做百度手机网站优化快wdcp装wordpress502
此文章为笔记,为阅读其他文章的感受、补充、记录、练习、汇总,非原创,感谢每个知识分享者。
文章目录
- 1. 背景
- 2. 枚举缓存
- 3. 样例展示
- 4. 性能对比
- 5. 总结
本文通过几种样例展示如何高效优雅的使用java枚举消除冗余代码。
1. 背景
枚举在系统中的地位不言而喻,状态、类型、场景、标识等等,少则十几个多则上百个,相信以下这段代码很常见,而且类似的代码到处都是,目标:消除这类冗余代码。
/*** 根据枚举代码获取枚举* */public static OrderStatus getByCode(String code){for (OrderStatus v : values()) {if (v.getCode().equals(code)) {return v;}}return null;}/*** 根据枚举名称获取枚举* 当枚举内的实例数越多时性能越差*/public static OrderStatus getByName(String name){for (OrderStatus v : values()) {if (v.name().equals(name)) {return v;}}return null;}
2. 枚举缓存
- 减少代码冗余,代码简洁
- 去掉for循环,性能稳定高效
模块设计图
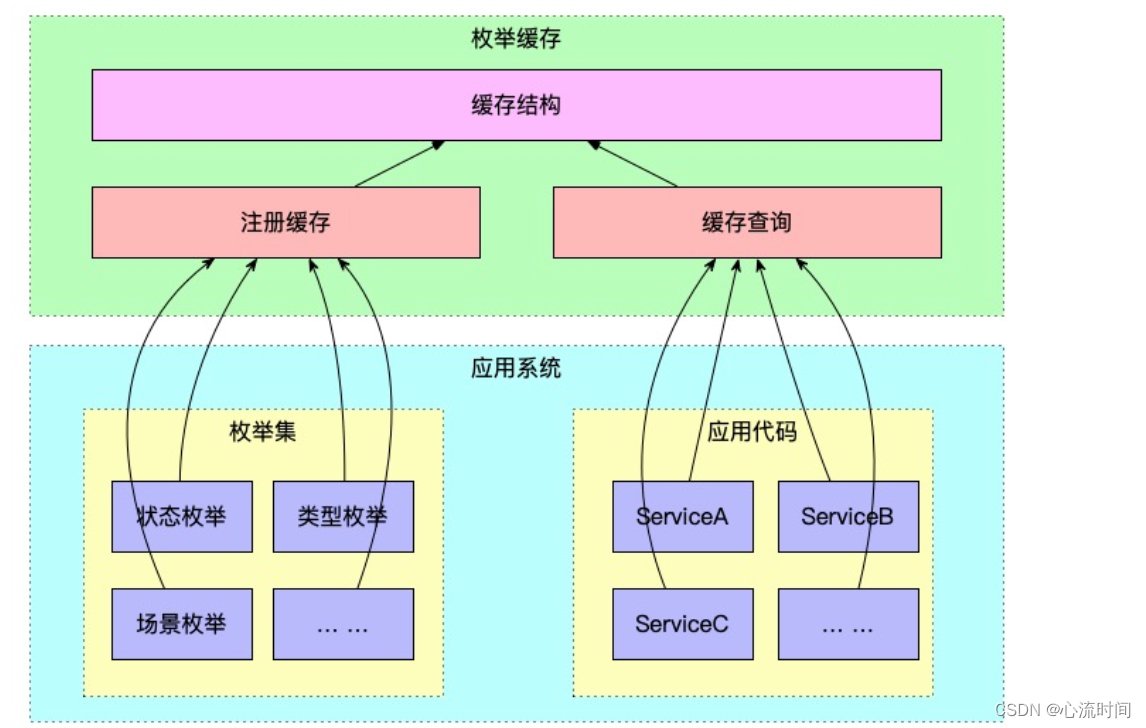
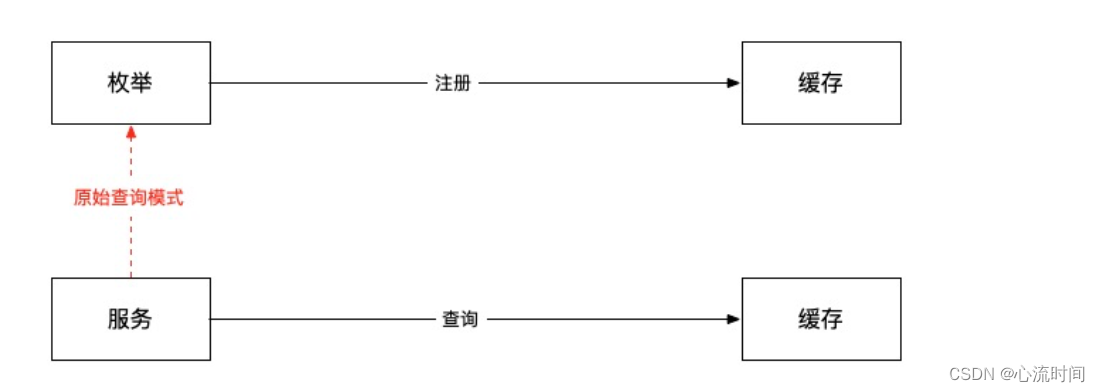
缓存结构
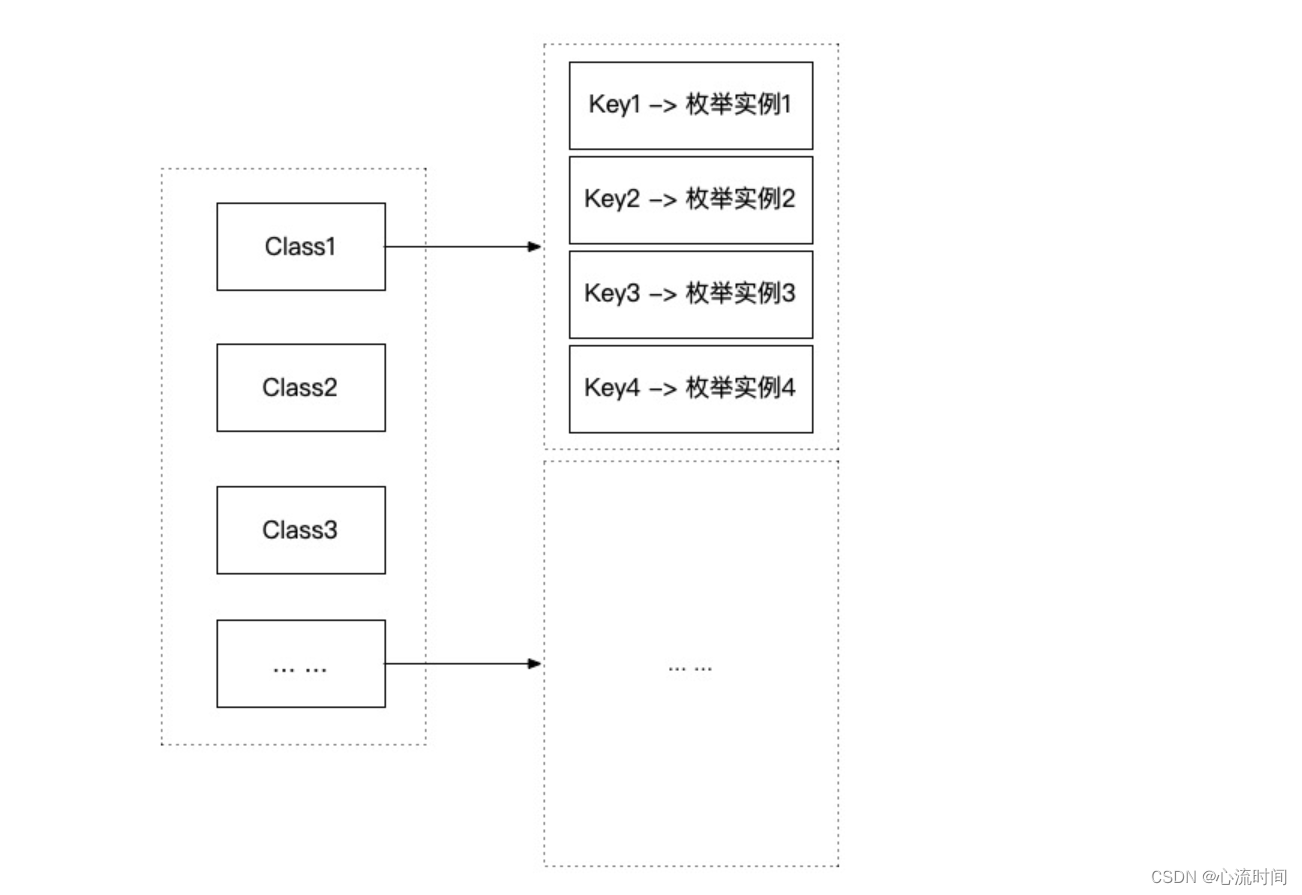
源码分析
源码展示
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;/*** 枚举缓存*/
public class EnumCache {/*** 以枚举任意值构建的缓存结构**/static final Map<Class<? extends Enum>, Map<Object, Enum>> CACHE_BY_VALUE = new ConcurrentHashMap<>();/*** 以枚举名称构建的缓存结构**/static final Map<Class<? extends Enum>, Map<Object, Enum>> CACHE_BY_NAME = new ConcurrentHashMap<>();/*** 枚举静态块加载标识缓存结构*/static final Map<Class<? extends Enum>, Boolean> LOADED = new ConcurrentHashMap<>();/*** 以枚举名称构建缓存,在枚举的静态块里面调用** @param clazz* @param es* @param <E>*/public static <E extends Enum> void registerByName(Class<E> clazz, E[] es) {Map<Object, Enum> map = new ConcurrentHashMap<>();for (E e : es) {map.put(e.name(), e);}CACHE_BY_NAME.put(clazz, map);}/*** 以枚举转换出的任意值构建缓存,在枚举的静态块里面调用** @param clazz* @param es* @param enumMapping* @param <E>*/public static <E extends Enum> void registerByValue(Class<E> clazz, E[] es, EnumMapping<E> enumMapping) {if (CACHE_BY_VALUE.containsKey(clazz)) {throw new RuntimeException(String.format("枚举%s已经构建过value缓存,不允许重复构建", clazz.getSimpleName()));}Map<Object, Enum> map = new ConcurrentHashMap<>();for (E e : es) {Object value = enumMapping.value(e);if (map.containsKey(value)) {throw new RuntimeException(String.format("枚举%s存在相同的值%s映射同一个枚举%s.%s", clazz.getSimpleName(), value, clazz.getSimpleName(), e));}map.put(value, e);}CACHE_BY_VALUE.put(clazz, map);}/*** 从以枚举名称构建的缓存中通过枚举名获取枚举** @param clazz* @param name* @param defaultEnum* @param <E>* @return*/public static <E extends Enum> E findByName(Class<E> clazz, String name, E defaultEnum) {return find(clazz, name, CACHE_BY_NAME, defaultEnum);}/*** 从以枚举转换值构建的缓存中通过枚举转换值获取枚举** @param clazz* @param value* @param defaultEnum* @param <E>* @return*/public static <E extends Enum> E findByValue(Class<E> clazz, Object value, E defaultEnum) {return find(clazz, value, CACHE_BY_VALUE, defaultEnum);}private static <E extends Enum> E find(Class<E> clazz, Object obj, Map<Class<? extends Enum>, Map<Object, Enum>> cache, E defaultEnum) {Map<Object, Enum> map = null;if ((map = cache.get(clazz)) == null) {executeEnumStatic(clazz);// 触发枚举静态块执行map = cache.get(clazz);// 执行枚举静态块后重新获取缓存}if (map == null) {String msg = null;if (cache == CACHE_BY_NAME) {msg = String.format("枚举%s还没有注册到枚举缓存中,请在%s.static代码块中加入如下代码 : EnumCache.registerByName(%s.class, %s.values());",clazz.getSimpleName(),clazz.getSimpleName(),clazz.getSimpleName(),clazz.getSimpleName());}if (cache == CACHE_BY_VALUE) {msg = String.format("枚举%s还没有注册到枚举缓存中,请在%s.static代码块中加入如下代码 : EnumCache.registerByValue(%s.class, %s.values(), %s::getXxx);",clazz.getSimpleName(),clazz.getSimpleName(),clazz.getSimpleName(),clazz.getSimpleName(),clazz.getSimpleName());}throw new RuntimeException(msg);}if(obj == null){return defaultEnum;}Enum result = map.get(obj);return result == null ? defaultEnum : (E) result;}private static <E extends Enum> void executeEnumStatic(Class<E> clazz) {if (!LOADED.containsKey(clazz)) {synchronized (clazz) {if (!LOADED.containsKey(clazz)) {try {// 目的是让枚举类的static块运行,static块没有执行完是会阻塞在此的Class.forName(clazz.getName());LOADED.put(clazz, true);} catch (Exception e) {throw new RuntimeException(e);}}}}}/*** 枚举缓存映射器函数式接口*/@FunctionalInterfacepublic interface EnumMapping<E extends Enum> {/*** 自定义映射器** @param e 枚举* @return 映射关系,最终体现到缓存中*/Object value(E e);}}
关键解读
开闭原则
什么是开闭原则?
对修改是封闭的,对新增扩展是开放的。为了满足开闭原则,这里设计成有枚举主动注册到缓存,而不是有缓存主动加载枚举,这样设计的好处就是:当增加一个枚举时只需要在当前枚举的静态块中自主注册即可,不需要修改其他的代码
比如我们现在要新增一个状态类枚举:
public enum StatusEnum {INIT("I", "初始化"),PROCESSING("P", "处理中"),SUCCESS("S", "成功"),FAIL("F", "失败");private String code;private String desc;StatusEnum(String code, String desc) {this.code = code;this.desc = desc;}public String getCode() {return code;}public String getDesc() {return desc;}static {// 通过名称构建缓存,通过EnumCache.findByName(StatusEnum.class,"SUCCESS",null);调用能获取枚举EnumCache.registerByName(StatusEnum.class, StatusEnum.values());// 通过code构建缓存,通过EnumCache.findByValue(StatusEnum.class,"S",null);调用能获取枚举EnumCache.registerByValue(StatusEnum.class, StatusEnum.values(), StatusEnum::getCode);}
}
注册时机
将注册放在静态块中,那么静态块什么时候执行呢?
1、当第一次创建某个类的新实例时
2、当第一次调用某个类的任意静态方法时
3、当第一次使用某个类或接口的任意非final静态字段时
4、当第一次Class.forName时
如果我们入StatusEnum创建枚举,那么在应用系统启动的过程中StatusEnum的静态块可能从未执行过,则枚举缓存注册失败,
所有我们需要考虑延迟注册,代码如下:
private static <E extends Enum> void executeEnumStatic(Class<E> clazz) {if (!LOADED.containsKey(clazz)) {synchronized (clazz) {if (!LOADED.containsKey(clazz)) {try {// 目的是让枚举类的static块运行,static块没有执行完是会阻塞在此的Class.forName(clazz.getName());LOADED.put(clazz, true);} catch (Exception e) {throw new RuntimeException(e);}}}}}
Class.forName(clazz.getName())被执行的两个必备条件:
1、缓存中没有枚举class的键,也就是说没有执行过枚举向缓存注册的调用,见EnumCache.find方法对executeEnumStatic方法的调用;
2、executeEnumStatic中的LOADED.put(clazz, true);还没有被执行过,也就是Class.forName(clazz.getName());没有被执行过;
我们看到executeEnumStatic中用到了双重检查锁,所以分析一下正常情况下代码执行情况和性能:
1、当静态块还未执行时,大量的并发执行find查询。
此时executeEnumStatic中synchronized会阻塞其他线程;第一个拿到锁的线程会执行Class.forName(clazz.getName());同时触发枚举静态块的同步执行;之后其他线程会逐一拿到锁,第二次检查会不成立跳出executeEnumStatic;2、当静态块已经执行,且静态块里面正常执行了缓存注册,大量的并发执行find查询。
executeEnumStatic方法不会调用,没有synchronized引发的排队问题;3、当静态块已经执行,但是静态块里面没有调用缓存注册,大量的并发执行find查询。
find方法会调用executeEnumStatic方法,但是executeEnumStatic的第一次检查通不过;
find方法会提示异常需要在静态块中添加注册缓存的代码;总结:第一种场景下会有短暂的串行,但是这种内存计算短暂串行相比应用系统的业务逻辑执行是微不足道的,
也就是说这种短暂的串行不会成为系统的性能瓶颈3. 样例展示
构造枚举
public enum StatusEnum {INIT("I", "初始化"),PROCESSING("P", "处理中"),SUCCESS("S", "成功"),FAIL("F", "失败");private String code;private String desc;StatusEnum(String code, String desc) {this.code = code;this.desc = desc;}public String getCode() {return code;}public String getDesc() {return desc;}static {// 通过名称构建缓存,通过EnumCache.findByName(StatusEnum.class,"SUCCESS",null);调用能获取枚举EnumCache.registerByName(StatusEnum.class, StatusEnum.values());// 通过code构建缓存,通过EnumCache.findByValue(StatusEnum.class,"S",null);调用能获取枚举EnumCache.registerByValue(StatusEnum.class, StatusEnum.values(), StatusEnum::getCode);}
}
测试类
public class Test{public static void main(String [] args){System.out.println(EnumCache.findByName(StatusEnum.class, "SUCCESS", null));// 返回默认值StatusEnum.INITSystem.out.println(EnumCache.findByName(StatusEnum.class, null, StatusEnum.INIT));// 返回默认值StatusEnum.INITSystem.out.println(EnumCache.findByName(StatusEnum.class, "ERROR", StatusEnum.INIT));System.out.println(EnumCache.findByValue(StatusEnum.class, "S", null));// 返回默认值StatusEnum.INITSystem.out.println(EnumCache.findByValue(StatusEnum.class, null, StatusEnum.INIT));// 返回默认值StatusEnum.INITSystem.out.println(EnumCache.findByValue(StatusEnum.class, "ERROR", StatusEnum.INIT));}
}
执行结果
SUCCESS
INIT
INIT
SUCCESS
INIT
INIT
4. 性能对比
对比代码,如果OrderType中的实例数越多性能差异会越大
public class Test {enum OrderType {_00("00", "00"),_01("01", "01"),_02("02", "02"),_03("03", "03"),_04("04", "04"),_05("05", "05"),_06("06", "06"),_07("07", "07"),_08("08", "08"),_09("09", "09"),_10("10", "10");private String code;private String desc;OrderType(String code, String desc) {this.code = code;this.desc = desc;}public String getCode() {return code;}public String getDesc() {return desc;}static {EnumCache.registerByValue(OrderType.class, OrderType.values(), OrderType::getCode);}public static OrderType getEnumByCode(String code, OrderType def) {OrderType[] values = OrderType.values();for (OrderType value : values) {if (value.getCode().equals(code)) {return value;}}return def;}}private static final OrderType DEF = OrderType._00;private static final int TIMES = 10000000;static void compare(String code) {long s = System.currentTimeMillis();for (int idx = 0; idx < TIMES; idx++) {OrderType.getEnumByCode(code, DEF);}long t = System.currentTimeMillis() - s;System.out.println(String.format("枚举->%s : %s", code, t));s = System.currentTimeMillis();for (int idx = 0; idx < TIMES; idx++) {EnumCache.findByValue(OrderType.class, code, DEF);}t = System.currentTimeMillis() - s;System.out.println(String.format("缓存->%s : %s", code, t));System.out.println();}public static void main(String[] args) throws Exception {for (int idx = 0; idx < 2; idx++) {compare("NotExist");for (OrderType value : OrderType.values()) {compare(value.getCode());}System.out.println("=================");}}
}
执行结果
枚举->NotExist : 312
缓存->NotExist : 105枚举->00 : 199
缓存->00 : 164枚举->01 : 313
缓存->01 : 106枚举->02 : 227
缓存->02 : 90枚举->03 : 375
缓存->03 : 92枚举->04 : 260
缓存->04 : 92枚举->05 : 272
缓存->05 : 78枚举->06 : 284
缓存->06 : 78枚举->07 : 315
缓存->07 : 76枚举->08 : 351
缓存->08 : 78枚举->09 : 372
缓存->09 : 81枚举->10 : 402
缓存->10 : 78=================
枚举->NotExist : 199
缓存->NotExist : 68枚举->00 : 99
缓存->00 : 91枚举->01 : 141
缓存->01 : 79枚举->02 : 178
缓存->02 : 77枚举->03 : 202
缓存->03 : 77枚举->04 : 218
缓存->04 : 81枚举->05 : 259
缓存->05 : 90枚举->06 : 322
缓存->06 : 78枚举->07 : 318
缓存->07 : 78枚举->08 : 347
缓存->08 : 77枚举->09 : 373
缓存->09 : 79枚举->10 : 404
缓存->10 : 78=================
5. 总结
1、代码简洁;
2、枚举中实例数越多,缓存模式的性能优势越多;