自己做网站 如何推广wordpress少儿主题
c++ less 函数在不同的地方感觉所起的作用是不一样的, 这中间原因是 less 的视角不一样, 下面尝试给出解释下, 方便记忆
1、 左右视角
符合
排序sort
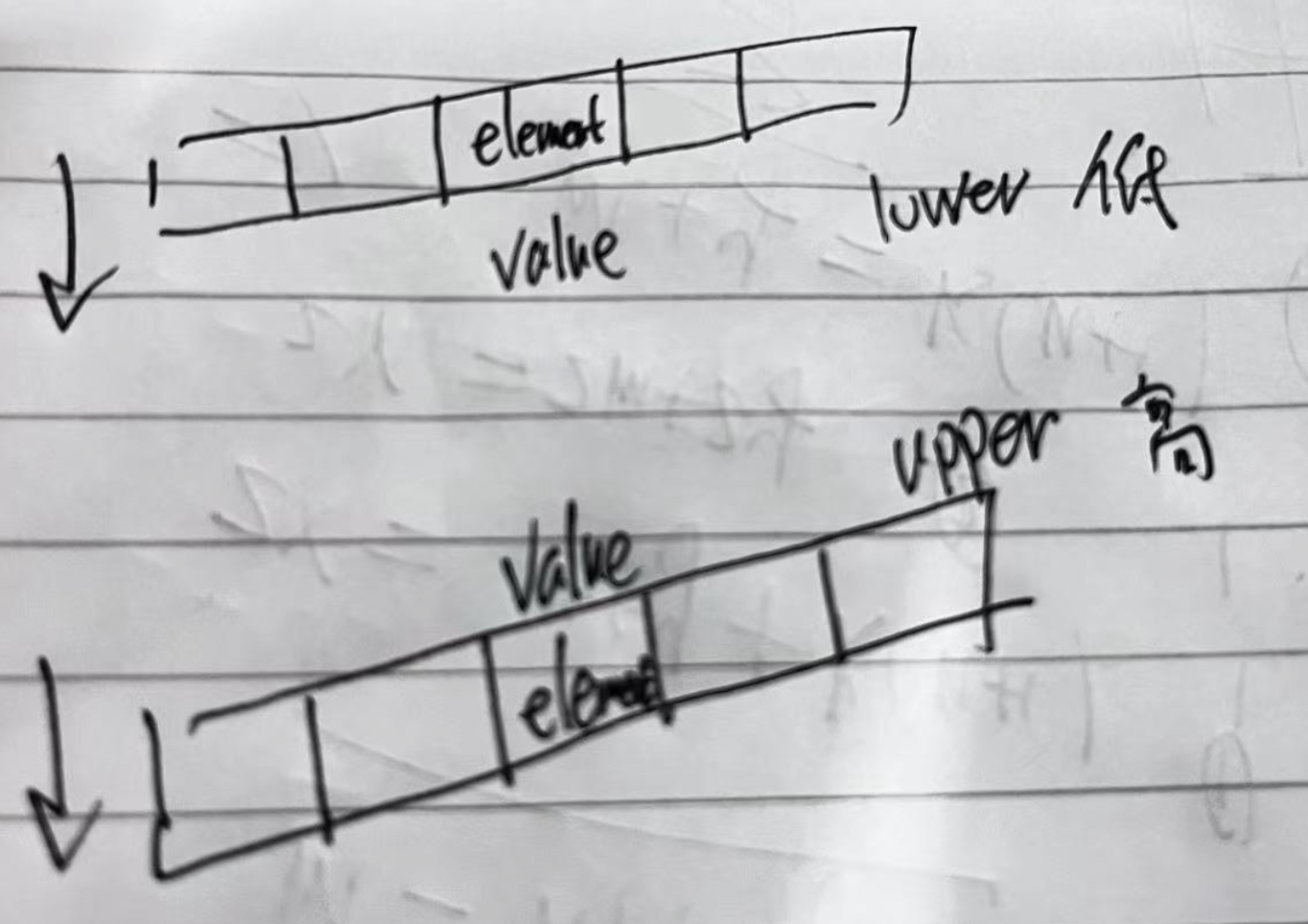
less(value, element)
less 表示一种 “符合关系“, 表示sort 后, 整个数组从前到后符合< 的关系, 方向是从前到后
二分函数
std::upper_bound
less(value, element)
从左到右找到第一个符合 less的
std::lower_bound
less(element, value)
从左到右找到第一个不符合less 的,
下面这个图,方面记忆value 和element 在 less 里的位置
2、 下上视角
优先队列(如 std::priority_queue)
底层逻辑理解:
堆, 构造的时候使用的是 heapUp 的一种操作,即首先将成员加入内部存储如 vetor 尾部, 然后对改成员进行跃升heapUP
设当前为now, 父节点为 p
less(now, p), 那么这个时候less 就是一种 自顶向上的符合关系 仰视视角的符合
记忆技巧
值越小优先级越高(比如linux 进程调度的 的PRI 值)