增城做网站公司游戏开发需要学多久
开发技术:
node.js,mysql5.7,vscode,HBuilder
nodejs express vue uniapp
功能介绍:
用户端:
登录注册
首页显示搜索新闻,新闻分类,新闻列表
点击新闻进入新闻详情(可展示视频),可以评论
个人中心显示我的信息(可编辑)
后台管理:
统计分析:查看用户,新闻,评论数量,近7天浏览记录趋势
用户管理:查看注册用户信息,及删除
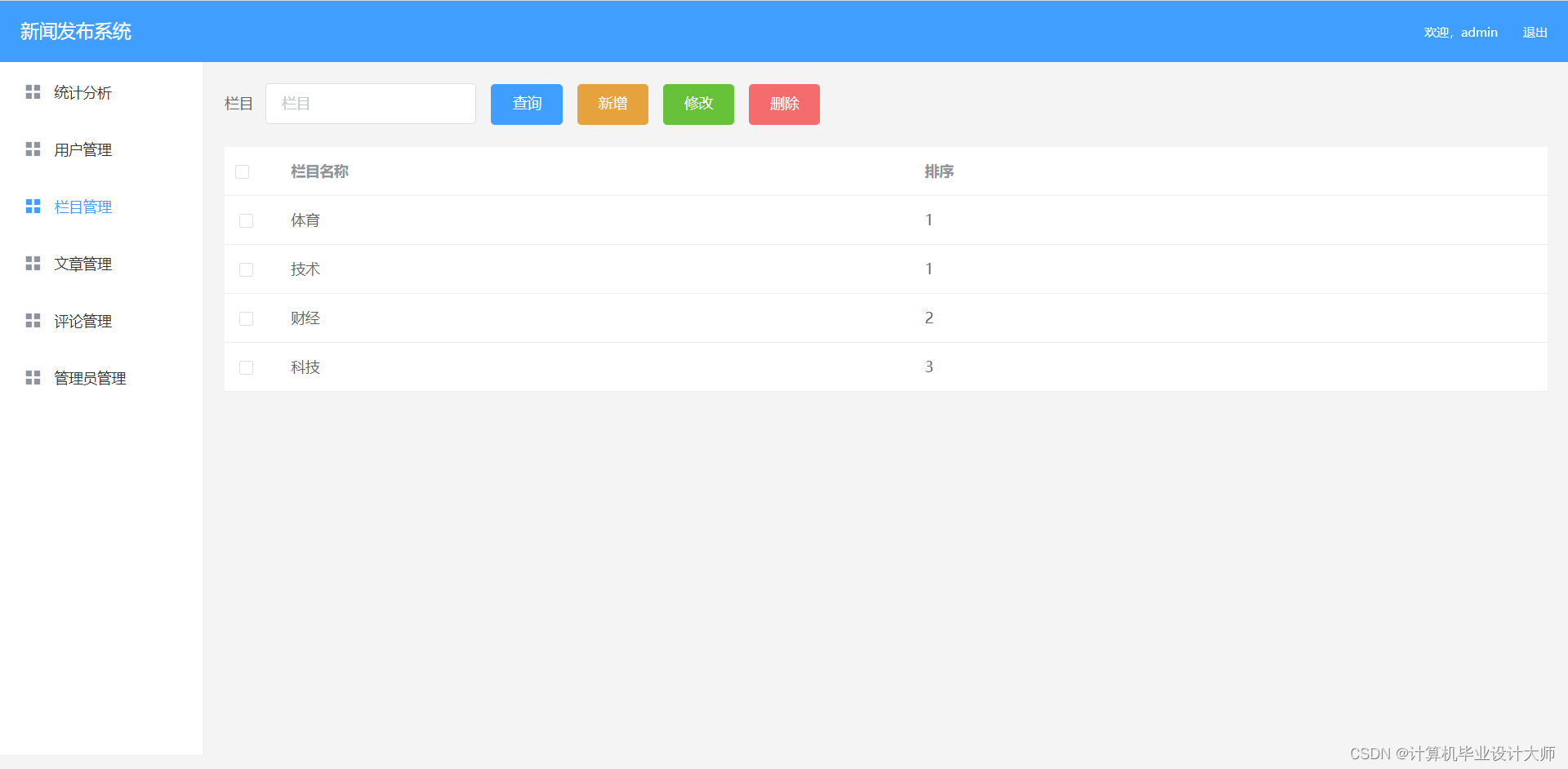
分类管理:新闻分类增删改查
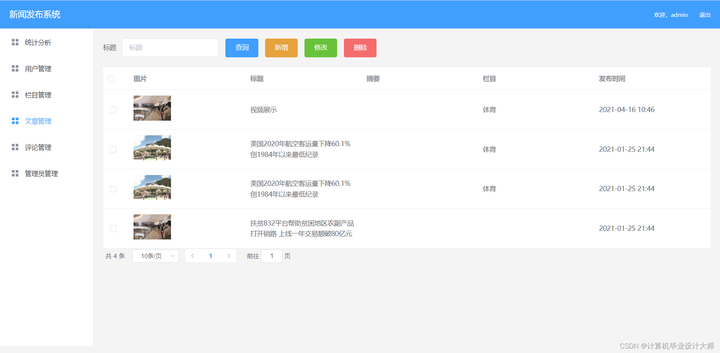
新闻管理:新闻增删改查(可传视频)
评论管理:查看用户评论,及删除
管理员管理:后台管理员增删改查
代码截图:

项目截图: