找投资项目的网站怎样在阿里巴巴做网站
原文标题:Domain Adaptive YOLO for One-Stage Cross-Domain Detection
中文标题:面向单阶段跨域检测的域自适应YOLO

1、Abstract
域转移是目标检测器在实际应用中推广的主要挑战。两级检测器的域自适应新兴技术有助于解决这个问题。然而,两级检测器由于其耗时较长,并不是工业应用的首选。本文提出了一种新颖的域自适应 YOLO(DA-YOLO)来提高单级检测器的跨域性能。图像级特征对齐用于严格匹配纹理等局部特征,并松散地匹配照明等全局特征。提出多尺度实例级特征对齐以有效减少实例域偏移,例如目标外观和视点的变化。对这些域分类器进行共识正则化以帮助网络生成域不变检测。我们在 Cityscapes、KITTI、SIM10K 等流行数据集上评估我们提出的方法。在不同的跨域场景下进行测试时,结果表明有显著的改进。
关键词:域转移、域适应、单阶段检测器、YOLO
2、Introduction
2.1、目标检测面临的挑战
目标检测旨在对给定图像中感兴趣的目标进行定位和分类。近年来,自深度卷积神经网络(CNN)出现以来,大量成功的目标检测模型一直被提出。然而,一个被称为“领域转移”的新挑战开始困扰计算机视觉社区。域漂移是指源域和目标域之间的分布不匹配导致性能下降。它是由图像的变化引起的,包括不同的天气条件,相机的视角,图像质量等。以自动驾驶为例,一个可靠的目标检测模型应该在任何情况下都能稳定地工作;然而训练数据通常是在视野清晰的晴天收集的,而实际上汽车可能会遇到恶劣的天气条件,包括雪和雾,导致能见度受到影响,此外相机的位置在测试环境中可能会有所不同,从而导致视点变化。
2.2、领域自适应的发展
理想情况下,在目标域上重新标记是解决域转移问题的最直接的方法。但这种手工注释会带来昂贵的时间和经济成本。出于对无需注释方法的期望,领域适应努力消除领域差异,而无需对目标领域进行监督。领域自适应(DA)首先被广泛应用于分类任务中,使用最大平均差异(MMD)等距离度量单位来衡量域偏移,并监督模型学习领域不变特征。后来,使用领域分类器和梯度反转层(GRL)的对抗训练策略被证明是一种更有效的学习鲁棒跨领域特征的方法。在训练阶段,领域分类器对源域和目标域数据的区分能力逐渐提高,骨干特征提取器学习生成更多的领域不可区分特征。最后,特征提取器能够生成域不变特征。
2.3、域自适应目标检测
1)用于目标检测的 DA 继承并扩展了相同的对抗训练思想。与分类 DA 类似,检测 DA 对骨干特征提取器采用对抗性训练。然而除了分类之外,目标检测器还需要对每个感兴趣的物体进行定位和分类。因此使用一个额外的域分类器对每个实例特征进行分类,以促使特征提取器在实例级别上是域不变的。这种对抗性检测自适应方法是由Chen等人(2018)首创的,他们使用Faster R-CNN作为基本检测器模型。随后的研究遵循了这一惯例,Faster R-CNN成为了主要的领域自适应检测器。此外,Faster R-CNN的两阶段特性使得它非常适合在实例级特征上应用域自适应。区域建议网络(RPN)和兴趣区域池(ROI)产生的统一实例级特征便于领域分类器直接使用。
2)尽管 Faster R-CNN 很受欢迎并且可以方便地利用区域提议网络(RPN),但在时间性能至关重要的现实应用中,Faster R-CNN 并不是理想选择。与 Faster R-CNN 相比,YOLO (2016)是一种具有代表性的单阶段检测器,由于其惊人的实时性能、简单性和便携性而成为更有利的选择。YOLOv3 (2018)是YOLO的流行版本,广泛应用于工业领域,包括视频监控、人群检测和自动驾驶。然而,对单阶段检测器的域自适应研究仍然很少。
2.4、本文提出的方法
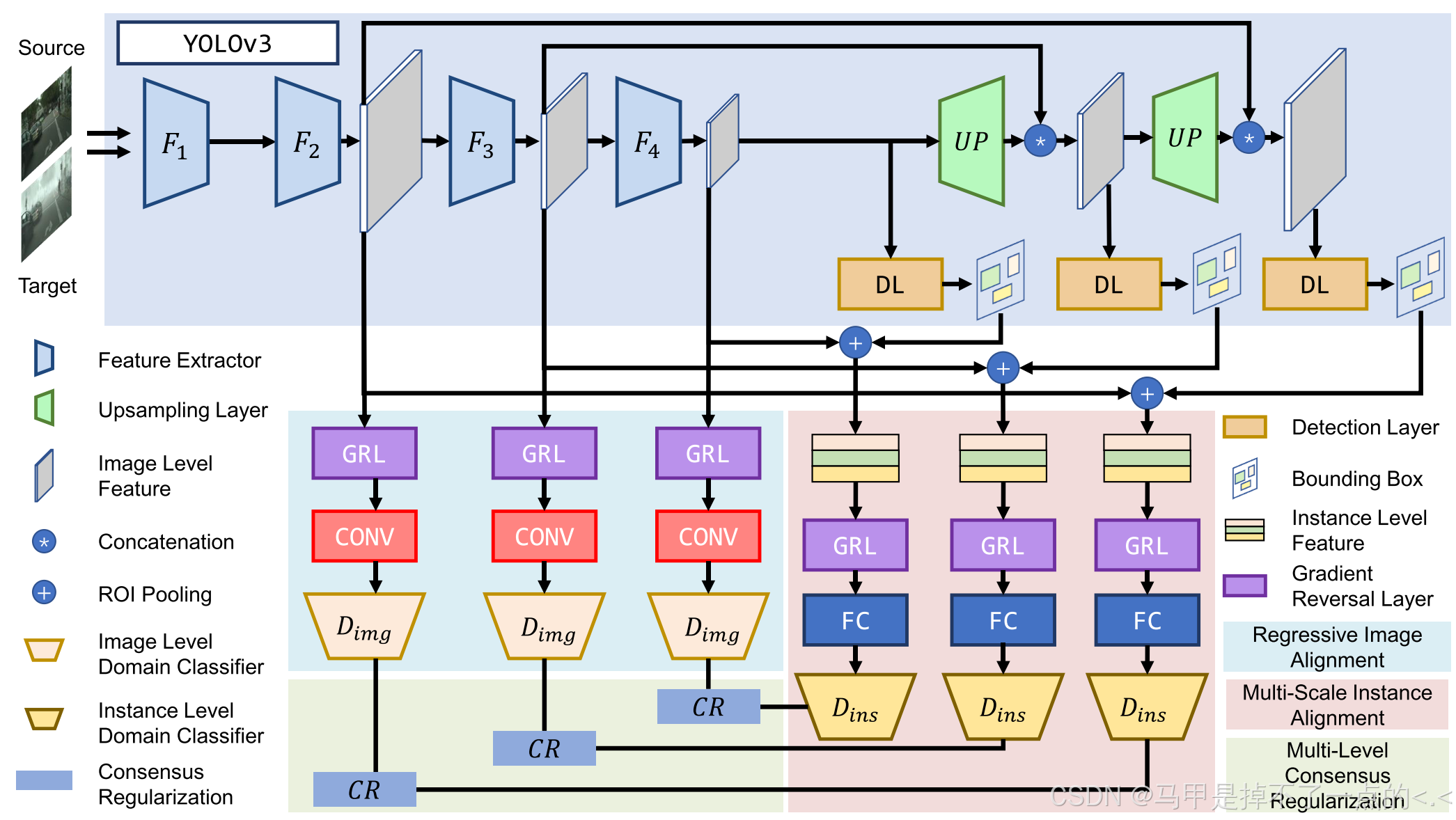
在本文中,我们介绍了一种新颖的域自适应 YOLO(DA-YOLO),它使用单级检测器 YOLOv3 执行域自适应。该模型的总体架构如下图1所示。首先,我们提出回归图像对齐(Regressive Image Alignment,RIA)来减少图像级别的域差异。RIA 在 YOLOv3 特征提取器的不同层使用三个域分类器来预测特征图的域标签。然后,它采用对抗性训练策略(adversarial training strategy)来对齐图像级别特征。通过为这些图像级域分类器分配不同的权重,RIA 严格对齐局部特征并宽松地对齐全局特征。其次,我们提出多尺度实例对齐(Multi-Scale Instance Alignment,MSIA)用于实例级域适应。由于没有两阶段检测器中的区域建议网络RPN,MSIA 利用了 YOLOv3 的三尺度检测。MSIA 使用三个域分类器进行这些检测,以对齐实例级特征。最后,我们将多级一致性正则化(Multi-Level Consensus Regularization,MLCR)应用于域分类器,以驱动网络产生域不变检测。
2.5、本文贡献
综上所述,我们在本文中的贡献有三个方面:
1)我们设计了两个新的领域自适应模块来解决领域移位问题。
2)我们提出了一种用于一级检测器的领域自适应范式。 据我们所知,这是第一个提出统一一级检测器的图像级和实例级自适应的工作。
3)利用Cityscapes、Foggy Cityscapes、KITTI、SIM10K数据集进行了广泛的领域自适应实验。结果表明,本文提出的自适应YOLO在不同的跨域场景下是有效的。
3、Related Works
3.1、Object Detection
随着深度神经网络的应用,目标检测方法蓬勃发展。它们大致可分为两类:两阶段法和单阶段法。R-CNN系列是两阶段检测器的代表,首先生成兴趣区域提案,然后对其进行分类。同时,YOLO作为单阶段检测器的代表,以其实时性成为应用广泛的一种检测器。YOLOv2 (2017) 和YOLOv3 (2018)是作为增量改进引入的,集成了残差块等有效技术。YOLOv4 (2020)是各种技巧的组合,可以实现最佳的速度和准确性。
3.2、Domain Adaptation
领域自适应旨在通过使用带注释的源域数据来提高模型在目标领域上的性能。首先通过匹配源域和目标域的边缘分布和条件分布,将其应用到分类任务中。以往工作包括TCA(2010)、JDA(2013)、JAN(2017)。随着生成式对抗网络GAN(2014) 的出现,对抗训练策略因其有效性而受到欢迎。事实证明,该策略在学习领域不变特征方面非常有帮助,并导致了一系列对抗性领域自适应的研究,包括DANN(2016),DSN(2016),SAN(2018)等等。
3.3、Domain Adaptation for Object detection
Domain Adaptive Faster R-CNN(2018)使用两阶段检测器Faster R-CNN探索了目标检测的对抗性域自适应。后续若干研究遵循了两阶段的范式,并做出了相当大的改进。尽管两级检测器便于域自适应,但在工业应用中很少使用。在实际应用中,单阶段探测器具有无可比拟的速度性能。因此,将单阶段检测器与领域自适应相结合具有重要的意义,但相关研究很少。这种情况促使我们开展本文提出的工作。
关于单阶段检测器的域自适应的研究有限。YOLO in the Dark Sasakawa and Nagahara (2020) 通过合并多个预先训练的模型来适应 YOLO。MS-DAYOLO (2021) 对 YOLO 模型采用多尺度图像级自适应。然而,它没有考虑实例级自适应,而实例级自适应被证明是同等甚至是更重要的。实例特征适应是一项更具挑战性的任务,因为在单阶段检测器中没有两阶段检测器中的区域建议网络RPN。在本文中,我们通过使用 YOLO 的检测来解决这个问题。
4、Methodology
4.1、Problem Definition(问题定义)
1)域适应的目标是将从已标记的源域 Ds 学到的知识转移到未标记的目标域 Dt。Dt 的分布与 Ds 类似,但不完全相同。源域提供了完整的注释,表示为 Ds = {(xsi , ysi , bsi )}nsi,其中 bsi ∈ Rk×4 表示图像数据 x 的边界框坐标,ysi ∈ Rk× 1 表示相应边界框的类别标签。相应地,目标域没有注释,表示为 Dt = {(xtj)}ntj 。通过使用已标记的源域数据 Ds 和未标记的目标域数据 Dt,源检测器可以很好地推广到目标域。
2)源域和目标域的联合分布分别表示为 PS(C, B, I) 和 PT(C, B, I),其中 I 代表图像表示,B 代表边界框,C ∈ {1, .. .,M} 表示对象的类别标签(M 是类别总数)。域偏移源于域之间的联合分布不匹配,即 PS(C, B, I) \= PT(C, B, I)。
3)联合分布可以用两种方式分解:P(C, B, I) = P(C, B | I)P(I) 和 P(C, B, I) = P(C | B , I)P(B, I)。通过强制 PS(I) = PT(I) 和 PS(B, I) = PT(B, I),我们可以减轻图像级别和实例级别上的域不匹配。
4.2、A Closer Look at Domain Adaptive Object Detection(仔细研究域自适应目标检测)
1)作为对抗性自适应检测的开创性工作,Domain Adaptive Faster R-CNN(2018) 提出:
a、图像对齐,重点是弥合由图像级别变化(例如不同的图像质量和照明)引起的域间隙;
b、实例对齐,重点是减少由实例级别变化(例如对象大小差异)引起的实例级别域偏移;
c、一致性正则化,旨在增强域不变定位能力。
2)尽管这样的范例是有效的,但是基于Faster R-CNN的域自适应不能很好地应用于现实世界。原因是双重的;首先,像Faster R-CNN这样的两级检测器需要对骨干、RPN和检测头进行训练,设置既不方便也不直接;其次,两级检测器的时间性能不理想,例如由Facebook AI Research实现的最先进的两级探测器Detectron2几乎无法达到实时性能。相反,像YOLO这样的单阶段检测器因其在实践中的优越性而在工业应用中得到了广泛的应用。例如,PP-YOLO (2020)广泛应用于行人检测、汽车检测和产品质量检测。单阶段检测器易于使用,可自由定制,并且在时间成本和计算成本方面可以实现高性能。
3)代表性的单阶段检测器YOLOv3由两部分组成:主干特征提取器Darknet-53和三个不同尺度的检测层。特征提取器以图像作为输入,分别向三个检测层提供三个不同大小的特征图。因此在三个不同的尺度上产生检测输出,并组合在一起作为最终输出。YOLOv3的训练损失由定位损失、分类损失和置信度损失组成:

其中,前两项是定位损失,后两项是分类损失,最后一项是置信损失。
4.3、Domain Adaptive YOLO(基于YOLO的域自适应)
4.3.1、Regressive Image Alignment(回归图像对齐)
1)在Chen等人(2018)的研究中,图像级对齐被证明是一种有效的域自适应方法。然而由于梯度消失,仅对最终特征图(final feature map)中的特征进行对齐,无法充分消除域漂移。因此,Xie等人(2019)和Hnewa和Radha(2021)都提出在中间特征图上使用额外的领域分类器,这被证明是一种有效的方法。然而正如Saito et al.(2019)所指出的那样,对于那些具有大感受野(large receptive field)的特征,即特征提取器后半部分的特征,如果进行过于强烈的匹配(strong matching),在处理大的领域偏移时可能会导致负迁移(negative transfer)。负迁移是指源领域的模型在目标领域上的性能不仅没有提升,反而下降了。负迁移的原因:大感受野的特征通常捕捉了更多的上下文信息,这些信息在源领域和目标领域之间可能差异很大。如果这些特征被过于强烈地匹配,那么模型可能会过度适应源领域的特定上下文,而忽略了那些对目标领域更重要的、更加通用的特征。
2)为了解决这个问题,我们提出了回归图像对齐(RIA)。我们首先像以前的工作一样将多个域分类器应用于中间特征图和最终特征图。然后当这些分类器采用更深的特征图作为输入时,我们为这些分类器分配递减的权重。RIA 损失函数可以写为:
![]()
其中,Φ(u,v)i,k 表示第 i 个图像对应的位于二维坐标 (u, v) 处第 k 个特征图的激活函数输出值。fk 表示域分类器。Di 是第 i 个训练图像的域标签,在有监督的源领域Di通常是1;在无监督的目标领域Di通常是 0。λk 表示分配给域分类器的权重,随着 k 增加(即从浅层到深层),λk 会减小,这意味着对深层特征的对齐强度会减弱,以避免负迁移。RIA 完全适应骨干特征提取器,同时减少可能的负迁移。fk(Φ(u,v)i,k)这是第 k 个领域分类器的输出,它预测特征激活值 Φ(u,v)i,k 来自源领域的概率。
4.3.2、Multi-Scale Instance Alignment(多尺度实例对齐)
Hnewa和Radha(2021)是第一个在单阶段检测器中引入对抗性域适应的工作,但只是初级的。因为它没有考虑实例对齐,这与Chen等人(2018)所展示的图像对齐效果差不多。对于单阶段检测器来说,实例对齐是一项具有挑战性的任务,因为实例特性不像在两阶段检测器中那样可以随意得到。我们提出了多尺度实例对齐(MSIA)来解决这一挑战。具体来说,我们从YOLOv3的三个不同尺度检测层中提取检测结果,并使用ROI池从相应的特征图中提取实例级特征。通过访问实例特性,我们可以合并实例对齐丢失,它可以写为:

其中,pki,j 表示第 i 个图像中第 k 个尺度的第 j 个检测框的概率输出。对齐实例特征有助于消除源域和目标域的感兴趣目标之间的外观、形状、视点的差异。
4.3.3、Multi-Level Consistency Regularization(多级一致性正则化)
通过采用图像和实例对齐,网络能够产生域不变特征。然而它不能保证产生域不变的检测,这对于对目标检测也至关重要。理想情况下,我们期望获得域不变的边界框预测器 P(B|I)。 但实际上,边界框预测器 P(B|D, I) 是有偏差的,其中 D 表示域标签。我们有:
![]()
为了减轻边界框预测器偏差,有必要强制执行 P(D|B, I) = P(D|I),这是实例级和图像级域分类器之间的共识。因此,P(B|D, I) 将近似于 P(B|I)。
由于YOLOv3在三种不同尺度上检测目标,我们提出了多级一致性正则化来自适应地检测不同尺度上的目标,可以写为:

其中,|Ik| 表示第 k 个特征图上的激活数量。通过实施这种多级正则化,YOLO 的每个检测层都被鼓励产生域不变检测。
4.3.4、Network Overview(网络概况)
1)我们网络的完整架构如下图 1 所示。我们在 YOLOv3 上构建了我们提出的域自适应模块,它们的组合构成了域自适应 YOLO。请注意,所示的架构是专门为训练阶段设计的,而检测器是测试阶段的唯一组件。
2)YOLOv3首先使用一系列特征提取器来生成小、中、大尺度的三个特征图。两个连续的上采样层将最后一个特征图(小比例)作为输入,并生成一个新的中型和大型特征图,并与之前的特征图连接起来。最新的三个特征图被输入到检测层并生成最终检测结果。
3)RIA模块将三个尺度特征图作为输入,并使用领域分类器来预测它们的领域标签。MSIA模块使用不同的尺度检测来提取实例级特征,并将它们提供给域分类器。通过eq.(2)和eq.(3)计算RIA和MSIA的域分类损失,以适应网络。最后通过MLCR模块对相应的图像级和实例级域分类器进行正则化,监督网络生成域不变检测。

完整的训练损失函数如下:
![]()
其中,λ为平衡域自适应损失影响的超参数。这种域适应损失被GRL逆转来进行对抗性训练。
5、Experiments
在本节中,我们对提出的DA-YOLO模型在三种域适应场景下进行了评估:
1)从晴朗到有雾(from clear to foggy):源域是晴天采集的照片,目标域是雾天。
2)从一个场景到另一个场景(from one scene to another):源域和目标域包含不同场景下不同相机拍摄的照片。
3)从合成到真实(from synthetic to real):源域是电脑游戏中的图像,目标域是现实世界。
5.1、Datasets
5.1.1、Cityscapes(2016)
收集了50个不同城市良好/中等天气条件下的城市街景。它有30个类别的5000张注释图像。
5.1.2、Foggy Cityscapes(2018)
使用Cityscapes的相同图像模拟雾蒙蒙的场景,使其成为领域适应实验的理想选择。它从Cityscapes中继承了相同的注释。
5.1.3、KITTI(2015)
通过在中型城市卡尔斯鲁厄、农村地区和高速公路上驾驶来收集图像。它有14999张图片,包括 person 和 car 等类。在我们的实验中,我们只使用 car 的 6684 个训练图像和注释。
5.1.4、SIM10K(2016)
从一款名为侠盗猎车手 V(GTA V)的视频游戏中收集合成图像。它总共有 10,000 张图像和注释,主要是针对汽车的。
5.2、Protocols
我们报告了每个类别的平均精度(AP)和平均平均精度(mAP),评估阈值为0.5。为了验证我们提出的方法,我们不仅报告了网络的最终结果,还报告了不同变体(RIA, MSIA, MLCR)的结果。我们使用原始的YOLOv3作为基线,它在源域数据上进行训练,而不使用域适应。通过使用带注释的目标域数据训练YOLOv3,我们展示了理想的性能(oracle)。我们还将我们的结果与基于Faster R-CNN的现有SOTA方法进行了比较。
5.3、Experiments Details
实验遵循传统无监督域自适应设置。源域提供了完整的注释,而目标域没有。每一个训练批次由来自源域的一张图像和来自目标域的一张图像组成。每个图像被调整为宽度416和高度416,以适应YOLOv3网络。我们的代码是基于PyTorch实现的YOLOv3和Domain Adaptive Faster RCNN。在执行自适应之前,使用预训练的权重对网络进行初始化,并且所有超参数保持上述两种实现的默认值。具体来说,骨干特征提取器的学习率为0.001,其余层的学习率为0.01。采用了0.0005权值衰减的标准SGD算法。
5.4、Results
1)表1将我们的模型与其他基于Faster R-CNN的模型进行了比较。我们在两个域适应设置中进行了评估,KITTI到Cityscapes和SIM10K到Cityscapes。虽然DAF(2018)是有效的,但它只对Faster R-CNN的最终特征映射进行图像级对齐。MADAF(2019)和MLDAF(2019)对DAF进行扩展,并在骨干特征提取器的不同层次上对齐图像级特征。STRWK(2019)对局部特征进行强对齐,对全局特征进行弱对齐。它们都没有有效地扩展实例对齐模块。我们提出的方法在图像和实例级别上进行多级对齐,实现了17.6%和4.5%的性能提升,领先于其他模型。

2)下图2为检测结果示例。在图中,基线模型(仅在源域数据上训练)遗漏了一些汽车,但本文提出的模型可以正确地检测到它们。

3)如下图3所示,我们使用 t-SNE 可视化了从Cityscapes到Foggy Cityscapes的域适应中的图像级特征。红色和蓝色分别表示源域和目标域。我们可以看到,左图中源域和目标域的特征明显分离,而右图中源域和目标域的特征更加接近或重叠,这表明模型成功地减少了领域之间的分布差异。因此,与仅源模型(在源域上训练而不进行域适应)相比,我们的自适应模型全局特征对齐得很好。
t-SNE(t-distributed Stochastic Neighbor Embedding)是一种常用的数据可视化技术,它可以直观地观察高维特征在低维空间中的分布情况。

5.5、Ablation Study
1)通过Cityscapes对Foggy Cityscapes和KITTI对Cityscapes两种域适应场景的消融研究,验证了三个模块的有效性。性能结果总结在下表2和下表3中。在从Cityscapes到Foggy Cityscapes的任务中,通过对每个图像级域分类器应用同等权重的图像对齐(EIA),我们获得了0.5%的性能提升。
2)将MSIA和MLCR进一步汇总,可以分别提高0.4%和1.2%,说明这两个模块是有效的。最后用RIA代替EIA,我们有1.5%的提升。这验证了回归权值分配在图像级自适应中的显著有效性。与常规多级图像对齐方法相比,RIA对图像级域分类器的权重递减。这将强烈匹配局部特征,这对域适应更重要。

3)在从KITTI到Cityscapes的任务中,也取得了类似的结果。具体来说,对各个模块进行累加,分别获得5.8%、13.6%、15.4%、17.6%的性能增益。再次验证各模块的有效性。EIA表示每个图像级域分类器具有相同权重的图像对齐。RIA表示三个图像级域分类器的权值递减的图像对齐,即RIA模块。

6、Conclusion
本文提出了一种有效的单阶段跨域自适应DA-YOLO算法。与以往的方法相比,我们在单阶段检测器上建立了域自适应模型。此外,我们还成功地为单阶段检测器引入了实例级自适应。在多个跨域数据集上的充分实验表明,我们的方法优于先前基于Faster R-CNN的方法,并且提出的三个域自适应模块都是有效的。