语言:Java、Python、C#、JavaScript、Ruby等;
成熟稳定:目前已经被google , 百度, 腾讯等公司广泛使用;
功能强大:能够实现类似商业工具的大部分功能,因为开源性,可实现定制化功能;
Pytest(白盒测试,接口自动化,web自动化)
pytest是python的一种单元测试框架,同自带的unittest测试框架类似,相比于unittest框架使用起来更简洁,效率更高
特点:
非常容易上手,入门简单,文档丰富,文档中有很多实例可以参考;
支持简单的单元测试和复杂的功能测试;
支持参数化;
执行测试过程中可以将某些测试跳过,或者对某些预期失败的Case标记成失败;
支持重复执行失败的Case;
支持运行由Nose,Unittest编写的测试CaseG.具有很多第三方插件,并且可以自定义扩展;
方便的和持续集成工具集成;
Appium(移动端的UI自动化测试)
Appium是一个自动化测试开源工具主要用于做app移动端自动化测试的工具,支持iOS和android平台上的移动原生应用、移动Web应用和混合应用。
特点:
移动测试的首选,基本在app自动化测试的工具上使用率占到市场上的90%以上
支持多平台,ios,Android,等等;
支持多种编程语言,比如python,java,c#,js,ruby等等都可以使用;
跨平台工具,它允许测试人员使用同样的接口、基于不同的平台写自动化测试代码,大大增加了测试套件间代码的复用性。
编程代码能力
最少掌握精通一门语言的熟练使用,但是做自动化脚本编写的代码语言首选肯定是python,其次是java,然后附带的除了编程能力之外还有对操作系统的熟练操作除了Windows还有Linux操作系统,以及测试环境的搭建等等也必须掌握得信手捏来。
还有就是数据相关的比如常见的mysql、oracle、sqlserver、sqlite等都必须熟练使用。
性能测试能力
1、对性能测试的基础理论肯定是必须一定熟练掌握的,比如性能测试常见的方法有服务器的性能测试,前端的性能测试,app性能测试等等,以及具体的测试流程也需要熟练掌握使用。
然后要明确常见的性能指标,比如响应时间、TPS、错误率、并发用户数,以及系统资源指标:CPU、内存、IO、网络吞吐量(网络带宽)等等。
2、性能测试压测工具,首选Jmeter,或者LoadRunner,主要的作用是性能测试工具一般用来监测和收集压测中的数据,根据对数据的敏感度发现性能问题。
然后配合开发或者项目经理进行性能调优需要对系统有全面的熟悉以及常见调优的经验要比较丰富,需要不断的思考和摸索定位到性能瓶颈。
其次linux的相关常用命令也要会使用,比如一些监控命令,还有就是服务与容器相关的知识也需要掌握使用,比如常用的Docker命令和部署的原理,Tomcat云服务等等。
其次中间件的话有RabbitMQ、KafKa也要会使用。最后的话就是关于问题定位的分析,还有就是分析调优并且进行各种参数的配置修改等等内容。
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
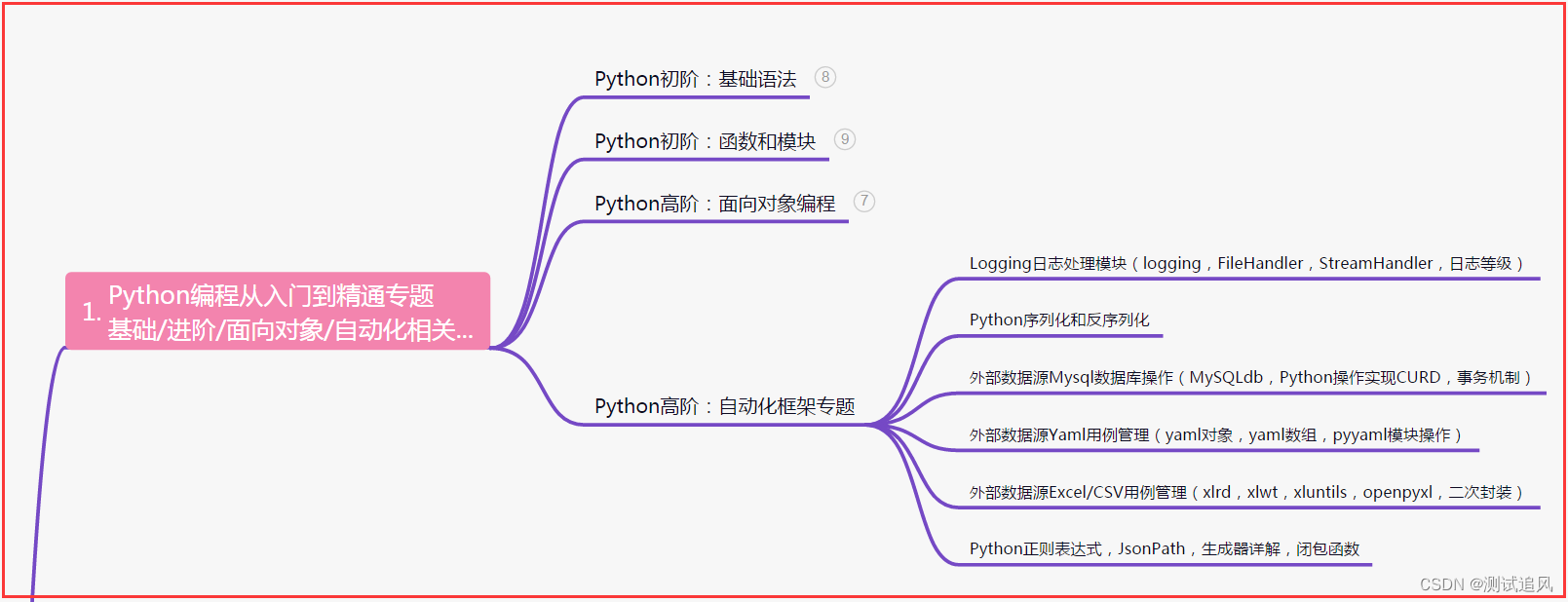
一、Python编程入门到精通
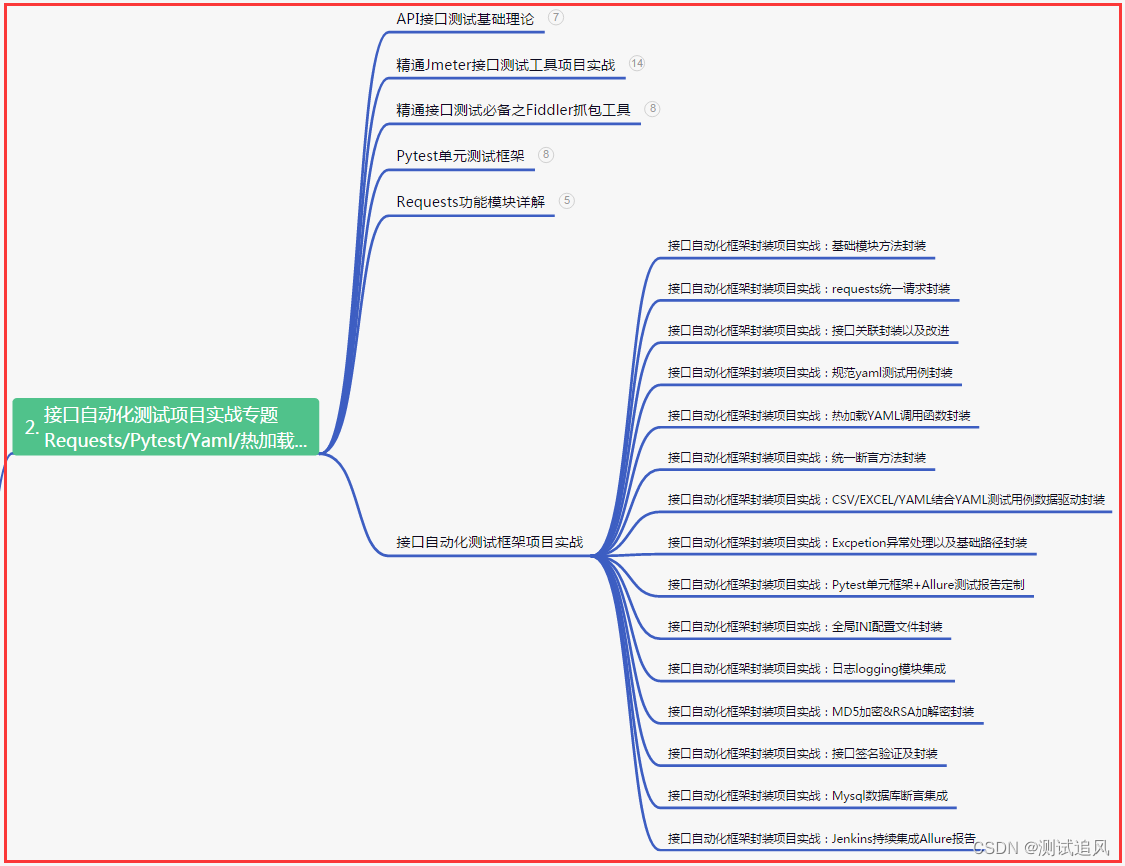
二、接口自动化项目实战
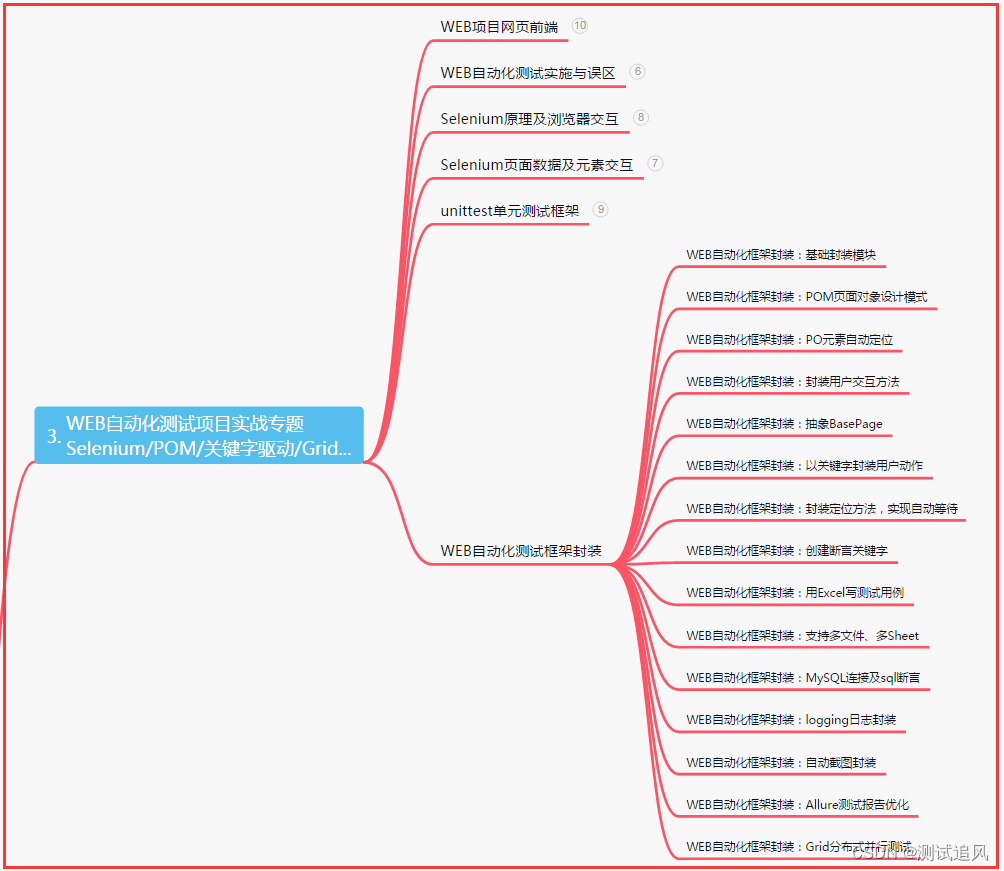
三、Web自动化项目实战
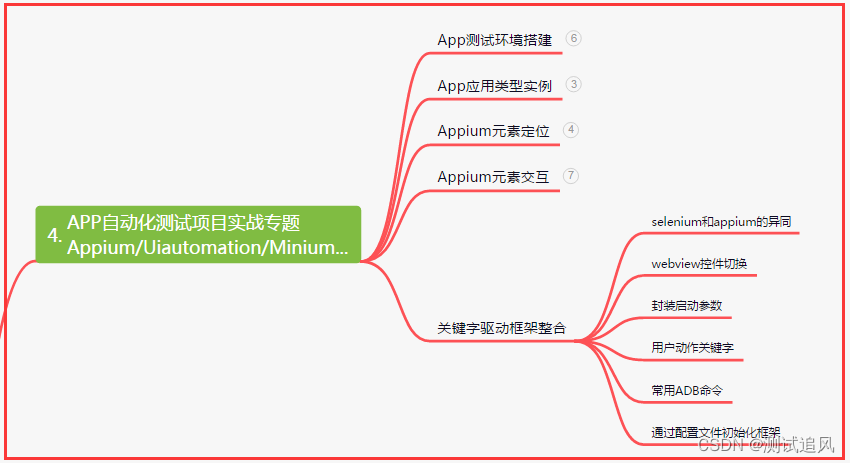
四、App自动化项目实战
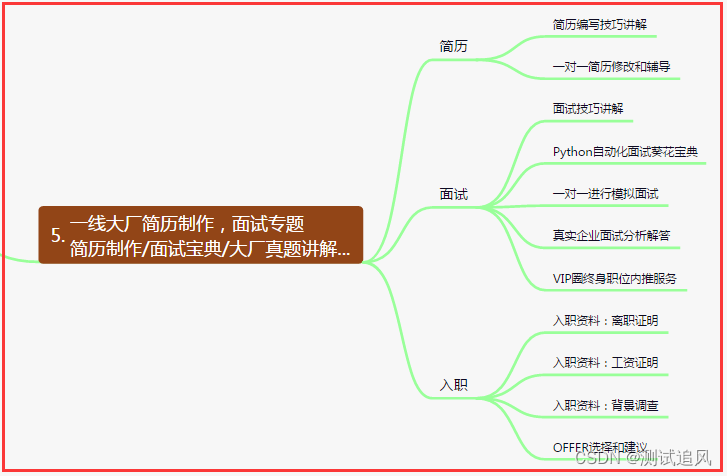
五、一线大厂简历
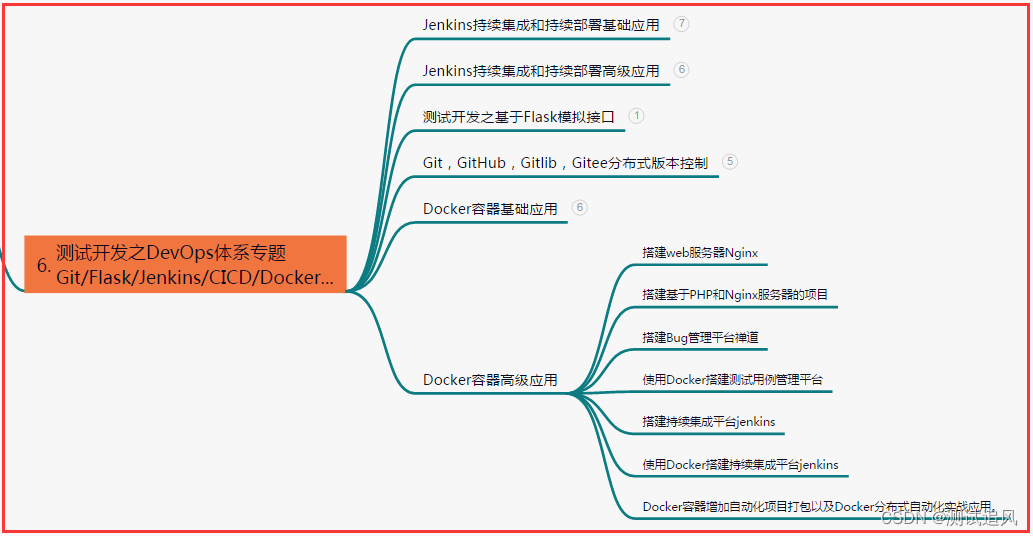
六、测试开发DevOps体系
七、常用自动化测试工具

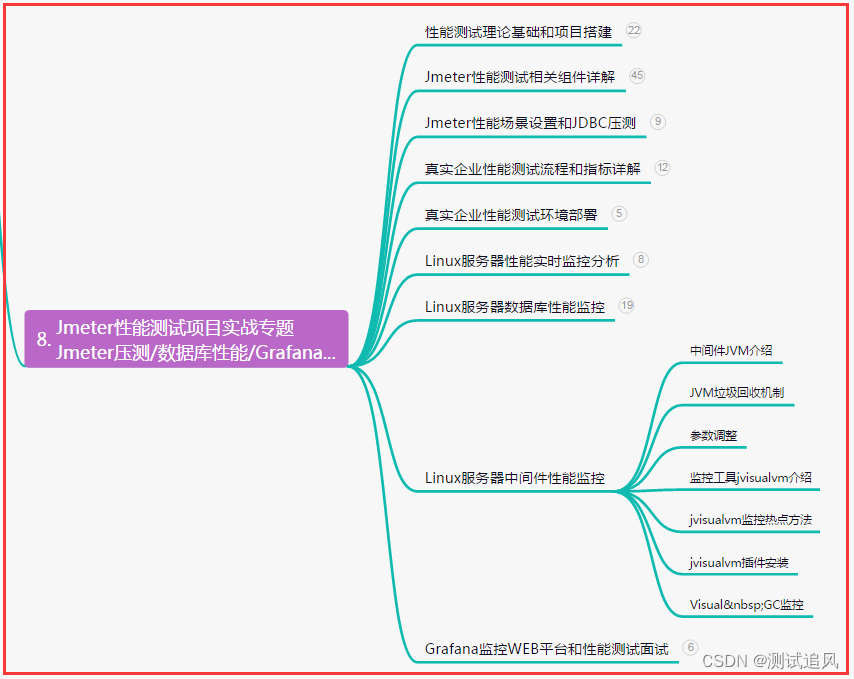
八、JMeter性能测试
九、总结(尾部小惊喜)
不要因为困难而放弃,每一步都在向目标迈进;勇往直前,才能创造奇迹;坚持自己的信仰,成就辉煌人生;只有不断努力,才能实现梦想;成功需要付出代价,但收获也是无限的。
每一次的努力都是一份投资,不要因为追求完美而放弃前进的步伐,勇往直前,才能见证自己的成长。只有坚定不移地坚持下去,你才能超越自我,实现人生的价值。
每一次的奋斗都是值得的,无论成功与否。因为它们让你变得更加坚强、更加有智慧,成为一个更好的自己。不要停下来,继续前行,在你追求的道路上坚定不移。