佛山网站建设公司价格多少做行业网站赚钱吗
一眨眼,初伏就要到来了~办公室内的高温仿佛连空气都凝固了,键盘敲击声似乎都变得沉重而迟缓。在这样的天气下,创意与灵感似乎也躲进了阴凉处,办公效率显然大打折扣。
幸运的是,被我找到了新的应对之策,那便是利用ai写作软件一键生成想要的文本~让原本繁琐的文字工作变得更加轻松快捷,即便是在炎炎夏日,也能保持高效与创造力。
想要知道提效又好用的ai写作软件有哪些吗?接着看下去你便清楚了!

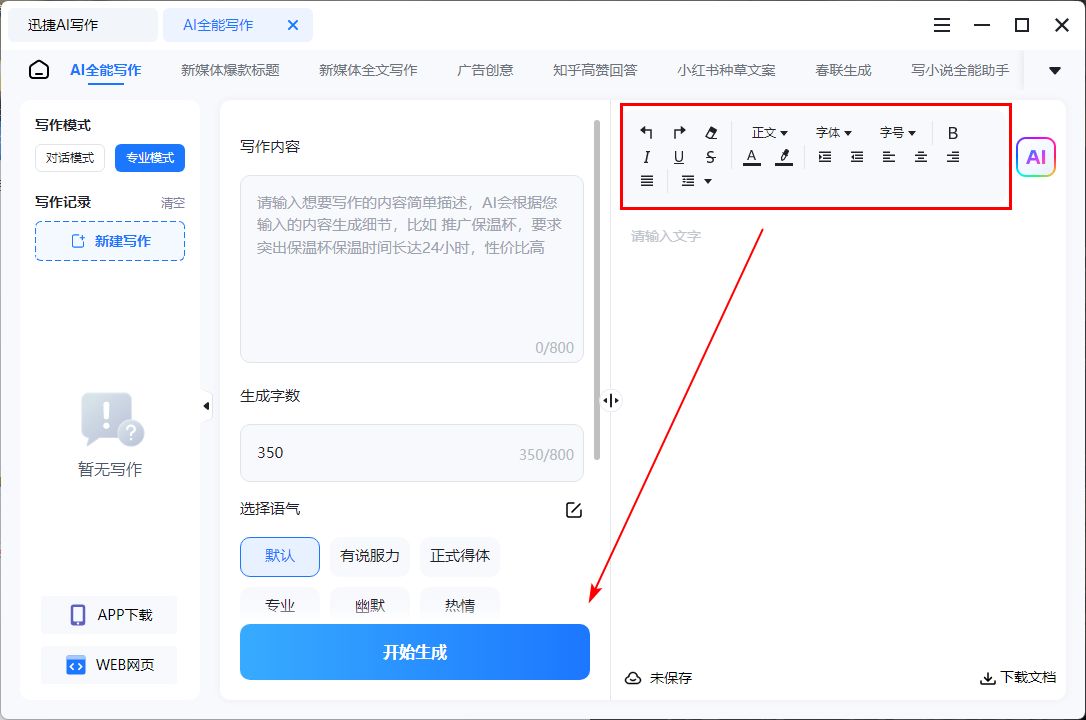
★/01/.迅捷AI写作
◆专为高效写作而生的一个免费ai写作助手,它的核心优势在于能够快速生成内容~无论是博客文章、社交媒体帖子,还是新闻稿、论文,均能在几秒钟内提供初稿。
◆只需给出关键词或主题,即可迅速生成流畅、有逻辑的文本&文章~并且配备多种个性化的操作选项,方便我们创作出更加独特优质的内容。
◆另外,APP、PC和WEB多个端口登录上账号即可同步内容,很是省事。
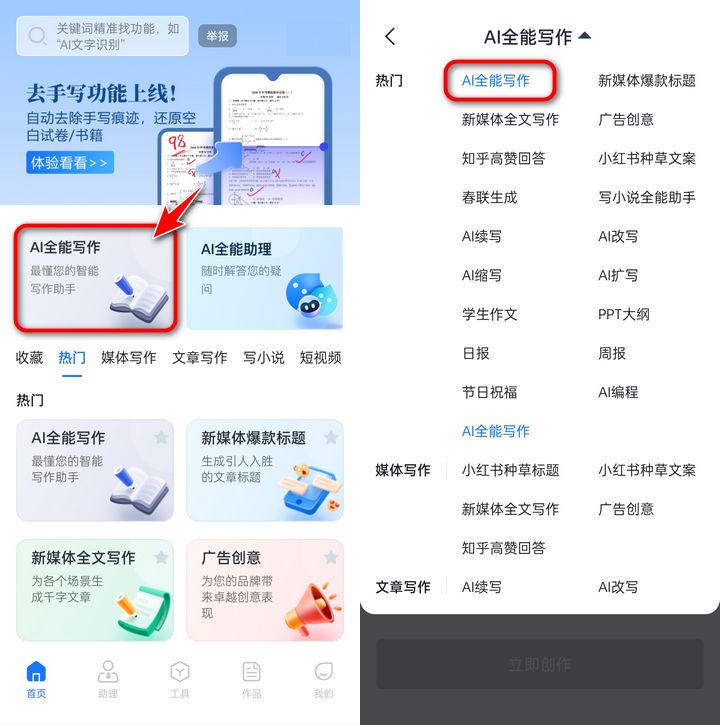
✎适合人群:适用于需要快速生成高质量文章的学生党&上班族&文案人。
★/02/.ContentBot
◆国外一个专注于内容创作的ai写作伙伴~它通过分析我们输入的关键词和主题,即可快速构建内容框架,并填充相关细节。
◆它不仅能提供基础文本,还能根据我们的反馈进行调整,确保内容的原创性和吸引力。
✎适合人群:内容创作者、博主、SEO专家和数字营销人员等群体。
★/03/.Novel AI
◆为小说家和剧本创作者设计的ai写作工具~它能够根据我们设定的角色、情节和风格,来生成引人入胜的故事。
◆它的强大之处就在于其对复杂叙事结构的理解能力,能够帮助作者探索不同的故事走向,创造出多样化的文学作品。
✎适合人群:小说家、剧本作者、故事创作者和任何从事创意文学工作的个人。
★/04/.Moonbeam
◆将创意与效率完美结合的这款ai写作工具,它就特别适合用来辅助完成限定时间内的高质量写作任务。
◆界面简洁直观,轻松地输入指令,便可快速获得写作灵感和草稿内容~内搭的文本润色和校对功能,还可以帮助我们确保最终作品的准确性和流畅性。
✎适合人群:在社交媒体、在线杂志、教育平台和创意行业工作的多媒体内容创作者。

★/05/.Copy AI
◆正如其名,它是一款专注于文案创作的ai工具,能够根据给出的关键词和标题生成吸引人的广告文案和营销材料。
◆在平台自带的数据库中包含了大量的行业术语和表达方式,能够确保生成的文案既专业又具有吸引力。
✎适合人群:营销专业人士、广告策划人员以及任何需要撰写广告文案的朋友。
这下看完这篇文章你知道ai写作软件一键生成哪个好了吧?赶紧用上自己喜欢的ai写作工具提高效率&文章质量吧~