备案号 不放在网站首页网络信息科技公司经营范围
开启靶场,打开链接:

是个贪吃蛇小游戏,看不出来有什么特别的地方
用burp抓包看看情况:
嗯?点击“开始”没有抓取到报文,先看看网页源代码是什么情况
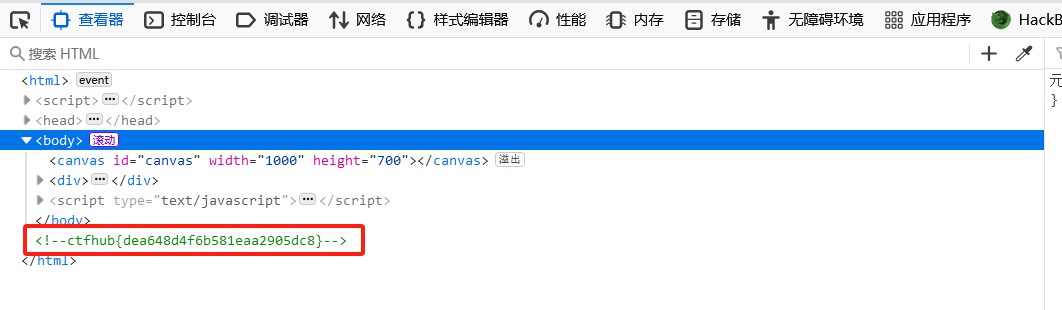
居然直接给出flag了,不知道这题的意义何在
ctfhub{dea648d4f6b581eaa2905dc8}
开启靶场,打开链接:
是个贪吃蛇小游戏,看不出来有什么特别的地方
用burp抓包看看情况:
嗯?点击“开始”没有抓取到报文,先看看网页源代码是什么情况
居然直接给出flag了,不知道这题的意义何在
ctfhub{dea648d4f6b581eaa2905dc8}