清理网站数据库a+网络推广平台
产品需要在多个环境部署测试,为了提高部署测试效率,故计划使用CD工具,jenkins确实足够强大,但是使用部署功能是需要安装插件的,再说自己本身只用部署功能,故决定找一个小巧的CD工具,经过一番查找,gocd就是我需要的CD工具;
该工具支持 linux 、windows、mac,也有docker镜像; 官方有详细生动的文档;
工具官网 下载页面 文档页面
以debian环境为例进行部署:
1.gocd server部署
wget https://download.gocd.org/binaries/22.3.0-15301/deb/go-server_22.3.0-15301_all.deb
dpkg -i go-server_22.3.0-15301_all.deb
systemctl start go-server
安装完成后通过: http://127.0.0.1:8153/ 访问(默认绑定在0.0.0.0上)
界面如下:
直接跳到了创建pipeline的界面
2.go-agent部署
wget https://download.gocd.org/binaries/22.3.0-15301/deb/go-agent_22.3.0-15301_all.deb
dpkg -i go-agent_22.3.0-15301_all.deb
修改配置文件配置go-server的IP:
/usr/share/go-agent/wrapper-config/wrapper-properties.conf
systemctl start go-agent
成功后即可在服务器端看到agent信息:
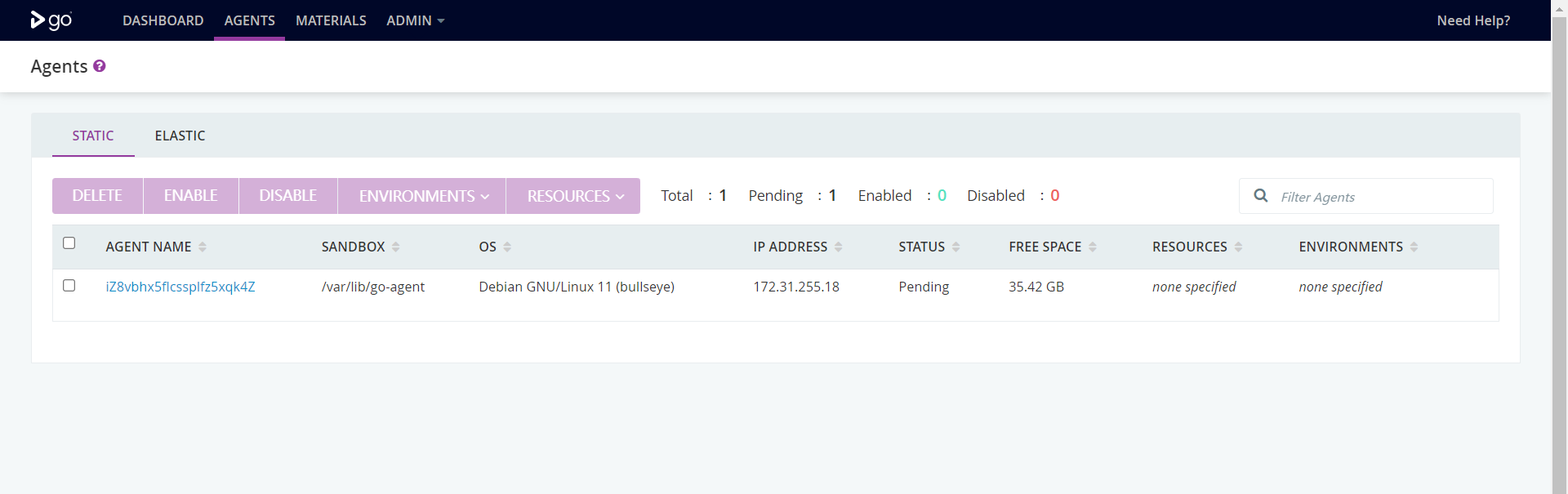
注意: 需要手动enable来启用agent;
3.创建流水线(pipeline)
3.1 物料(material)
物料主要起触发流水线的作用; 包括git、svn等方式(服务器上需要安装git、svn命令),如果确实无法搭建仓库,可以看插件页是否有你需要的方式,我使用的是ftp方式,下载插件后放到 /var/lib/go-server/plugins/external 目录后重启go-server服务即可;
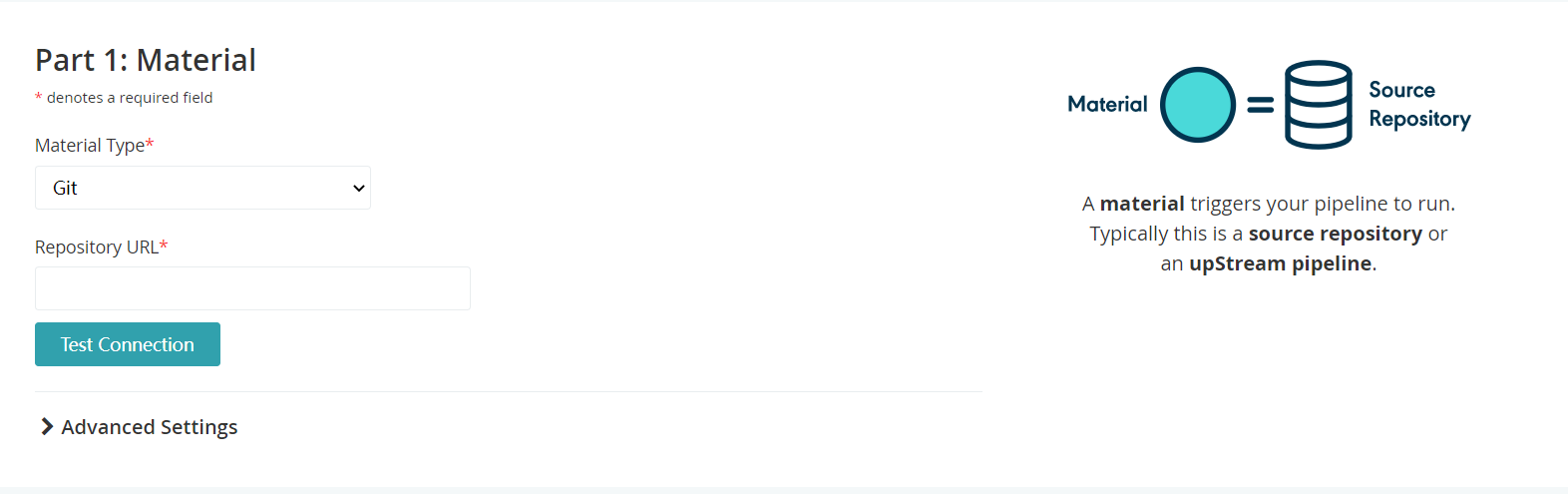
如果你选用的仓库报错: The ref refs/heads/master could not be found.
那么很可能是因为目前一些仓库将mast改名为main的原因,在高级设置里指定branch为main即可;
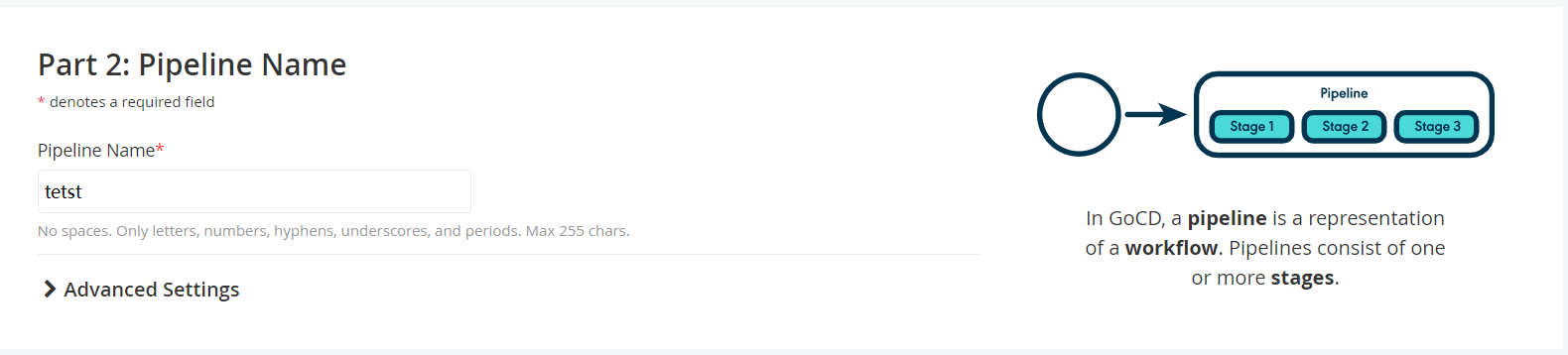
3.2 管道设置
主要配置流水线名称及环境变量即可;
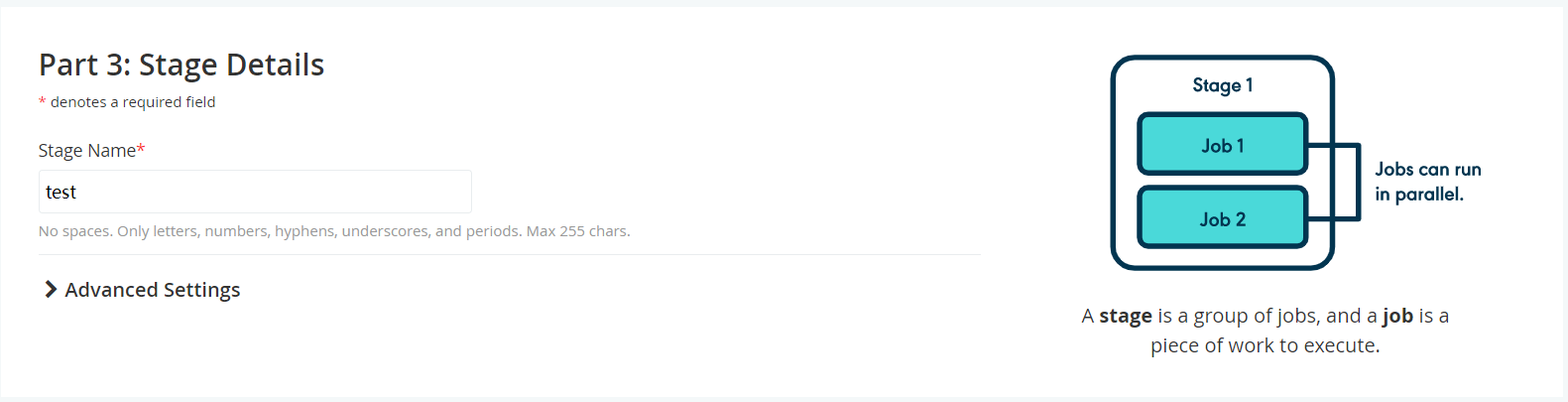
3.3 阶段设置
主要配置阶段名称及环境变量即可;
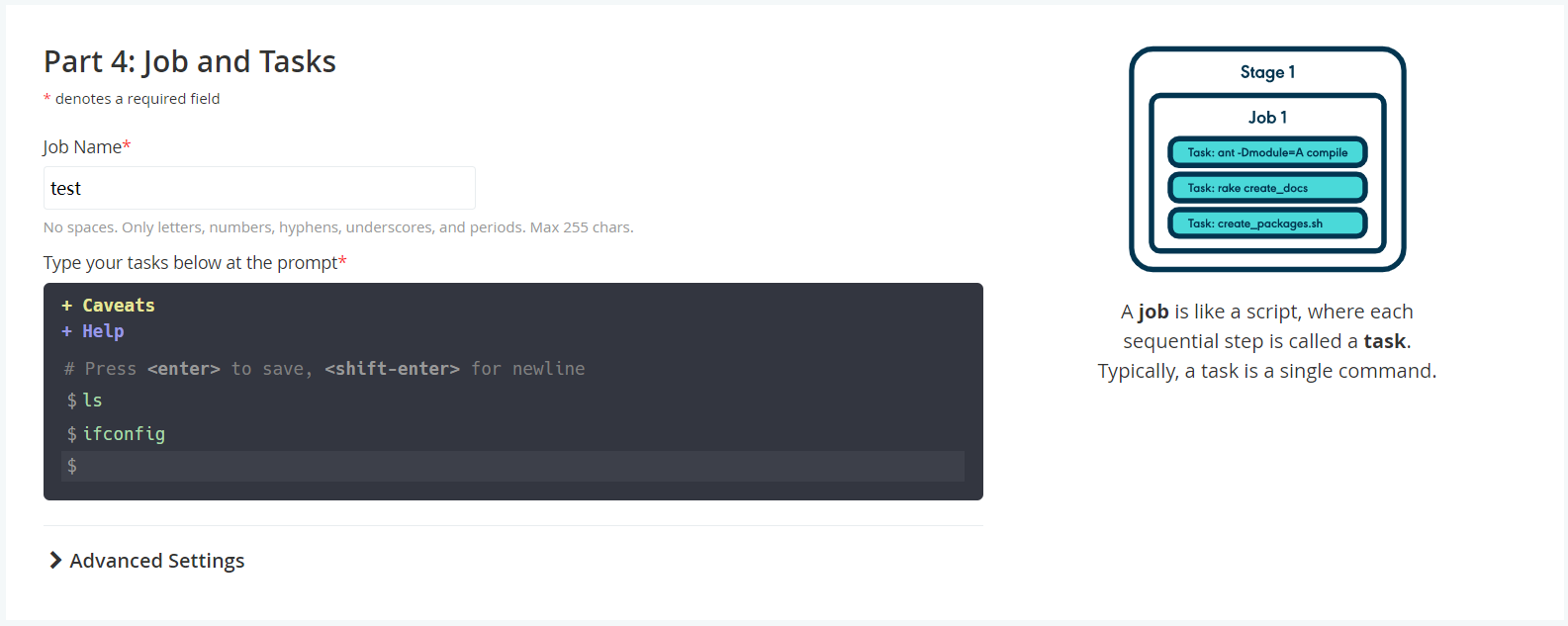
3.4 任务设置
此阶段主要配置命令;
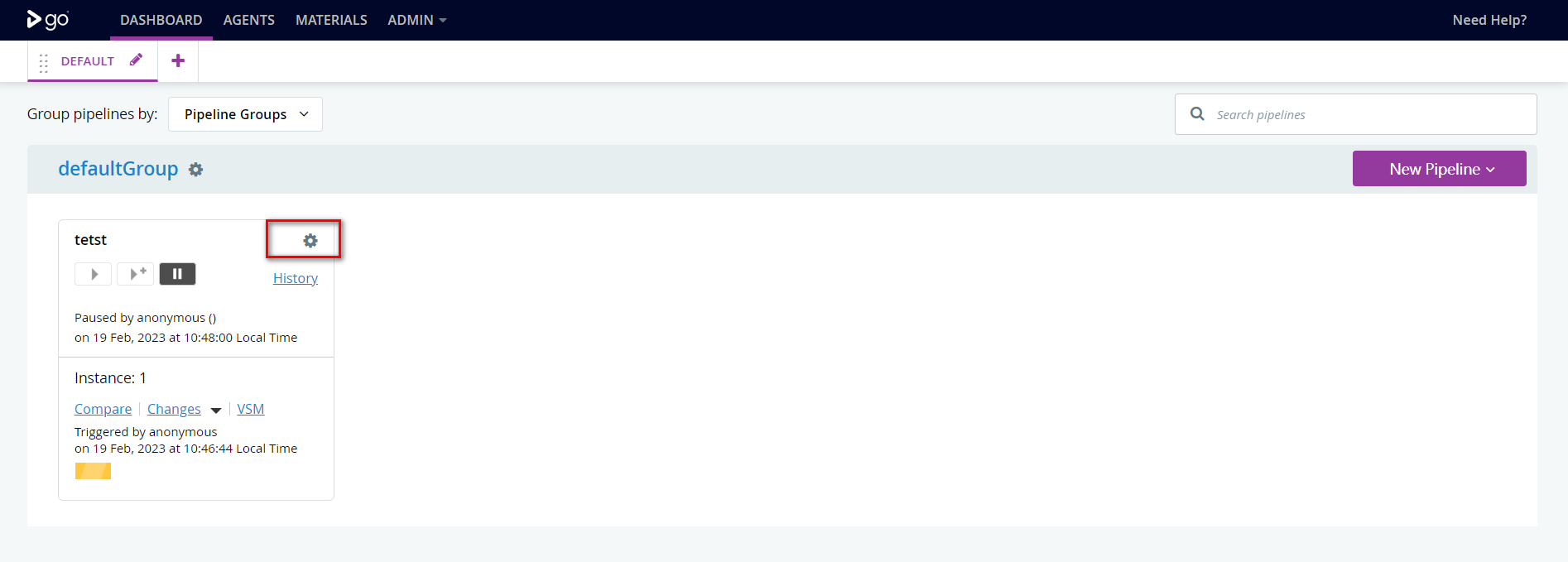
4. 修改流水线
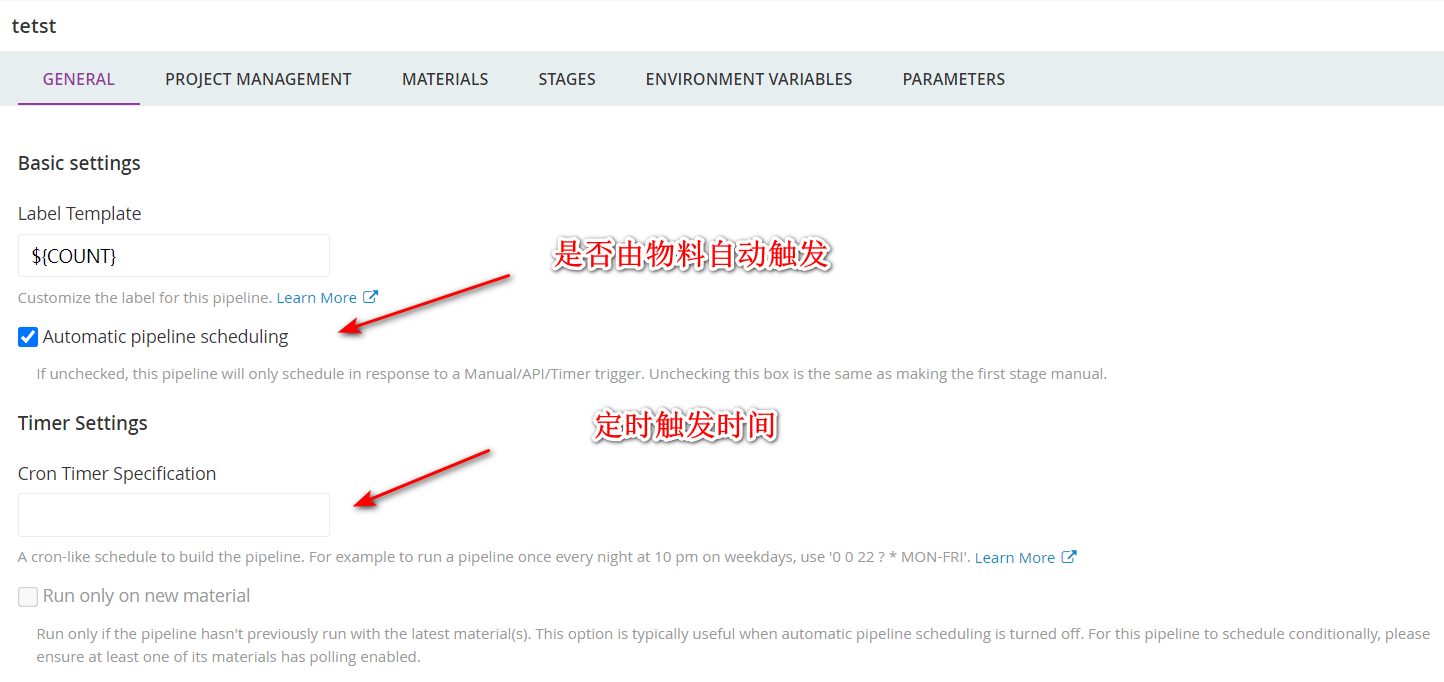
5.执行流水线
根据目前资料来看是1分钟轮询一次;
可以手动触发流水线;
6.用户管理
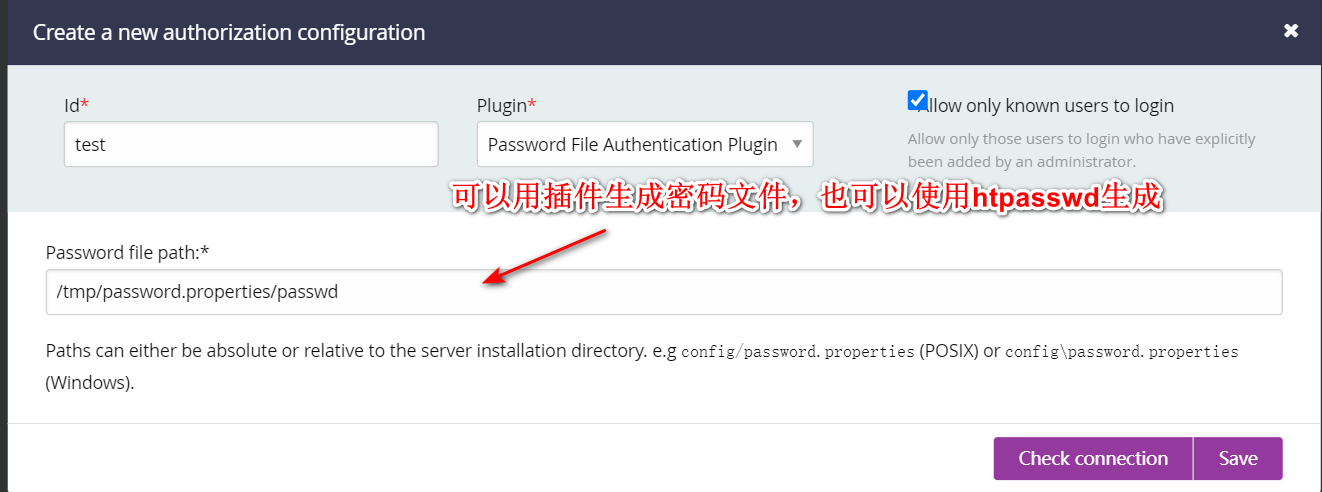
htpasswd创建密码文件:
apt-get install apache2-utils
创建密码文件: htpasswd -c -B passwd user1 创建passwd文件,添加用户user1
htpasswd -B passwd user2 在passwd文件中添加用户user2
添加完毕后如下: