厦门营销网站建设重庆网站开发商城

链接:https://pan.baidu.com/s/1s9j7OhiOMV9e9Qq9GDbysA
提取码:dd5a
--来自百度网盘超级会员V5的分享
Mysql官网:MySQL


关于Mysql Yum Repository介绍可以看下 更加简单


关于X86和ARM



传到服务器
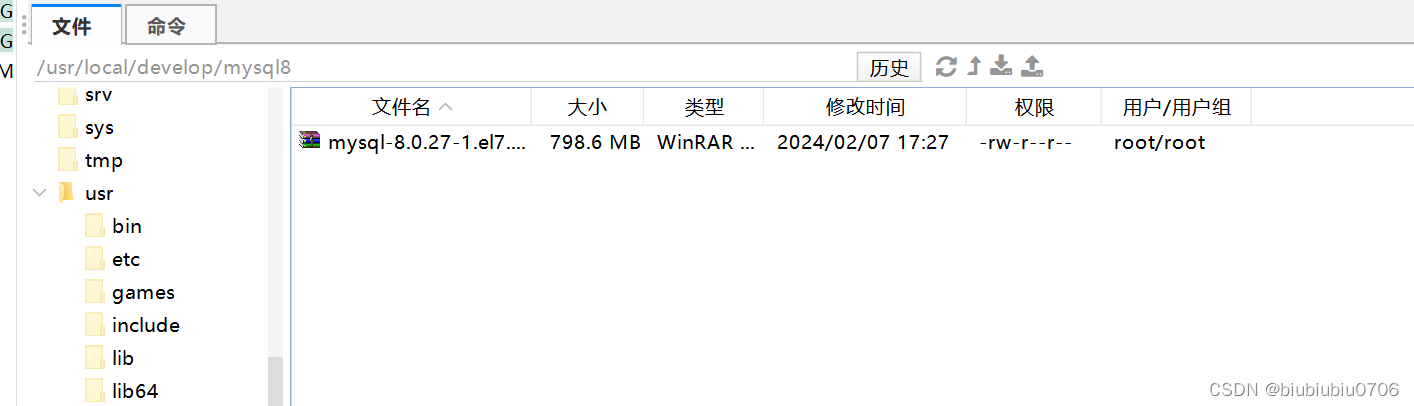
进入所在包
cd /usr/local/develop/mysql8
解压 (也可以window上解压好再一个个上传)
tar -xvf mysql-8.0.27-1.el7.x86_64.rpm-bundle.tar
检查下下面的步骤 权限如果是root应该不需要检查


下面这些包并非都要安装 按一下顺序安装

rpm -ivh mysql-community-common-8.0.27-1.el7.x86_64.rpm

rpm -ivh mysql-community-client-plugins-8.0.27-1.el7.x86_64.rpm

rpm -ivh mysql-community-libs-8.0.27-1.el7.x86_64.rpm 
安装依赖
yum remove mysql-libs (清除之前安装过的依赖)

继续安装
rpm -ivh mysql-community-libs-8.0.27-1.el7.x86_64.rpm

rpm -ivh mysql-community-client-8.0.27-1.el7.x86_64.rpm

rpm -ivh mysql-community-server-8.0.27-1.el7.x86_64.rpm

查看mysql版本
mysql --version 或者 mysqladmin --version

服务器初始化配置
为了保证数据库目录与文件的所有者为mysql登录用户,如果你是以root身份运行mysql服务
需要执行下面命令初始化
mysqld --initialize --user=mysql

要查看已安装的与 MySQL 相关的 RPM 包,你可以运行以下命令
rpm -qa|grep -i mysql


cat /var/log/mysqld.log

查看服务是否启动
systemctl status mysqld

启动mysql服务
systemctl start mysqld
如果服务器重启 mysql不会自启动
查看mysql服务是否自启动
systemctl list-unit-files|grep mysqld.service

说明是自启动
如果不是enabled运行一下命令设置自启动
systemctl enable mysqld.service
如果希望不进行自启动 运行如下命令
systemctl disable mysqld.service
试下用刚才查看的密码登录mysql
mysql -uroot -p
输入密码 就是上面cat /var/log/mysqld.log查看到的密码


修改密码
alter user 'root'@'localhost' identified by '你的新密码'; 注意';'号结尾
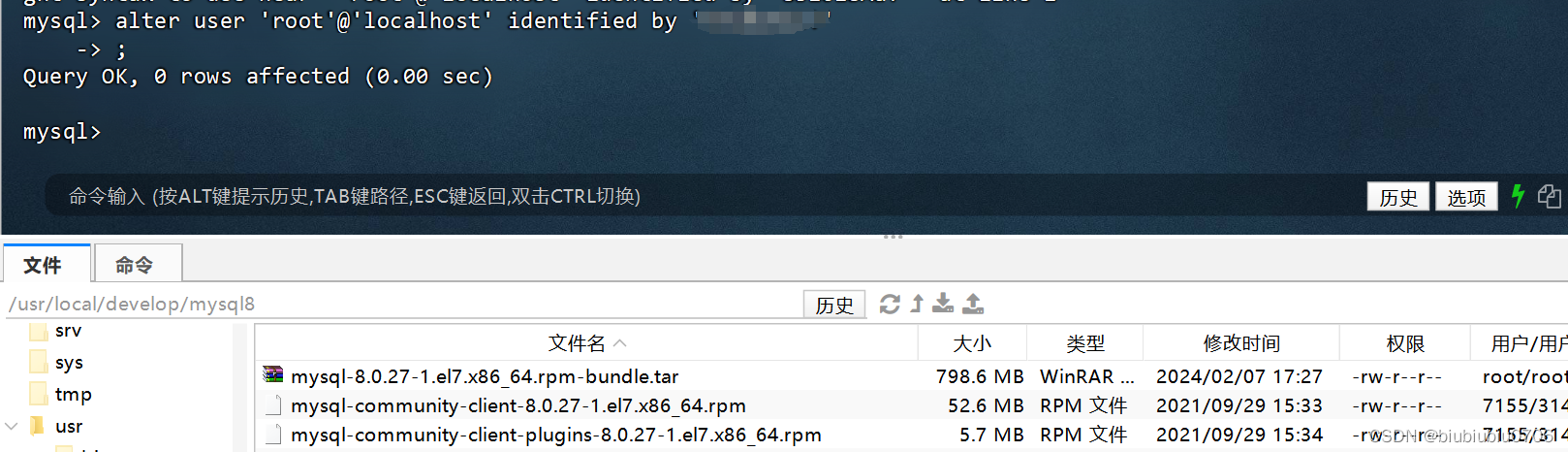
退出
quit

安全组开通3306端口
但是连接时候报错

这个问题是因为在数据库服务器中的mysql数据库中的user的表中没有权限
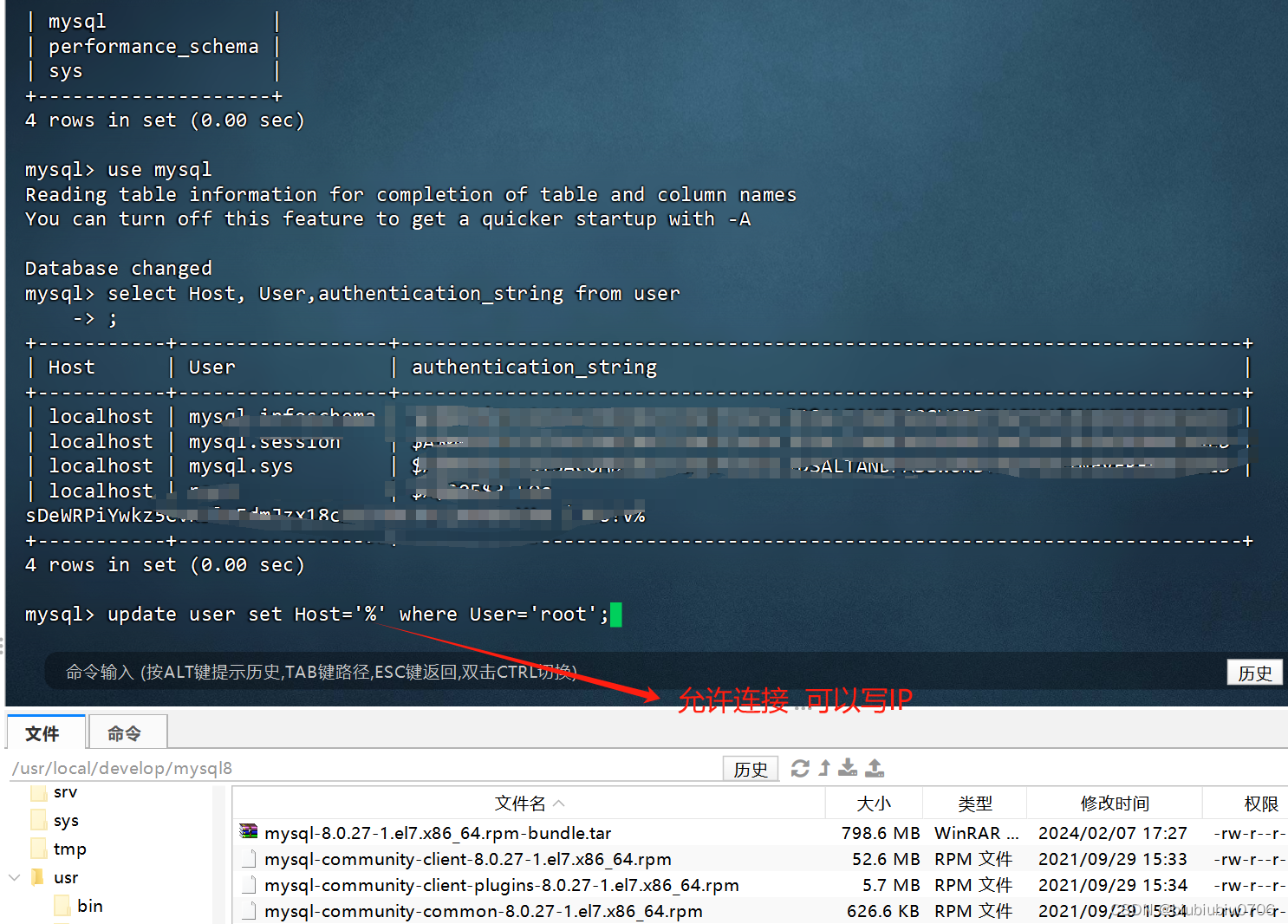
登录mysql
use mysql;
查看user表中的数据:select Host, User,authentication_string from user;
修改user表中的Host:update user set Host='%' where User='root';

写%就是所有IP都可以连接 可以写固定IP
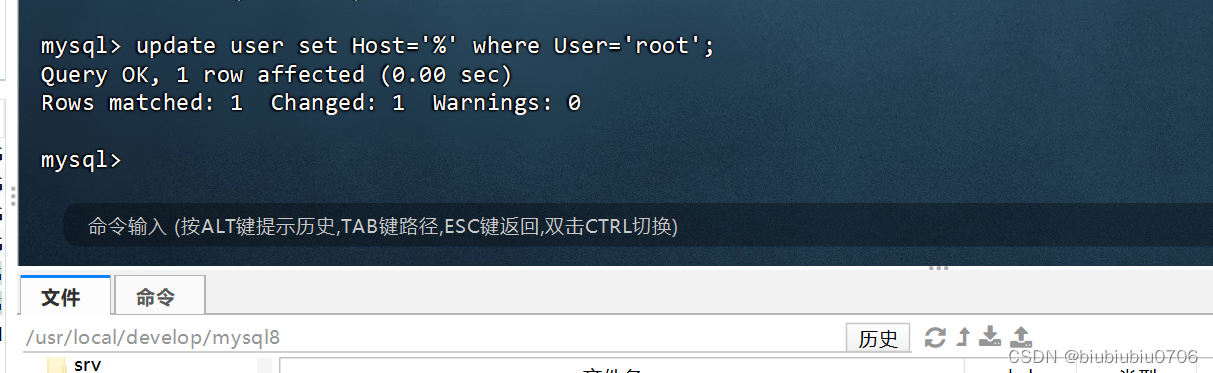
最后刷新一下
flush privileges;


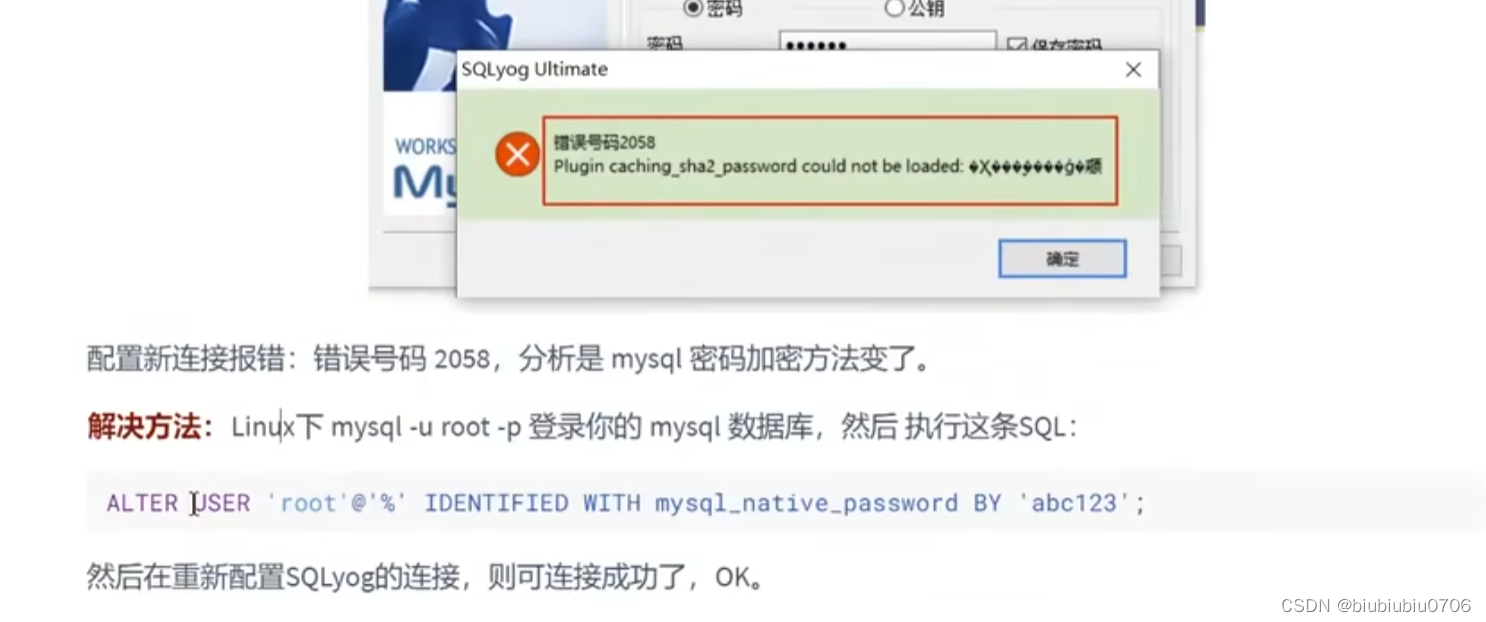
如果你的版本是8.0.25
可能出现下面情况 更新成你的密码
查看字默认使用的字符集
show variables like 'character%';
或者
show variables like 'char%';

以下操作是在Mysql5.7里操作记录 Mysql8不需要
如果是Mysql5.7 需要进行字符集修改 不然存中文报错
在linux系统里 需要修改配置文件
注意是Mysql5.7 要这么写 Mysql8不需要
vim /etc/my.cnf

在Mysql5.7中 配置完 记得重启Mysql服务
systemctl restart mysqld.service
对已有数据库字符集修改



查看mysql命名的文件目录
find / -name mysql
Mysql数据库文件存放路径: /var/lib/mysql/ 好比windows里的 data文件

这几个都有
在 MySQL 数据库中,information_schema 并不是一个实际存在的目录,而是一个虚拟的数据库。information_schema 包含了关于数据库、表、列、权限等元数据的信息,这些信息是通过查询系统表得到的,而不是通过文件存储的。


mysql相关命令目录 /usr/bin 和/usr/sbin