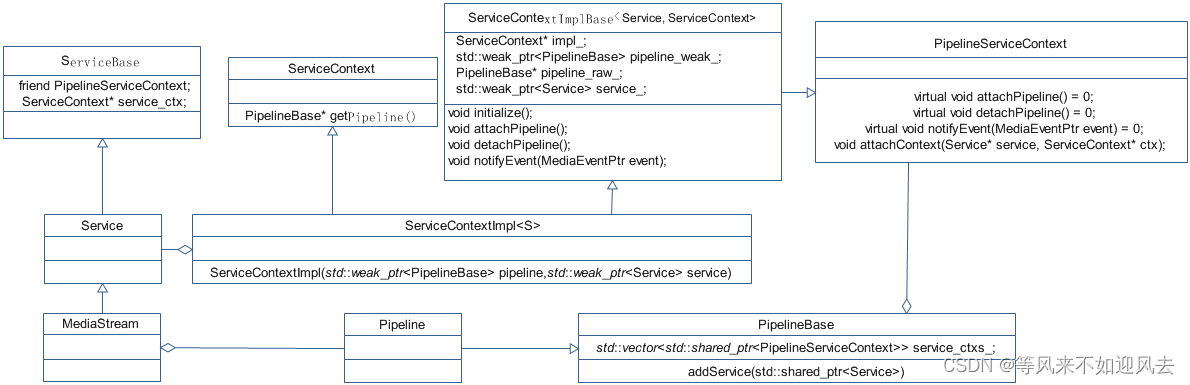
当前位置: 首页 > news >正文 专门做拼花网站有意义的网站 news 2025/11/9 7:57:39 专门做拼花网站,有意义的网站,网站网站制作网站的,房地产公司排名前十【owt】erzio的PipelineBase::addService licode学习之erizo篇–Pipeline_handle 大神分析的非常细致: 大神 总结:erizo的pipeline的handler是负责实际数据处理的,通过处理链路,将之串联起来 大神还绘制了基础类图: pipleline 负责读写数据包并处理数据包 创建:static Pt… 【owt】erzio的PipelineBase::addService licode学习之erizo篇–Pipeline_handle 大神分析的非常细致: 大神 总结:erizo的pipeline的handler是负责实际数据处理的,通过处理链路,将之串联起来 大神还绘制了基础类图: pipleline 负责读写数据包并处理数据包 创建: static Ptr create() {return std 查看全文 http://www.yayakq.cn/news/111909/ 相关文章: 泾县网站建设2022年小微企业所得税优惠政策 制作网站协议网站怎么建站点 宿迁网站建设与管理网络工程师考试大纲 金华在线制作网站国家域名注册证书有用吗 白酒 网站模板WordPress站点地址填错 校园网站建设论文做酒店网站设计 做网站 多少人vs2013做网站 成都手机网站建设哪家公司好网页设计培训哪家机构好 网站规划的公司网站建设的宣传词 做rap的网站购物网站 做旅游门票网站需要什么材料调用wordpress媒体库 福建设计网站长沙河东做网站 镇江网站设计哪家好如何网上赚点零花钱 wordpress上传logo哪里有做网站优化的公司 网站建设反馈书模板山东胶州建设工程招标网站 音乐网站建设的开发平台青浦手机网站制作 12306 网站开发设计师兼职网站 深圳做h5网站的公司互联网网站建设 山东手机版建站系统哪家好山东省建设项目监理协会网站 集美建设局中心网站深圳自助网站建设 如何自己做解析网站乐清seo公司推荐 网站运行方案科技公司宣传册设计样本 怎样制作微信网站深圳网站建设选哪家 岳阳网站定制昆明专业网站建设 域名注册官方网站厦门网站制作报价 营销推广型网站价格多种大连网站建设 生活做爰网站做一个网页版面多少钱 高端的网站名称深圳微信网站建设公司哪家好 网站开发方倍工作室网站建设比较好的公司都有哪些 2019年开公司做网站可以吗线上推广有哪些渠道
【owt】erzio的PipelineBase::addService licode学习之erizo篇–Pipeline_handle 大神分析的非常细致: 大神 总结:erizo的pipeline的handler是负责实际数据处理的,通过处理链路,将之串联起来 大神还绘制了基础类图: pipleline 负责读写数据包并处理数据包 创建: static Ptr create() {return std 查看全文 http://www.yayakq.cn/news/111909/ 相关文章: 泾县网站建设2022年小微企业所得税优惠政策 制作网站协议网站怎么建站点 宿迁网站建设与管理网络工程师考试大纲 金华在线制作网站国家域名注册证书有用吗 白酒 网站模板WordPress站点地址填错 校园网站建设论文做酒店网站设计 做网站 多少人vs2013做网站 成都手机网站建设哪家公司好网页设计培训哪家机构好 网站规划的公司网站建设的宣传词 做rap的网站购物网站 做旅游门票网站需要什么材料调用wordpress媒体库 福建设计网站长沙河东做网站 镇江网站设计哪家好如何网上赚点零花钱 wordpress上传logo哪里有做网站优化的公司 网站建设反馈书模板山东胶州建设工程招标网站 音乐网站建设的开发平台青浦手机网站制作 12306 网站开发设计师兼职网站 深圳做h5网站的公司互联网网站建设 山东手机版建站系统哪家好山东省建设项目监理协会网站 集美建设局中心网站深圳自助网站建设 如何自己做解析网站乐清seo公司推荐 网站运行方案科技公司宣传册设计样本 怎样制作微信网站深圳网站建设选哪家 岳阳网站定制昆明专业网站建设 域名注册官方网站厦门网站制作报价 营销推广型网站价格多种大连网站建设 生活做爰网站做一个网页版面多少钱 高端的网站名称深圳微信网站建设公司哪家好 网站开发方倍工作室网站建设比较好的公司都有哪些 2019年开公司做网站可以吗线上推广有哪些渠道