手机建网站优帮云wordpress设置文章标题
手术麻醉临床信息系统源码,PHP+mysql+laravel+vue2
手术麻醉临床信息系统,采用计算机和通信技术,实现监护仪、麻醉机、输液泵等设备输出数据的自动采集,采集的数据能够如实准确地反映患者生命体征参数的变化,并实现信息高度共享,根据采集结果,综合其他患者数据,自动生成手术麻醉相关医疗文书,以达到提高手术室工作效率的目的,在一定程度上减轻了医护人员书写医疗文书的压力。
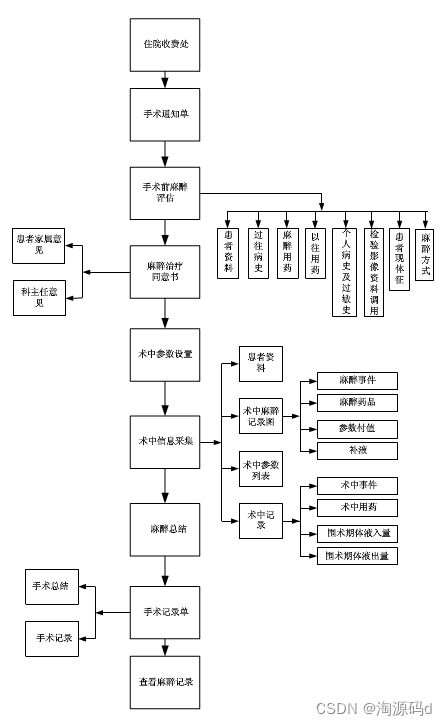
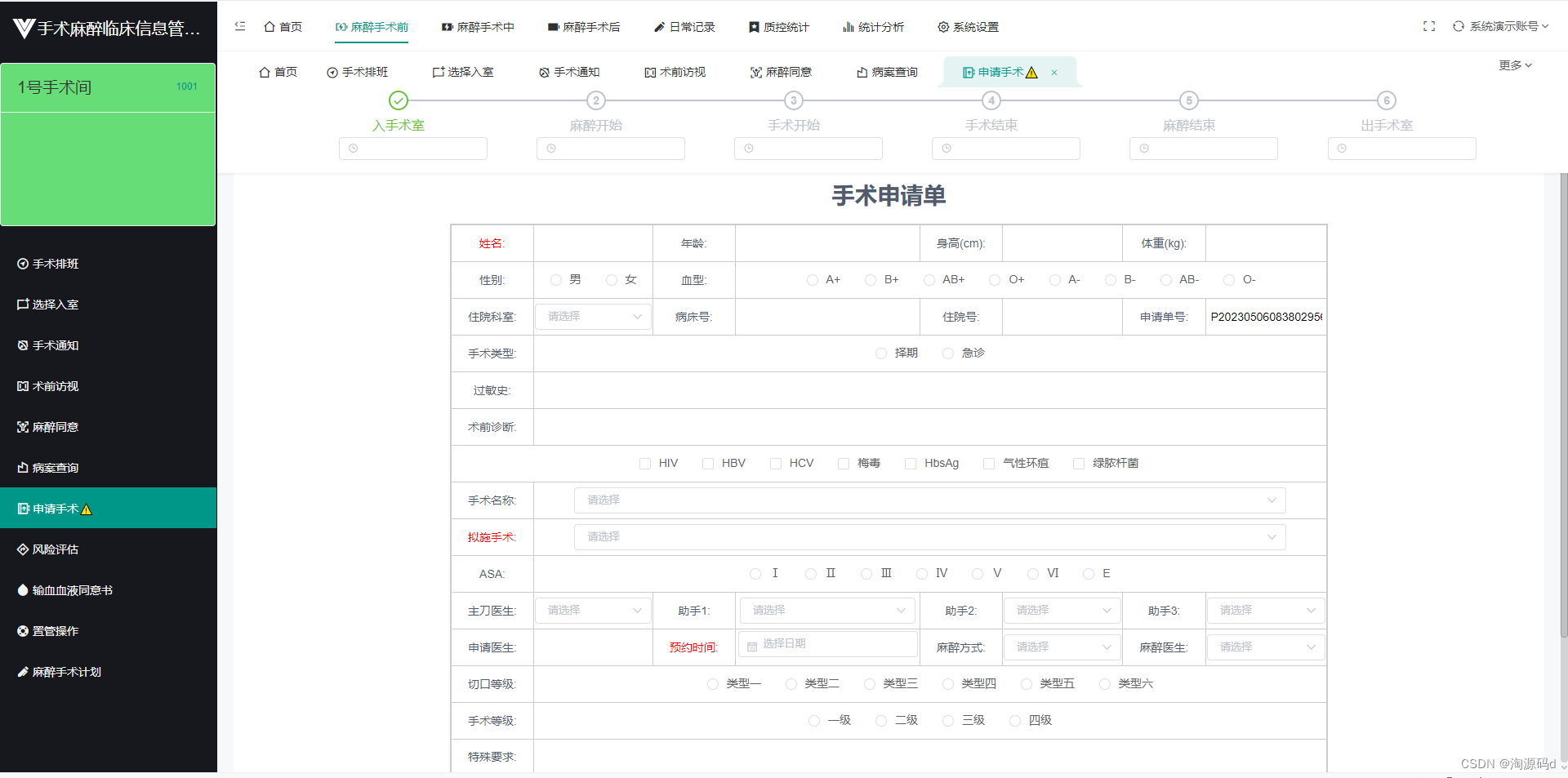
手术室麻醉管理信息系统提供手术申请、申请确认、麻醉会诊、手术安排、术前医嘱、手术医嘱、术后器械清点、术后记帐、术后医嘱及手术病历书写、科室物料及资源的管理,统计及报表等功能,实现对手术麻醉工作的严格管理。
功能特点:
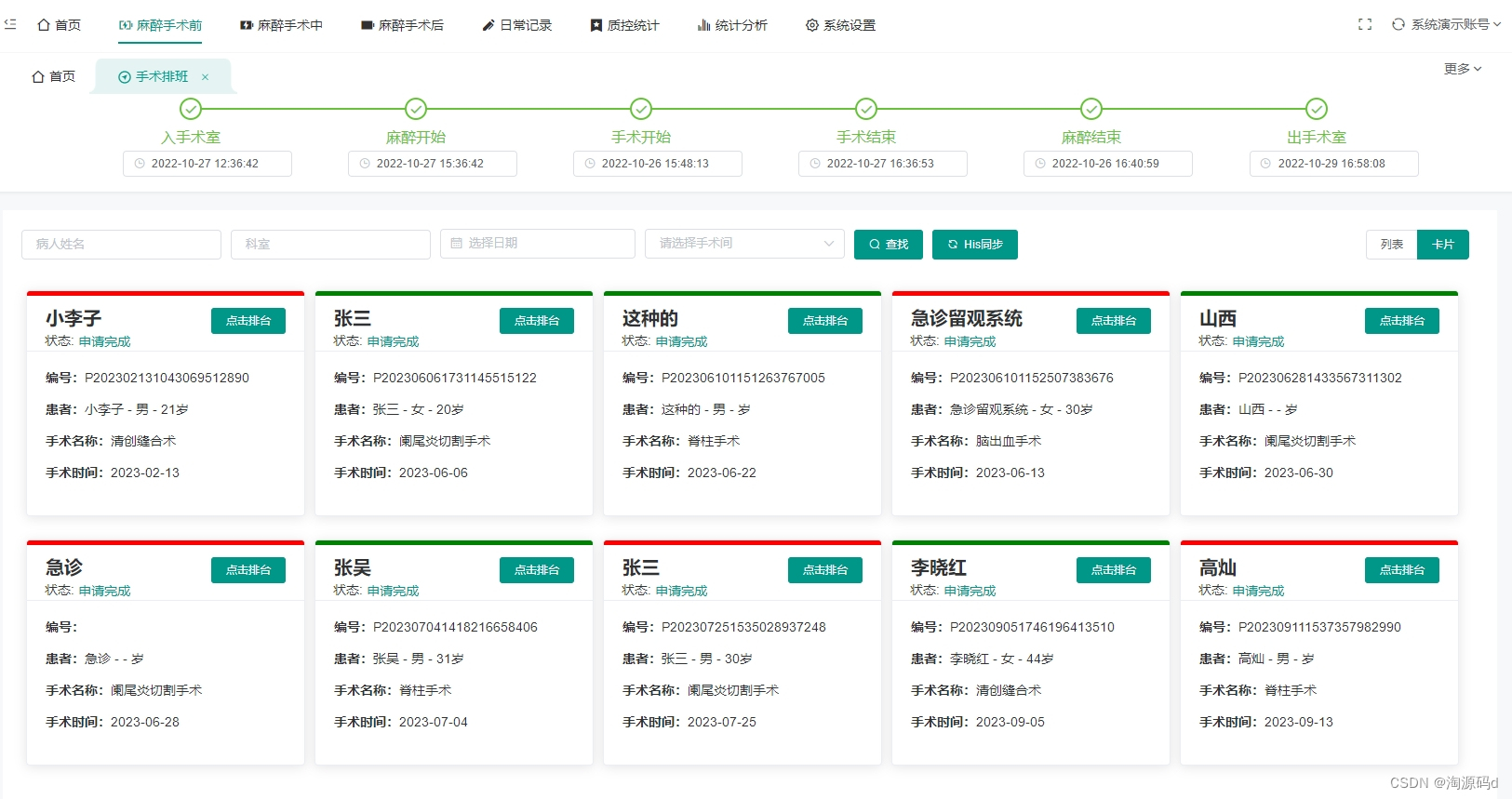
与HIS系统做接口,能实时接收HIS医生工作站发送的门诊或住院(择期、急诊)手术申请单。
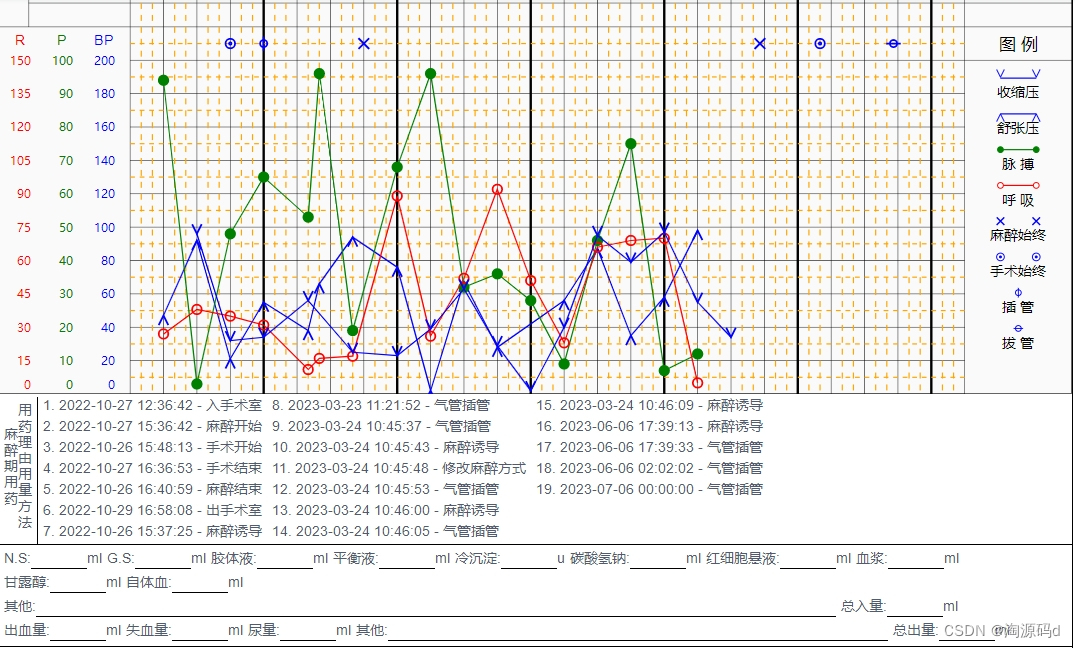
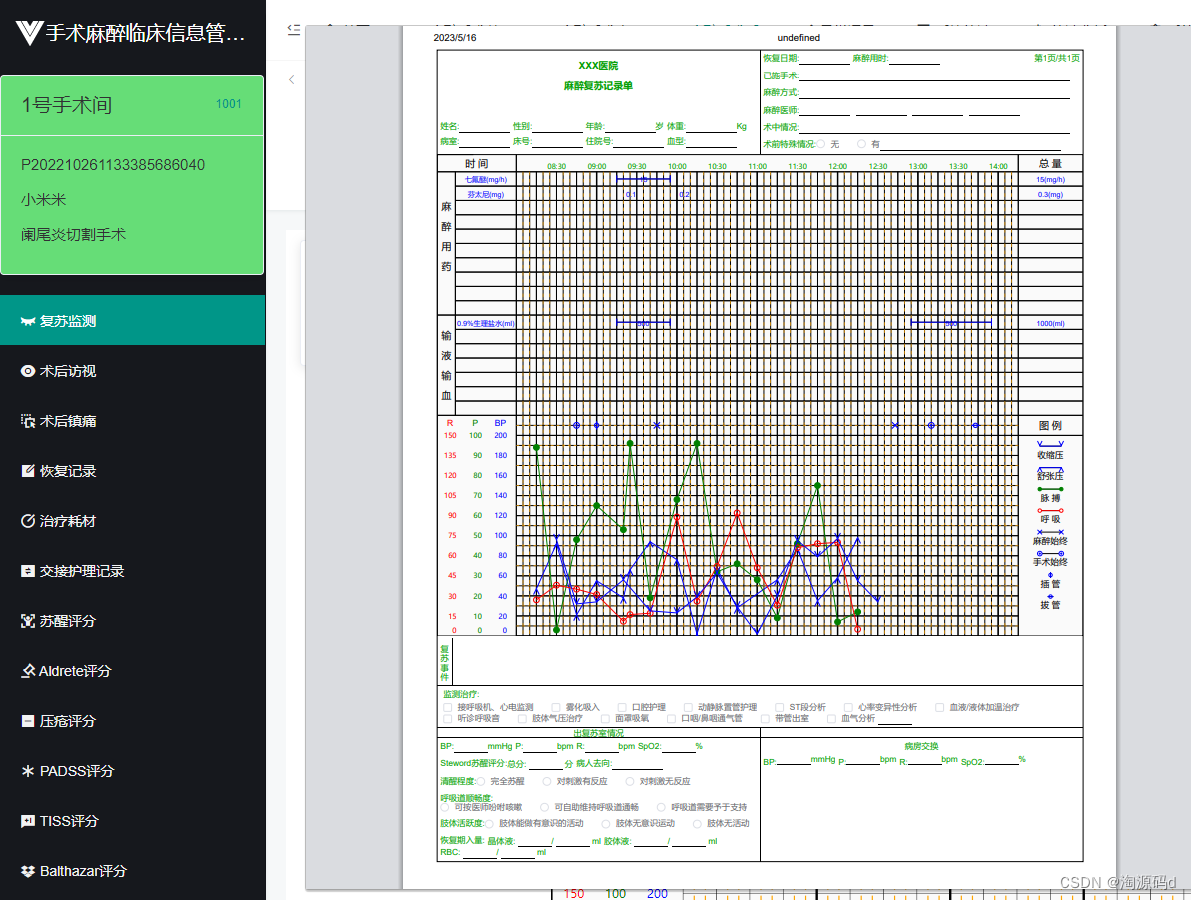
支持麻醉记录单自动生成,支持麻醉时间或麻醉用药快速录入,支持体征参数修正,术中急诊手术管理功能,支持麻醉总结功能。
术后手术登记,医护人员可以在患者信息补录手术信息,记录手术时间、麻醉时间、术者、术中诊断等关键信息,用户可以在术后进行统计分析。
科室工作量统计:系统支持强大的多维度查询功能,用户可以选择输入制定日期范围对不同呢手术科室开展的手术量进行统计,结果按手术大小级别进行分类。能够扩展显示手术医生、手术名称、手术开始结束时间等科室工作量信息。
手术审批权限:对拟施行的不同级别手术以及不同情况、不同类别手术的审批权限。
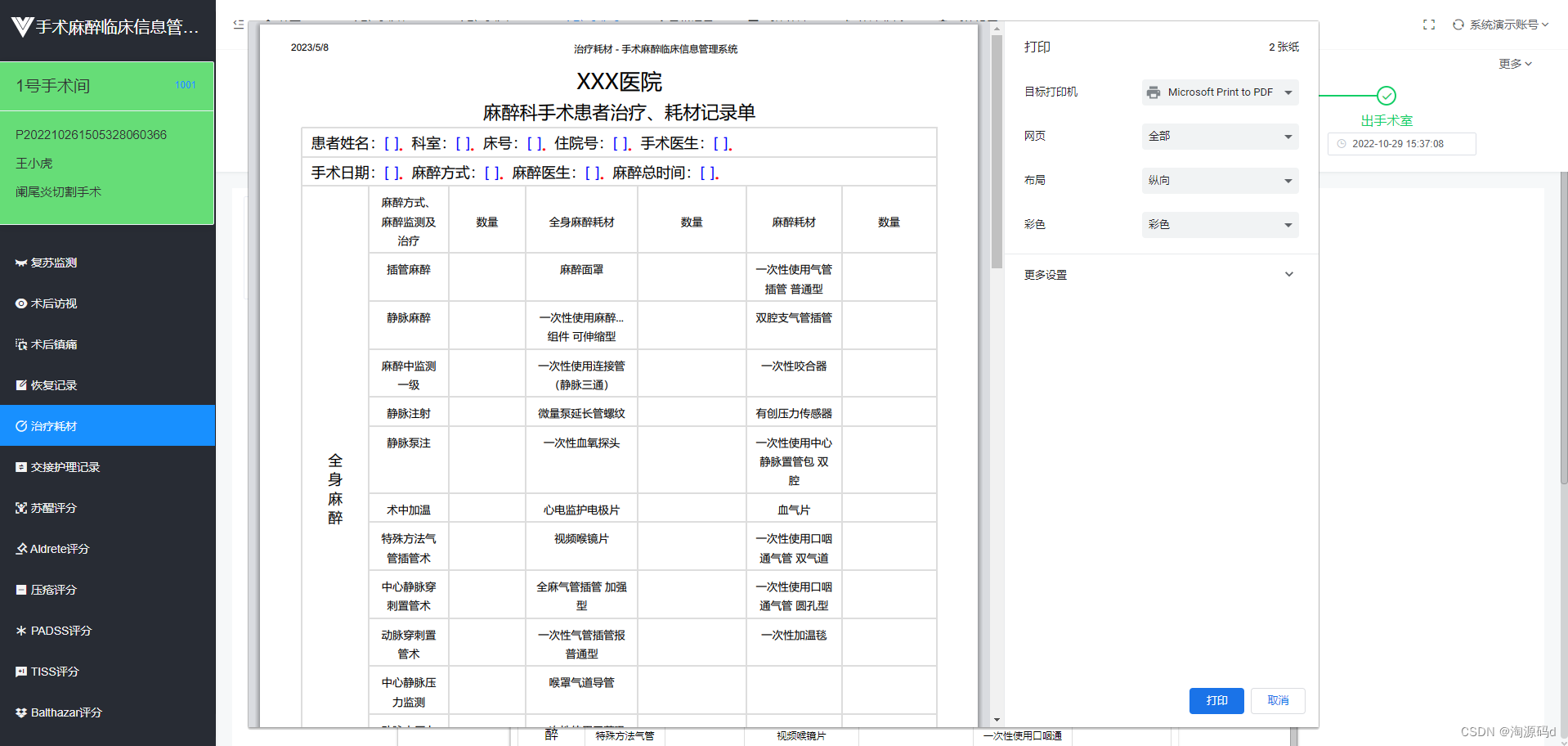
通过索引手段快速将患者麻醉期间产生的麻醉药品、麻醉操作、麻醉耗材、麻醉监测等各类收费项目明细进行录入,并提交至HIS收费系统,完成收费。
应用价值
手术麻醉系统的使用,在一定程度上优化了工作流程,在减轻医护人员劳动强度的同时,提高各科室的工作效率,使得医院的各种医疗文书、统计数据得到规范,提高了信息的准确率,加速医疗信息反馈,增强对医疗活动过程的可控制能力。
实现了麻醉记录电子化。通过临床监护设备(监护仪、麻醉机、输液泵、呼吸机等)的连接,实时采集病人手术和麻醉全过程有关的所有病人临床信息,并实时显示其趋势图,同时与电子病历、HIS、LIS、PACS等系统的无缝连接,实现信息共享,能随时调阅病人的检验、检验结果、影像、既往病史等数据,极大地方便了医护人员。