传统网站建设 成本保险咨询免费
马上就全国计算机等级考试就要开始了,相信现在很多同学都在网上进行报名呢,报名的时候肯定需要用到个人证件照片,所以问题来了,我们怎么自己制作证件照片呢?计算机等级考试报名时对证件照都有哪些要求呢?该怎么让证件照符合这些规定呢?下面小编给大家分享一份具体的证件照制作攻略,有需要的小伙伴一定要仔细看。
首先我们来看看全国计算机等级考试证件照要求
计算机二级证件照片应为考生本人近期正面免冠彩色证件照;照片图像大小最小为192*144(高*宽),彩色,成像区大小为48mm*33mm(高*宽);照片要求存储为jpg格式,图像文件名为*.jpg;照片大小在20-200KB。
下面再来看看具体的证件照制作方法
证件照制作
在浏览器中搜索压缩图网站,打开后从导航栏中选择【证件照制作】。
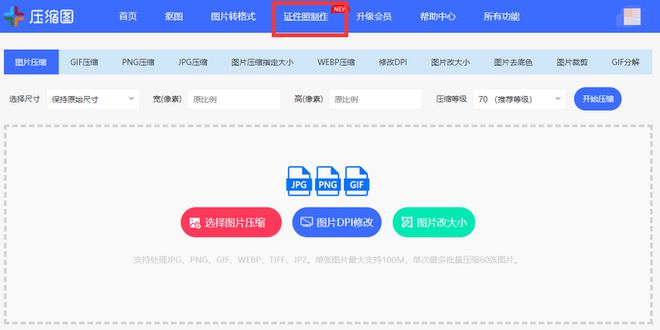
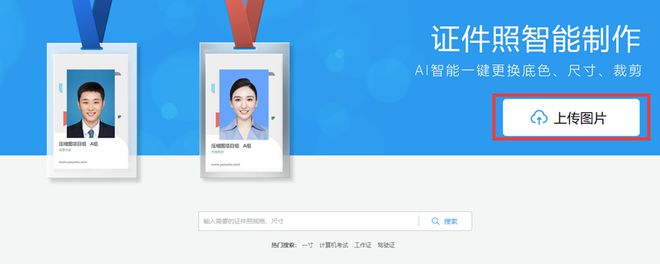
上传图片,选择需要的证件照尺寸、背景颜色,完成后保存即可。

如果我们是只需要给证件照换背景的话,可以这么操作:
在导航栏中选择【证件照换背景】。
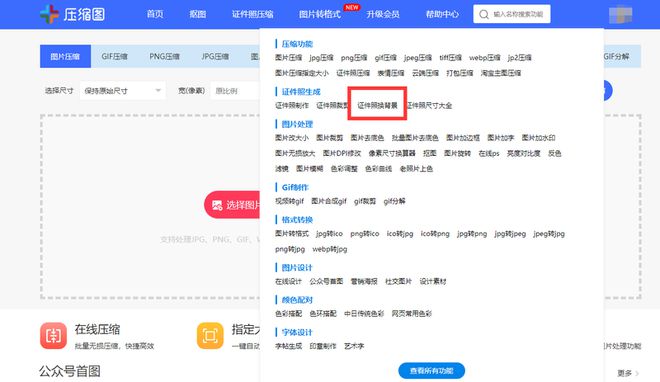
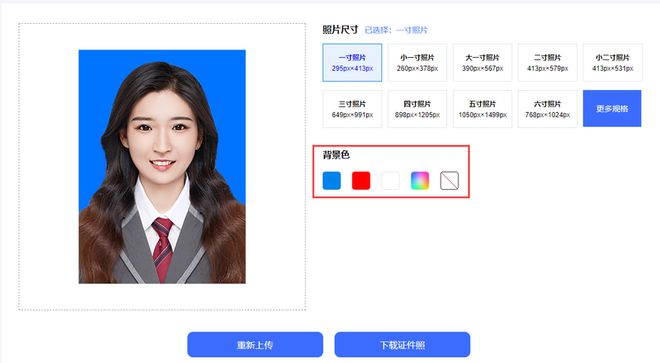
点击上传,选择背景色,处理完成后保存即可。
制作完成后如果发现照片的kb大小超过了平台要求,可以这么操作
使用证件照压缩功能
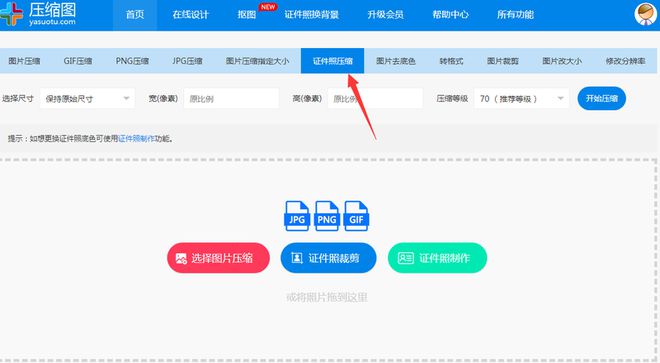
上传证件照,改变压缩等级。
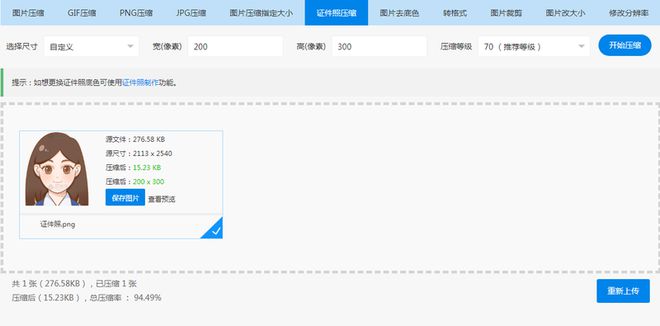
通常报名平台还会对证件照片分辨率有规定
导航栏中选择【修改dpi】。
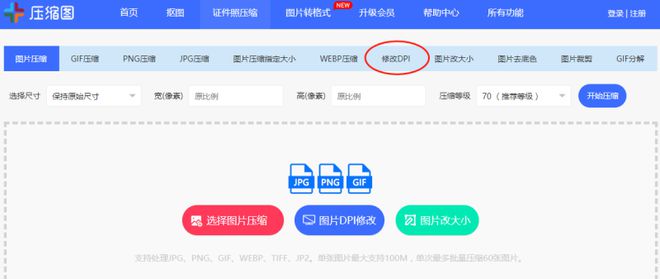
上传图片,将dpi修改设置成需要的数值,点击生成后保存即可。

好啦,以上就是一份超详细的证件照制作相关教程了,看完之后相信同学们都应该知道怎么操作了,有需要的赶紧来压缩图网站操作一下试试吧,希望本篇文章可以帮助到大家,也祝大家考试顺利!