聊城做网站的公司咨询网站建设设计稿
Kubernetes K8s从入门到精通系列之十:使用 kubeadm 创建一个高可用 etcd 集群
- 一、etcd高可用拓扑选项
- 1.堆叠(Stacked)etcd 拓扑
- 2.外部 etcd 拓扑
- 二、准备工作
- 三、建立集群
- 1.将 kubelet 配置为 etcd 的服务管理器。
- 2.为 kubeadm 创建配置文件。
- 3.生成证书颁发机构。
- 4.为每个成员创建证书。
- 5.复制证书和 kubeadm 配置。
- 6.确保已经所有预期的文件都存在
- 7.创建静态 Pod 清单。
- 8.可选:检查集群运行状况。
一、etcd高可用拓扑选项
默认情况下,kubeadm 在每个控制平面节点上运行一个本地 etcd 实例。也可以使用外部的 etcd 集群,并在不同的主机上提供 etcd 实例。
可以设置HA集群:
- 使用堆叠控制控制平面节点,其中 etcd 节点与控制平面节点共存
- 使用外部 etcd 节点,其中 etcd 在与控制平面不同的节点上运行
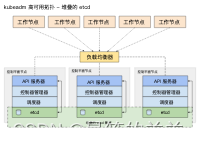
1.堆叠(Stacked)etcd 拓扑
堆叠(Stacked)HA 集群是一种这样的拓扑, 其中 etcd 分布式数据存储集群堆叠在 kubeadm 管理的控制平面节点上,作为控制平面的一个组件运行。
每个控制平面节点运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。 kube-apiserver 使用负载均衡器暴露给工作节点。
每个控制平面节点创建一个本地 etcd 成员(member),这个 etcd 成员只与该节点的 kube-apiserver 通信。 这同样适用于本地 kube-controller-manager 和 kube-scheduler 实例。
这种拓扑将控制平面和 etcd 成员耦合在同一节点上。相对使用外部 etcd 集群, 设置起来更简单,而且更易于副本管理。
然而,堆叠集群存在耦合失败的风险。如果一个节点发生故障,则 etcd 成员和控制平面实例都将丢失, 并且冗余会受到影响。你可以通过添加更多控制平面节点来降低此风险。
因此,你应该为 HA 集群运行至少三个堆叠的控制平面节点。
这是 kubeadm 中的默认拓扑。当使用 kubeadm init 和 kubeadm join --control-plane 时, 在控制平面节点上会自动创建本地 etcd 成员。
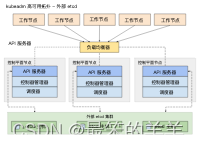
2.外部 etcd 拓扑
具有外部 etcd 的 HA 集群是一种这样的拓扑, 其中 etcd 分布式数据存储集群在独立于控制平面节点的其他节点上运行。
就像堆叠的 etcd 拓扑一样,外部 etcd 拓扑中的每个控制平面节点都会运行 kube-apiserver、kube-scheduler 和 kube-controller-manager 实例。 同样,kube-apiserver 使用负载均衡器暴露给工作节点。但是 etcd 成员在不同的主机上运行, 每个 etcd 主机与每个控制平面节点的 kube-apiserver 通信。
这种拓扑结构解耦了控制平面和 etcd 成员。因此它提供了一种 HA 设置, 其中失去控制平面实例或者 etcd 成员的影响较小,并且不会像堆叠的 HA 拓扑那样影响集群冗余。
但此拓扑需要两倍于堆叠 HA 拓扑的主机数量。 具有此拓扑的 HA 集群至少需要三个用于控制平面节点的主机和三个用于 etcd 节点的主机。
二、准备工作
- 三个可以通过 2379 和 2380 端口相互通信的主机。本文档使用这些作为默认端口。 不过,它们可以通过 kubeadm 的配置文件进行自定义。
- 每个主机必须安装 systemd 和 bash 兼容的 shell。
- 每台主机必须安装有容器运行时、kubelet 和 kubeadm。
- 每个主机都应该能够访问 Kubernetes 容器镜像仓库 (registry.k8s.io), 或者使用 kubeadm config images list/pull 列出/拉取所需的 etcd 镜像。 本指南将把 etcd 实例设置为由 kubelet 管理的静态 Pod。
- 一些可以用来在主机间复制文件的基础设施。例如 ssh 和 scp 就可以满足此需求。
三、建立集群
一般来说,是在一个节点上生成所有证书并且只分发这些必要的文件到其它节点上。
1.将 kubelet 配置为 etcd 的服务管理器。
说明:必须在要运行 etcd 的所有主机上执行此操作。
由于 etcd 是首先创建的,因此你必须通过创建具有更高优先级的新文件来覆盖 kubeadm 提供的 kubelet 单元文件。
cat << EOF > /etc/systemd/system/kubelet.service.d/kubelet.conf
# 将下面的 "systemd" 替换为你的容器运行时所使用的 cgroup 驱动。
# kubelet 的默认值为 "cgroupfs"。
# 如果需要的话,将 "containerRuntimeEndpoint" 的值替换为一个不同的容器运行时。
#
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
authentication:
anonymous:enabled: false
webhook:enabled: false
authorization:
mode: AlwaysAllow
cgroupDriver: systemd
address: 127.0.0.1
containerRuntimeEndpoint: unix:///var/run/containerd/containerd.sock
staticPodPath: /etc/kubernetes/manifests
EOFcat << EOF > /etc/systemd/system/kubelet.service.d/20-etcd-service-manager.conf
[Service]
ExecStart=
ExecStart=/usr/bin/kubelet --config=/etc/systemd/system/kubelet.service.d/kubelet.conf
Restart=always
EOFsystemctl daemon-reload
systemctl restart kubelet
检查 kubelet 的状态以确保其处于运行状态:
systemctl status kubelet
2.为 kubeadm 创建配置文件。
使用以下脚本为每个将要运行 etcd 成员的主机生成一个 kubeadm 配置文件。
# 使用你的主机 IP 更新 HOST0、HOST1 和 HOST2 的 IP 地址
export HOST0=10.0.0.6
export HOST1=10.0.0.7
export HOST2=10.0.0.8# 使用你的主机名更新 NAME0、NAME1 和 NAME2
export NAME0="infra0"
export NAME1="infra1"
export NAME2="infra2"# 创建临时目录来存储将被分发到其它主机上的文件
mkdir -p /tmp/${HOST0}/ /tmp/${HOST1}/ /tmp/${HOST2}/HOSTS=(${HOST0} ${HOST1} ${HOST2})
NAMES=(${NAME0} ${NAME1} ${NAME2})for i in "${!HOSTS[@]}"; do
HOST=${HOSTS[$i]}
NAME=${NAMES[$i]}
cat << EOF > /tmp/${HOST}/kubeadmcfg.yaml
---
apiVersion: "kubeadm.k8s.io/v1beta3"
kind: InitConfiguration
nodeRegistration:name: ${NAME}
localAPIEndpoint:advertiseAddress: ${HOST}
---
apiVersion: "kubeadm.k8s.io/v1beta3"
kind: ClusterConfiguration
etcd:local:serverCertSANs:- "${HOST}"peerCertSANs:- "${HOST}"extraArgs:initial-cluster: ${NAMES[0]}=https://${HOSTS[0]}:2380,${NAMES[1]}=https://${HOSTS[1]}:2380,${NAMES[2]}=https://${HOSTS[2]}:2380initial-cluster-state: newname: ${NAME}listen-peer-urls: https://${HOST}:2380listen-client-urls: https://${HOST}:2379advertise-client-urls: https://${HOST}:2379initial-advertise-peer-urls: https://${HOST}:2380
EOF
done
3.生成证书颁发机构。
如果你已经拥有 CA,那么唯一的操作是复制 CA 的 crt 和 key 文件到 etc/kubernetes/pki/etcd/ca.crt 和 /etc/kubernetes/pki/etcd/ca.key。 复制完这些文件后继续下一步,“为每个成员创建证书”。
如果你还没有 CA,则在 $HOST0(你为 kubeadm 生成配置文件的位置)上运行此命令。
kubeadm init phase certs etcd-ca
这一操作创建如下两个文件:
- /etc/kubernetes/pki/etcd/ca.crt
- /etc/kubernetes/pki/etcd/ca.key
4.为每个成员创建证书。
kubeadm init phase certs etcd-server --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST2}/kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${HOST2}/
# 清理不可重复使用的证书
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -deletekubeadm init phase certs etcd-server --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST1}/kubeadmcfg.yaml
cp -R /etc/kubernetes/pki /tmp/${HOST1}/
find /etc/kubernetes/pki -not -name ca.crt -not -name ca.key -type f -deletekubeadm init phase certs etcd-server --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs etcd-peer --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs etcd-healthcheck-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
kubeadm init phase certs apiserver-etcd-client --config=/tmp/${HOST0}/kubeadmcfg.yaml
# 不需要移动 certs 因为它们是给 HOST0 使用的# 清理不应从此主机复制的证书
find /tmp/${HOST2} -name ca.key -type f -delete
find /tmp/${HOST1} -name ca.key -type f -delete
5.复制证书和 kubeadm 配置。
证书已生成,现在必须将它们移动到对应的主机。
USER=ubuntu
HOST=${HOST1}
scp -r /tmp/${HOST}/* ${USER}@${HOST}:
ssh ${USER}@${HOST}
USER@HOST $ sudo -Es
root@HOST $ chown -R root:root pki
root@HOST $ mv pki /etc/kubernetes/
6.确保已经所有预期的文件都存在
$HOST0 所需文件的完整列表如下:
/tmp/${HOST0}
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd├── ca.crt├── ca.key├── healthcheck-client.crt├── healthcheck-client.key├── peer.crt├── peer.key├── server.crt└── server.key
在 $HOST1 上:
$HOME
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd├── ca.crt├── healthcheck-client.crt├── healthcheck-client.key├── peer.crt├── peer.key├── server.crt└── server.key
在 $HOST2 上:
$HOME
└── kubeadmcfg.yaml
---
/etc/kubernetes/pki
├── apiserver-etcd-client.crt
├── apiserver-etcd-client.key
└── etcd├── ca.crt├── healthcheck-client.crt├── healthcheck-client.key├── peer.crt├── peer.key├── server.crt└── server.key
7.创建静态 Pod 清单。
既然证书和配置已经就绪,是时候去创建清单了。 在每台主机上运行 kubeadm 命令来生成 etcd 使用的静态清单。
root@HOST0 $ kubeadm init phase etcd local --config=/tmp/${HOST0}/kubeadmcfg.yaml
root@HOST1 $ kubeadm init phase etcd local --config=$HOME/kubeadmcfg.yaml
root@HOST2 $ kubeadm init phase etcd local --config=$HOME/kubeadmcfg.yaml
8.可选:检查集群运行状况。
如果 etcdctl 不可用,你可以在容器镜像内运行此工具。 你可以使用 crictl run 这类工具直接在容器运行时执行此操作,而不是通过 Kubernetes。
ETCDCTL_API=3 etcdctl \
--cert /etc/kubernetes/pki/etcd/peer.crt \
--key /etc/kubernetes/pki/etcd/peer.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
--endpoints https://${HOST0}:2379 endpoint health
...
https://[HOST0 IP]:2379 is healthy: successfully committed proposal: took = 16.283339ms
https://[HOST1 IP]:2379 is healthy: successfully committed proposal: took = 19.44402ms
https://[HOST2 IP]:2379 is healthy: successfully committed proposal: took = 35.926451ms
- 将 ${HOST0} 设置为要测试的主机的 IP 地址。