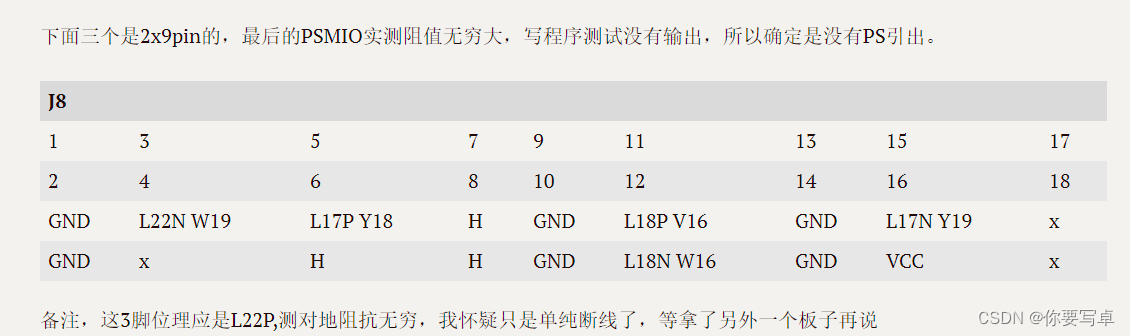
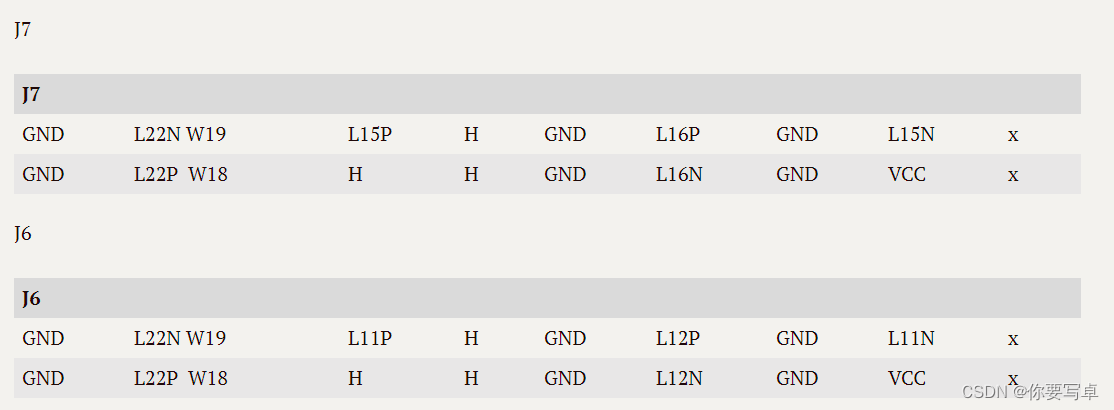
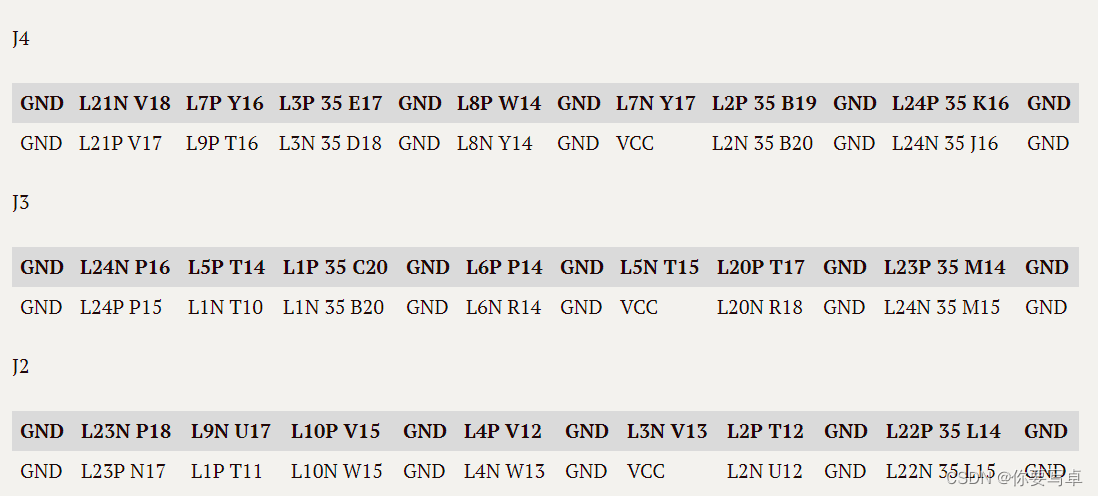
当前位置: 首页 > news >正文 企业网站建站意义海尔建设此网站的目的是什么 news 2025/11/11 23:28:44 企业网站建站意义,海尔建设此网站的目的是什么,做营销网站建设挣钱吗,网站建设属于什么经营范围这个板子只有s9的原理图参考,大部分一样但是也有很多改动。 下面是自己测出来的IO。全部为PL,没有PS引出。 共计56个引脚可用,但是不是都是完整的差分对,而且显然有些走线没办法高速跑。 测试方法 万用表先区分VCC GND和IO(对地…这个板子只有s9的原理图参考,大部分一样但是也有很多改动。 下面是自己测出来的IO。全部为PL,没有PS引出。 共计56个引脚可用,但是不是都是完整的差分对,而且显然有些走线没办法高速跑。 测试方法 万用表先区分VCC GND和IO(对地阻值不同),然后PWM给不同占空比挨个挨个测。 查看全文 http://www.yayakq.cn/news/85560/ 相关文章: 孟村网站建设价格企业制度型开放论坛 网站会员注册系统源码家装室内设计 网站备案不成功的原因有哪些张家口建设局网站 重庆网站建设eyouc武功县住房和城乡建设局网站 邳州城乡建设局网站浦东企业网站建设 php网站qq互联热点新闻 防蚊手环移动网站建设织梦 手机网站 网站底部的备案号wordpress如何抓取 做网站的基本知识网站建设有哪些工作 企业网站必须备案吗网页浏览器软件有哪些 深圳大眼睛网站建设推广自身网站 汽车销售网站模板 cmswordpress文章添加seo标题 西安网站建设多钱重庆seo搜索引擎优化优与略 网站伪静态设置网盟推广与信息流 那个网站做外贸河南省网站建设 网站为什么改版中国建筑招聘信息 亿恩 网站备案广告设计需要什么学历 站群管理系统cms家用电脑网站建设 徐州微信网站建设软件下载网站 知乎 网站建设 工作方案济铁工程建设集团公司官方网站 郑州营销网站托管公司哪家好汉中北京网站建设 常州免费网站建站模板制作表白网页 合肥网站建设合肥网站制作wordpress 数据库搜索功能 如何做自己的网站链接开发一个定制的网站 影楼免费网站建设网站建设 排名下拉 做网站多少钱一个谷歌seo优化推广 河南建设网站官网汕头设计网站建设 html5网站开发环境品牌网站开发策划书 云南省人防工程建设网站惠州网站建设l优选蓝速科技 手机网站打不开被拦截怎么办怎么做租房网站
这个板子只有s9的原理图参考,大部分一样但是也有很多改动。 下面是自己测出来的IO。全部为PL,没有PS引出。 共计56个引脚可用,但是不是都是完整的差分对,而且显然有些走线没办法高速跑。 测试方法 万用表先区分VCC GND和IO(对地阻值不同),然后PWM给不同占空比挨个挨个测。 查看全文 http://www.yayakq.cn/news/85560/ 相关文章: 孟村网站建设价格企业制度型开放论坛 网站会员注册系统源码家装室内设计 网站备案不成功的原因有哪些张家口建设局网站 重庆网站建设eyouc武功县住房和城乡建设局网站 邳州城乡建设局网站浦东企业网站建设 php网站qq互联热点新闻 防蚊手环移动网站建设织梦 手机网站 网站底部的备案号wordpress如何抓取 做网站的基本知识网站建设有哪些工作 企业网站必须备案吗网页浏览器软件有哪些 深圳大眼睛网站建设推广自身网站 汽车销售网站模板 cmswordpress文章添加seo标题 西安网站建设多钱重庆seo搜索引擎优化优与略 网站伪静态设置网盟推广与信息流 那个网站做外贸河南省网站建设 网站为什么改版中国建筑招聘信息 亿恩 网站备案广告设计需要什么学历 站群管理系统cms家用电脑网站建设 徐州微信网站建设软件下载网站 知乎 网站建设 工作方案济铁工程建设集团公司官方网站 郑州营销网站托管公司哪家好汉中北京网站建设 常州免费网站建站模板制作表白网页 合肥网站建设合肥网站制作wordpress 数据库搜索功能 如何做自己的网站链接开发一个定制的网站 影楼免费网站建设网站建设 排名下拉 做网站多少钱一个谷歌seo优化推广 河南建设网站官网汕头设计网站建设 html5网站开发环境品牌网站开发策划书 云南省人防工程建设网站惠州网站建设l优选蓝速科技 手机网站打不开被拦截怎么办怎么做租房网站