虚拟主机搭建网站外贸网络营销的优势
一、源码特点
asp.net特色商品购物网站系统 是一套完善的web设计管理系统,系统采用mvc模式(BLL+DAL+ENTITY)系统具有完整的源代码和数据库,系统主要采用B/S模式开发。开发环境为
vs2010,数据库为sqlserver2008,使用c#语言开发
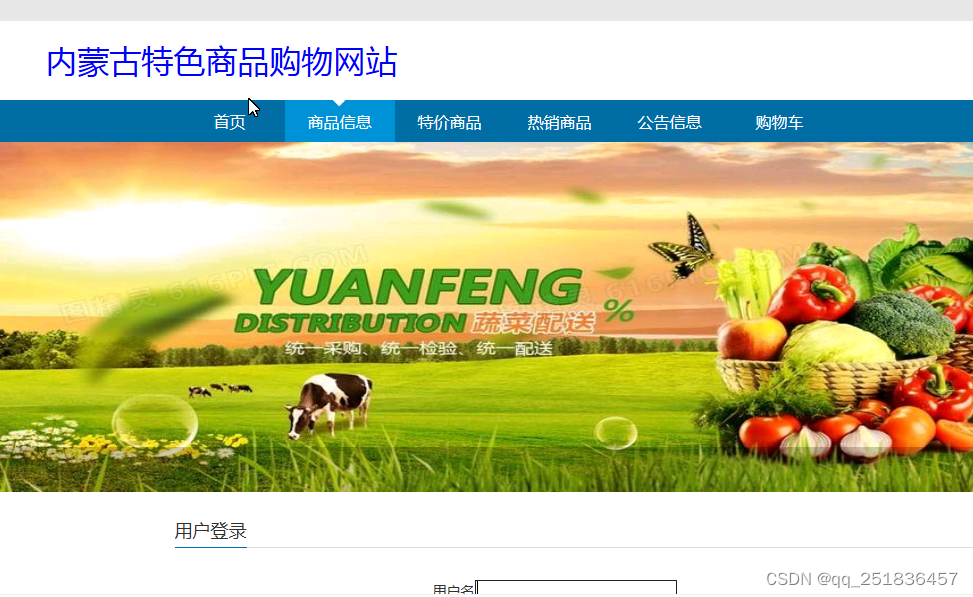
ASP.NET 内蒙古特色商品购物网站1
二、功能介绍
前台功能
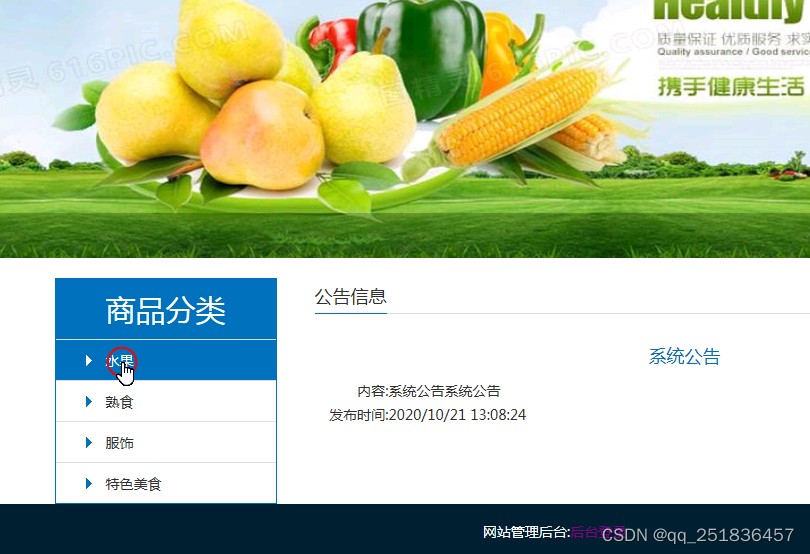
首页浏览
会员注册、登录
商品浏览 加入购物车 提交订单
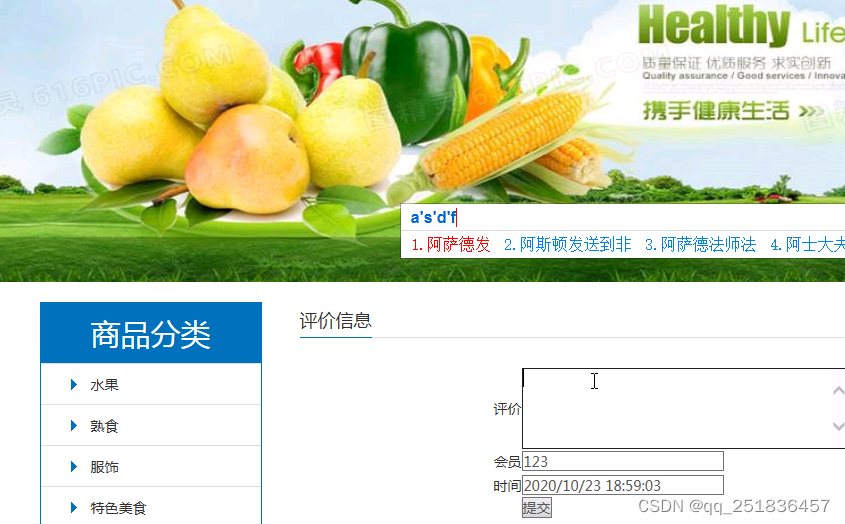
查看订单 对订单评价
个人信息修改
公告浏览
后台功能:
(1)管理员管理:对管理员信息进行添加、删除、修改和查看
(2)会员管理:对会员信息进行添加、删除、修改和查看
(3)公告管理:对公告信息进行添加、删除、修改和查看
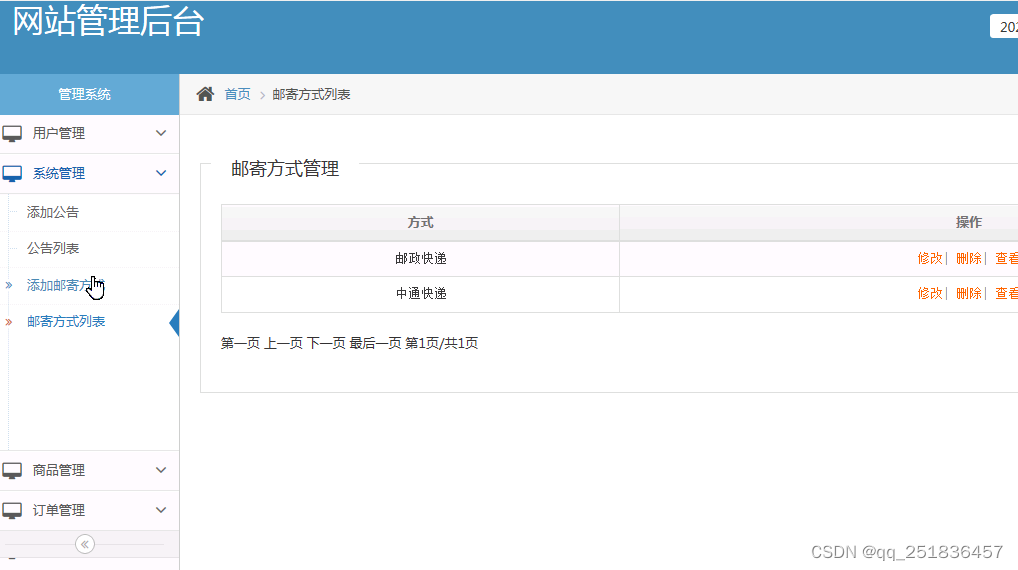
(4)邮寄方式管理:对邮寄方式信息进行添加、删除、修改和查看
(5)商品类别管理:对商品类别信息进行添加、删除、修改和查看
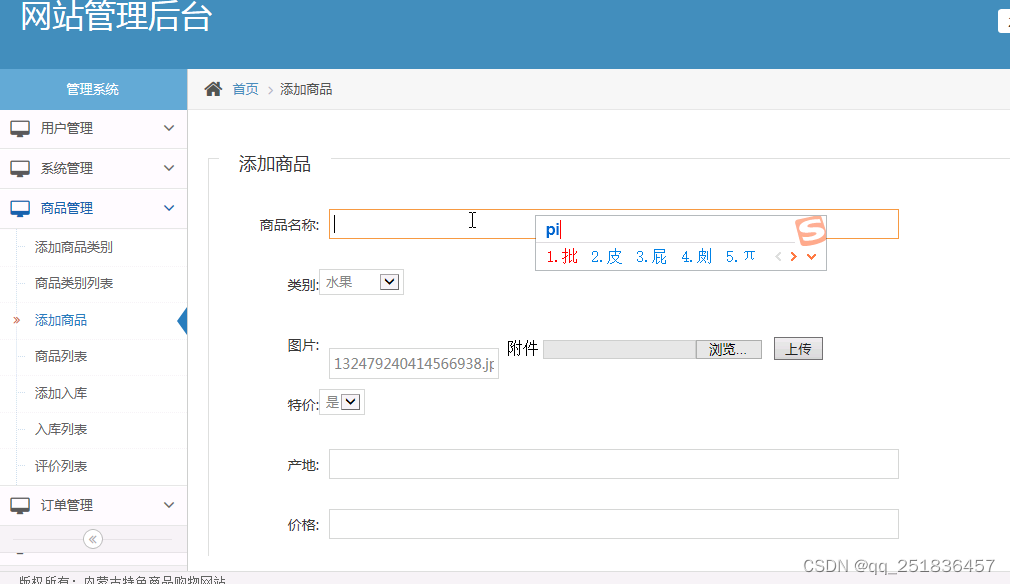
(6)商品管理:对商品信息进行添加、删除、修改和查看
(7)入库管理:对入库信息进行添加、删除和查看
(8)评价管理:对评价信息进行删除、修改和查看
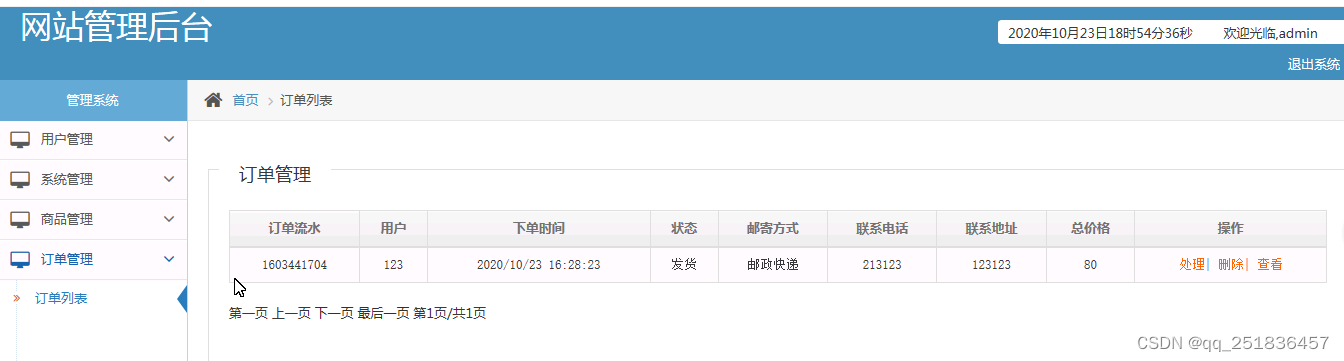
(9)订单管理:对订单信息进行添加、删除、修改和查看
数据库设计
表5-2 管理员信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | glyid | INTEGER | 11 | 是 | 管理员编号 |
| 2 | yhm | VARCHAR | 40 | 否 | 用户名 |
| 3 | mm | VARCHAR | 40 | 否 | 密码 |
| 4 | xm | VARCHAR | 40 | 否 | 姓名 |
表5-3 会员信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | hyid | INTEGER | 11 | 是 | 会员编号 |
| 2 | yhm | VARCHAR | 40 | 否 | 用户名 |
| 3 | mm | VARCHAR | 40 | 否 | 密码 |
| 4 | xm | VARCHAR | 40 | 否 | 姓名 |
| 5 | lxdh | VARCHAR | 40 | 否 | 联系电话 |
| 6 | lxdz | VARCHAR | 40 | 否 | 联系地址 |
| 7 | xb | VARCHAR | 40 | 否 | 性别 |
| 8 | yx | VARCHAR | 40 | 否 | 邮箱 |
表5-5 公告信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | ggid | INTEGER | 11 | 是 | 公告编号 |
| 2 | bt | VARCHAR | 40 | 否 | 标题 |
| 3 | nr | VARCHAR | 40 | 否 | 内容 |
| 4 | fbsj | VARCHAR | 40 | 否 | 发布时间 |
表5-6 邮寄方式信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | yjfsid | INTEGER | 11 | 是 | 邮寄方式编号 |
| 2 | fs | VARCHAR | 40 | 否 | 方式 |
表5-7 商品类别信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | splbid | INTEGER | 11 | 是 | 商品类别编号 |
| 2 | lb | VARCHAR | 40 | 否 | 类别 |
表5-8 商品信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | spid | INTEGER | 11 | 是 | 商品编号 |
| 2 | spmc | VARCHAR | 40 | 否 | 商品名称 |
| 3 | lb | VARCHAR | 40 | 否 | 类别 |
| 4 | js | VARCHAR | 40 | 否 | 介绍 |
| 5 | tp | VARCHAR | 40 | 否 | 图片 |
| 6 | tj | VARCHAR | 40 | 否 | 特价 |
| 7 | cd | VARCHAR | 40 | 否 | 产地 |
| 8 | jg | VARCHAR | 40 | 否 | 价格 |
| 9 | kc | VARCHAR | 40 | 否 | 库存 |
表5-9 入库信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | rkid | INTEGER | 11 | 是 | 入库编号 |
| 2 | sp | VARCHAR | 40 | 否 | 商品 |
| 3 | rksl | VARCHAR | 40 | 否 | 入库数量 |
| 4 | rksj | VARCHAR | 40 | 否 | 入库时间 |
| 5 | rkr | VARCHAR | 40 | 否 | 入库人 |
表5-10 评价信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | pjid | INTEGER | 11 | 是 | 评价编号 |
| 2 | sp | VARCHAR | 40 | 否 | 商品 |
| 3 | pj | VARCHAR | 40 | 否 | 评价 |
| 4 | hy | VARCHAR | 40 | 否 | 会员 |
| 5 | sj | VARCHAR | 40 | 否 | 时间 |
表5-11 订单信息表
| 序号 | 字段名称 | 数据类型 | 长度 | 主键 | 描述 |
| 1 | ddid | INTEGER | 11 | 是 | 订单编号 |
| 2 | ddls | VARCHAR | 40 | 否 | 订单流水 |
| 3 | yh | VARCHAR | 40 | 否 | 用户 |
| 4 | xdsj | VARCHAR | 40 | 否 | 下单时间 |
| 5 | zt | VARCHAR | 40 | 否 | 状态 |
| 6 | yjfs | VARCHAR | 40 | 否 | 邮寄方式 |
| 7 | lxdh | VARCHAR | 40 | 否 | 联系电话 |
| 8 | lxdz | VARCHAR | 40 | 否 | 联系地址 |
| 9 | zjg | VARCHAR | 40 | 否 | 总价格 |
代码设计
public static bool Adddingdan(ENTITY.dingdan dingdan){//对表dingdan 订单 添加return DAL.daldingdan.Adddingdan(dingdan);}public static ENTITY.dingdan getdingdan(int ddid){//对表dingdan 查询订单信息return DAL.daldingdan.getdingdaninfo(ddid);}public static bool Editdingdan(ENTITY.dingdan dingdan){//对表dingdan 订单 修改return DAL.daldingdan.Editdingdan(dingdan);}public static bool Deldingdan(string p){//对表dingdan 订单 删除return DAL.daldingdan.Deldingdan(p);}public static System.Data.DataTable querydingdan(string p){//对表dingdan 订单 分页查询return DAL.daldingdan.querydingdan(p);}public static System.Data.DataSet getAlldingdan(){//对表dingdan 订单 查询所有信息return DAL.daldingdan.getAlldingdan("");}
三、注意事项
1、管理员账号:admin 密码:admin
2、开发环境为vs2010,数据库为sqlserver2008,或者 以上版本都可以,使用c#语言开发。
3、数据库文件名是netmgshop.mdf
4.登录地址:qt/index.aspx
四系统实现