网站做区块链然后往里面投钱下载安卓版app免费下载
这里重新阐述下PageObject设计模式:
PageObject设计模式是selenium自动化最成熟,最受欢迎的一种模式,这里用pytest同样适用
这里直接提供代码:
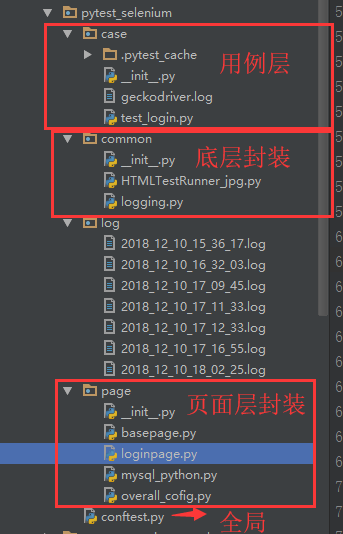
全局变量
conftest.py
"""
conftest.py 全局变量,主要实现以下功能:
1、添加命令行参数broswer, 用于切换不用浏览器
2、全局参数driver调用
"""import pytest
from selenium import webdriverdef pytest_addoption(parser):'''添加命令行参数 --browser'''parser.addoption("--browser", action="store", default="firefox", help="browser option: firefox or chrome")@pytest.fixture(scope='session') # 以实现多个.py跨文件使用一个session来完成多个用例
def driver(request):'''定义全局driver参数'''name = request.config.getoption("--browser")if name == "firefox":driver = webdriver.Firefox()elif name == "chrome":driver = webdriver.Chrome()else:driver = webdriver.Chrome()print("正在启动浏览器名称: %s" % name)# 需要登陆就调用登陆函数def fn():print("当全部用例执行完之后: teardown driver!")driver.quit()request.addfinalizer(fn)return driverloginpage.py
'''
作者:Caric_lee
日期:2018
'''
import timefrom autoTest.pytest_selenium.common.basepage import BasePage
from autoTest.pytest_selenium.common.logging import Log
from autoTest.pytest_selenium.page.mysql_python import Mysql# 获取数据库数据
mysql_test = Mysql('localhost','3306','root','123456','test')
dataAll = mysql_test.query('select * from auto_test')
username = dataAll[0]['username']
password = dataAll[0]['password']
url = dataAll[0]['url']
print("查询数据库信息 账号: %s, 密码: %s, url: %s" % (username, password, url))class Login(BasePage):log = Log()# 断言登录页,提示文本hint_text_element = ('xpath', "//*[@class='crm-login1-header']/h1")hint_text = '登录销售易'# 断言忘记密码forget_paw_elemet = ('xpath', "//*[text()='忘记密码?']")forget_paw = '忘记密码'# 断言免费注册Free_registration_element = ('xpath', "//*[text()='免费注册']")Free_registration_text = '免费'# 断言'欢迎登录销售易'tenant_interface = ('xpath', "//*[text()='欢迎登录销售易']")tenant_interface_text = '欢迎登录'# 元素定位input_username_element = ('xpath', "//*[@name='loginName']")input_paw_element = ('xpath', "//*[@placeholder='请输入密码']")click_enter_element = ('xpath', "//*[text()='登 录']")clikc_tenant_element = ('xpath', "//span[text()='自动化测试_0202_1109_正式' and @class='crm-company-name']")def assert_title(self):result = self.is_text_in_element(self.hint_text_element, self.hint_text)self.log.info("assert: 断言登录页,提示文本: %s" % result)def assert_forget_paw(self):result = self.is_text_in_element(self.forget_paw_elemet, self.forget_paw)self.log.info("assert: 断言忘记密码: %s" % result)def assert_Free_registration(self):result = self.is_text_in_element(self.Free_registration_element, self.Free_registration_text)self.log.info("assert: 断言免费注册: %s" % result)def input_username(self, username):self.send_keys(self.input_username_element, username)def input_paw(self, paw):self.send_keys(self.input_paw_element, paw)def click_enter(self):self.click(self.click_enter_element)def assert_tenant_interface(self):result = self.is_text_in_element(self.tenant_interface, self.tenant_interface_text)self.log.info("assert: 欢迎登录销售易: %s" % result)def move_scroll_end(self):time.sleep(3)self.js_focus_element(self.clikc_tenant_element) # 这里已经可以实现滚动了self.log.info("聚焦滚动结束!")def click_tenant(self): # 选择租户self.click(self.clikc_tenant_element)self.log.info("选择租户成功!")def login(self, username=username, paw=password):'''登录流程'''self.assert_title() # 断言登录页,提示文本self.assert_forget_paw() # 断言忘记密码self.assert_Free_registration() # 断言免费注册self.input_username(username)self.input_paw(paw)self.click_enter()time.sleep(3)self.assert_tenant_interface() # 断言'欢迎登录销售易'print("---------------------->>>>>>>>>>>>>")self.move_scroll_end()self.click_tenant()if __name__=='__main__':from selenium import webdriverdriver = webdriver.Chrome()base = Login(driver)driver.get(url)driver.maximize_window()driver.implicitly_wait(10)base.login()# 学习备注!# 调试某个功能的时候,就只写这个功能点的代码去调# 加载转圈是js报错了,前端的问题,是bug (滚动条)test_login.py
'''
作者:Caric_lee
日期:2018
'''
from autoTest.pytest_selenium.page import loginpage
from autoTest.pytest_selenium.page.loginpage import Login
import pytest, timeclass Test_login():url = loginpage.urlusername_data = loginpage.usernamepaw_data = loginpage.passwordprint("调用信息 账号: %s, 密码: %s, url: %s" % (username_data, paw_data, url))@pytest.fixture(scope="function", autouse=True) # function 默认参数传递,autouse=True 自动调用fixture功能def test_01(self, driver):driver.get(self.url)driver.maximize_window()driver.implicitly_wait(10)self.login = Login(driver)def test_02(self):'''登录'''# 1、断言登录页,提示文本self.login.assert_title()# 2、断言忘记密码self.login.assert_forget_paw()# 3、断言免费注册self.login.assert_Free_registration()# 4、输入账号self.login.input_username(self.username_data)# 5、输入密码self.login.input_paw(self.paw_data)# 6、点击登录self.login.click_enter()time.sleep(3)# 7、断言'欢迎登录销售易'self.login.assert_tenant_interface()# 8、滚动到底部self.login.move_scroll_end()# 9、点击租户self.login.click_tenant()time.sleep(5)def test_03(self, driver):time.sleep(5)driver.quit()if __name__ == '__main__':# 选择测试浏览器pytest.main(["-s", "--browser=chrome", "test_login.py"])这里直接指向test_login.py文件就OK了,
还可以在优化,把loginpage中的读取数据库信息,单独写个方法,放在page里面,直接读取。
数据结构还需要在调整
这可能是B站最详细的pytest自动化测试框架教程,整整100小时,全程实战!!!