哈尔滨网络科技公司做网站网站设计管理方向
目录
1 通过 Maven 创建一个 JavaWeb 工程
2 配置 web.xml 文件
3 创建 SpringMVC 配置文件 spring-mvc.xml
4 创建控制器 HelloController
5 创建视图 index.jsp 和 success.jsp
6 运行过程
7 参考文档
1 通过 Maven 创建一个 JavaWeb 工程
可以参考以下博文:IDEA 2023.2 配置 JavaWeb 工程-CSDN博客![]() https://blog.csdn.net/zjs246813/article/details/136199249导入依赖
https://blog.csdn.net/zjs246813/article/details/136199249导入依赖
<dependencies><!-- Spring 相关依赖--><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.2.7.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-web</artifactId><version>5.2.7.RELEASE</version></dependency><dependency><groupId>org.springframework</groupId><artifactId>spring-webmvc</artifactId><version>5.2.7.RELEASE</version></dependency><!-- Servlet 相关依赖--><dependency><groupId>javax.servlet</groupId><artifactId>servlet-api</artifactId><version>2.5</version><scope>provided</scope></dependency><!-- jsp 相关依赖--><dependency><groupId>javax.servlet.jsp</groupId><artifactId>jsp-api</artifactId><version>2.0</version><scope>provided</scope></dependency><!--单元测试的依赖--><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!-- Spring5和Thymeleaf整合包 --><dependency><groupId>org.thymeleaf</groupId><artifactId>thymeleaf-spring5</artifactId><version>3.0.12.RELEASE</version></dependency>
</dependencies>工程目录
2 配置 web.xml 文件
通过 web.xml 配置 Spring 提供的 CharacterEncodingFilter 过滤器和核心控制器 DispatcherServlet。其中 CharacterEncodingFilter 过滤器用于防止乱码。
关于 Servlet 和 Filter 知识可以看下以下博文:
Tomcat 学习之 Servlet-CSDN博客
https://blog.csdn.net/zjs246813/article/details/136183562?spm=1001.2014.3001.5501Tomcat 学习之 Filter 过滤器-CSDN博客
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_4_0.xsd"version="4.0"><!-- 配置编码过滤器,防止乱码 --><filter><filter-name>encodingFilter</filter-name><filter-class>org.springframework.web.filter.CharacterEncodingFilter</filter-class><!--支持异步处理--><async-supported>true</async-supported><!-- 配置encoding,告诉指定的编码格式,这里设置为UTF-8 --><init-param><param-name>encoding</param-name><param-value>UTF-8</param-value></init-param><!-- 解决请求乱码 --><init-param><param-name>forceRequestEncoding</param-name><param-value>true</param-value></init-param><!-- 解决响应乱码 --><init-param><param-name>forceResponseEncoding</param-name><param-value>true</param-value></init-param></filter><filter-mapping><filter-name>encodingFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping><!-- 配置SpringMVC核心控制器 DispatcherServlet --><servlet><servlet-name>springmvc</servlet-name><servlet-class>org.springframework.web.servlet.DispatcherServlet</servlet-class><!-- 通过初始化参数指定SpringMVC配置文件的位置和名称 --><init-param><param-name>contextConfigLocation</param-name><!-- 使用classpath:表示从类路径查找配置文件,例如maven工程中的src/main/resources --><param-value>classpath:spring-mvc.xml</param-value></init-param><!-- servlet 启动时加载 --><load-on-startup>1</load-on-startup><!--支持异步处理--><async-supported>true</async-supported></servlet><servlet-mapping><servlet-name>springmvc</servlet-name><url-pattern>/</url-pattern></servlet-mapping>
</web-app>3 创建 SpringMVC 配置文件 spring-mvc.xml
配置包扫描和注册视图解析器
当使用 @Controller 或 @RestController 注解来定义控制器,并在控制器方法上使用 @RequestMapping 注解来映射请求路径时,SpringMVC 框架会为 @RequestMapping 注解自动配置必要的组件。如果自定义了一个 Handler 实现类,需要通过<mvc:annotation-driven> 标签启用注解驱动,它会自动添加相应的注解驱动配置。
- RequestMappingHandlerMapping 是负责管理请求 URL 和处理器方法之间映射关系的组件。它会在容器启动时扫描所有的控制器类和方法,解析 @RequestMapping 注解,并建立起请求 URL 与相应处理器方法之间的映射关系
- RequestMappingHandlerAdapter 是负责执行由 RequestMappingHandlerMapping 映射到的处理器方法的组件。它会根据请求的 URL 找到对应的处理器方法,并调用该方法来生成响应
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xmlns:mvc="http://www.springframework.org/schema/mvc"xsi:schemaLocation="http://www.springframework.org/schema/beanshttp://www.springframework.org/schema/beans/spring-beans.xsdhttp://www.springframework.org/schema/contexthttp://www.springframework.org/schema/context/spring-context.xsdhttp://www.springframework.org/schema/mvchttps://www.springframework.org/schema/mvc/spring-mvc.xsd"><!-- 扫描指定包下的注解 --><context:component-scan base-package="com.controller"/><!-- 配置注解驱动,它的主要的作用是:注册映射器HandlerMapping和适配器HandlerAdapter 两个类型的Bean --><!--HandlerMapping的实现为实现类RequestMappingHandlerMapping,它会处理 @RequestMapping 注解,并将其注册到请求映射表中--><!--HandlerAdapter的实现为实现类RequestMappingHandlerAdapter,它是处理请求的适配器,确定调用哪个类的哪个方法,并且构造方法参数,返回值 --><!--在使用SpringMVC是一般都会加上该配置 --><mvc:annotation-driven/><!-- InternalResourceViewResolver 是 SpringMVC 中用于解析和渲染内部资源视图(通常是 JSP 页面)的视图解析器。它根据视图名称查找并加载对应的 JSP 文件,并将模型数据传递给 JSP 进行展示 --><!-- 注册视图解析器 --><bean id="viewResolver" class="org.springframework.web.servlet.view.InternalResourceViewResolver"><!-- 配置前缀 --><property name="prefix" value="/WEB-INF/pages/"/><!-- 配置后缀 --><property name="suffix" value=".jsp"/></bean>
</beans>4 创建控制器 HelloController
package com.thr.controller;import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;@Controller //声明Bean对象,为一个控制器组件
public class HelloController {/*** 1. @RequestMapping 注解是用来映射请求的 URL* 2. 返回值会通过视图解析器解析为实际的物理视图, 对应 InternalResourceViewResolver 视图解析器,它会做如下的解析:* -通过 prefix + returnVal + suffix 这样的方式得到实际的物理视图, 然后做转发操作.* -这里得到的物理视图为:/WEB-INF/pages/success.jsp*/@RequestMapping("/hello")public String sayHello(){System.out.println("Hello SpringMVC");//访问成功后跳转到success页面return "success";}
}5 创建视图 index.jsp 和 success.jsp
index.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8" isELIgnored="false" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><title>Insert title here</title></head><body><a href="${pageContext.request.contextPath}/hello">第一个Spring MVC程序 </a><div>${pageContext.request.contextPath}/hello</div></body>
</html>success.jsp
<%@ page language="java" contentType="text/html; charset=UTF-8"pageEncoding="UTF-8" %>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<html><head><meta http-equiv="Content-Type" content="text/html; charset=UTF-8"><title>Hello</title></head><body><h1>成功访问!!!</h1></body>
</html>6 运行过程
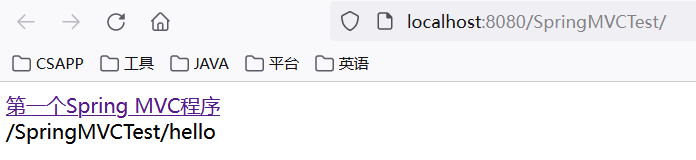
启动 Tomcat,进入首页文件 index.jsp
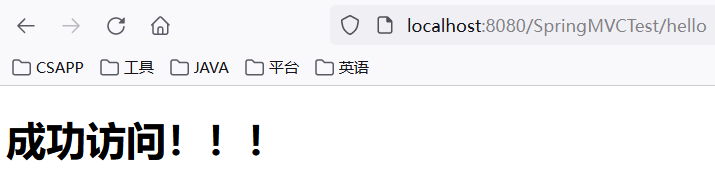
点击链接跳转到 hello.jsp
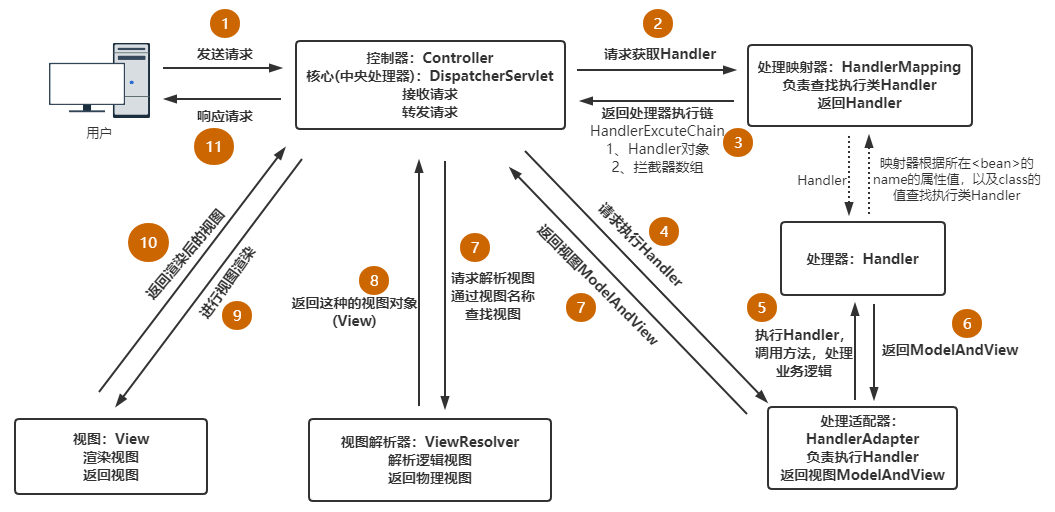
运行过程:
启动 Tomcat,服务器解析 web.xml,创建名称为 encodingFilter 的 CharacterEncodingFilter 过滤器并初始化,创建名称为 springmvc 的 DispatcherServlet (前端控制器)并初始化(DispatcherServlet 的 <load-on-startup> 设置为 1,服务器启动时会创建并初始化),然后进入首页文件 index.jsp,因为过滤器 encodingFilter 的 <url-pattern> 为 /*,会拦截所有请求进行编码设置,之后才显示 index.jsp 的内容。
- 点击链接,客户端请求访问 http://localhost:8080/SpringMVCTest/hello,被 <url-pattern> 为 / 的 DispatcherServlet (前端控制器)拦截处理。
- DispatcherServlet (前端控制器)会读取 SpringMVC 的核心配置文件 spring-mvc.xml,通过扫描组件找到控制器 (HelloController)(@Controller 注解将其标识为一个控制层组件,交给 Spring 的 IoC 容器管理,此时 SpringMVC 才能够识别控制器的存在)。
- HandlerMapping (处理器映射器,该案例中 HandlerMapping 为 RequestMappingHandlerMapping)根据 RequestMapping 注解中的信息(如 value 属性值)来确定 URL 请求应该给哪个 Handler (处理器),@RequestMapping 注解标识的方法在 SpringMVC 中充当处理器的角色,它们负责处理具体的请求并返回相应的响应。
- 由 HandlerAdapter (处理器适配器,该案例中 HandlerAdapter 为 RequestMappingHandlerAdapter)调用由 HandlerMapping(处理器映射器)定位到的处理器,处理器处理请求的方法并返回一个字符串类型的逻辑视图名称 (success)。
- 该逻辑视图名称 (success) 会被视图解析器解析,加上前缀 (/WEB-INF/pages/) 和后缀 (.jsp) 组成物理视图名称,即具体的页面的路径 (/WEB-INF/pages/success.jsp),生成并返回具体对象 View(SpringMVC 封装对象,是一个接口)给 DispatcherServlet (前端控制器)。
- 前端控制器向客户端返回响应。
注:以上为自己理解的过程,有问题 敬请指正!
加一张大家应该都见过的图
7 参考文档
SpringMVC入门学习(二)----SpringMVC的第一个案例 - 唐浩荣 - 博客园 (cnblogs.com)