制作简易网站网页设计平均工资
今天给大家带来的是上海电力大学控制考研分析
满满干货~还不快快点赞收藏
一、上海电力大学

学校简介
上海电力大学(Shanghai University of Electric Power),位于上海市,是中央与上海市共建、以上海市管理为主的全日制普通高等院校,是教育部首批“卓越工程师教育培养计划”试点院校、上海高水平地方应用型高校建设单位、上海市首批深化创新创业教育改革示范高校,为国际电力高校联盟永久理事长单位、全球能源互联网发展合作组织会员单位、中国电力高校联盟成员单位、一带一路电力高校联盟和一带一路电力产学研联盟发起成员单位,入选国家级新工科研究与实践项目、国家级大学生创新创业训练计划、上海高校知识服务能力提升工程、上海高等学校一流本科建设引领计划、上海高等学校一流研究生教育引领计划、上海市级新工科研究与改革实践项目。
学院简介
学院设有自动化、测控技术与仪器、核电技术与控制工程、智能科学与技术4个本科专业,其中自动化专业为国家级一流本科专业、国家级特色专业建设点、上海市教育高地建设点、卓越工程师培养计划和上海市一流本科专业,于2021年通过中国工程教育认证,在2022软科中国大学专业排名为B+,全国244个学校上榜专业中排名第65;
测控技术与仪器专业为上海市一流本科专业,于2022年11月完成中国工程教育认证专家线上考查。自动化、测控技术与仪器专业都列入了上海市属高校应用型本科试点专业。学院拥有“控制科学与工程”一级学科学术型硕士点,以及“电子信息(控制工程)”、“电子信息(人工智能)”、“能源动力(清洁能源技术)”等专业学位硕士点。
拥有《自动控制原理》国家级一流本科课程,《计算机硬件技术》、《过程控制系统设计》和《汽轮机监测与保护虚拟仿真实验》等上海市一流本科课程,以及《自动控制原理》、《数字电子技术》、《计算机硬件技术》、《过程控制系统设计》、《检测技术》等上海市精品课程,《控制系统仿真》上海市全英文教学示范课程和《电力特色过程控制系统实践》上海高校国际学生英语授课示范性课程。《自动控制原理》获批2022年上海市课程思政示范课,《“智能+”能源电力特色的自动化专业人才培养体系改革与实践》荣获2022年上海市高等教育优秀教学成果一等奖。
二、近三年分数信息对比
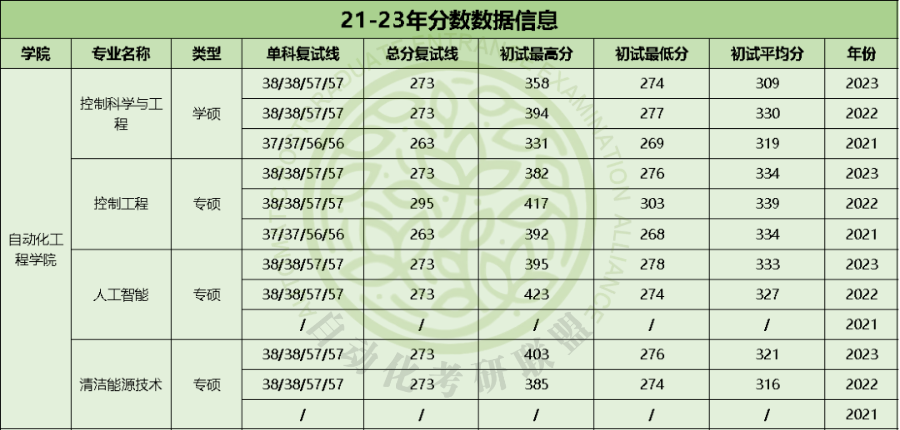

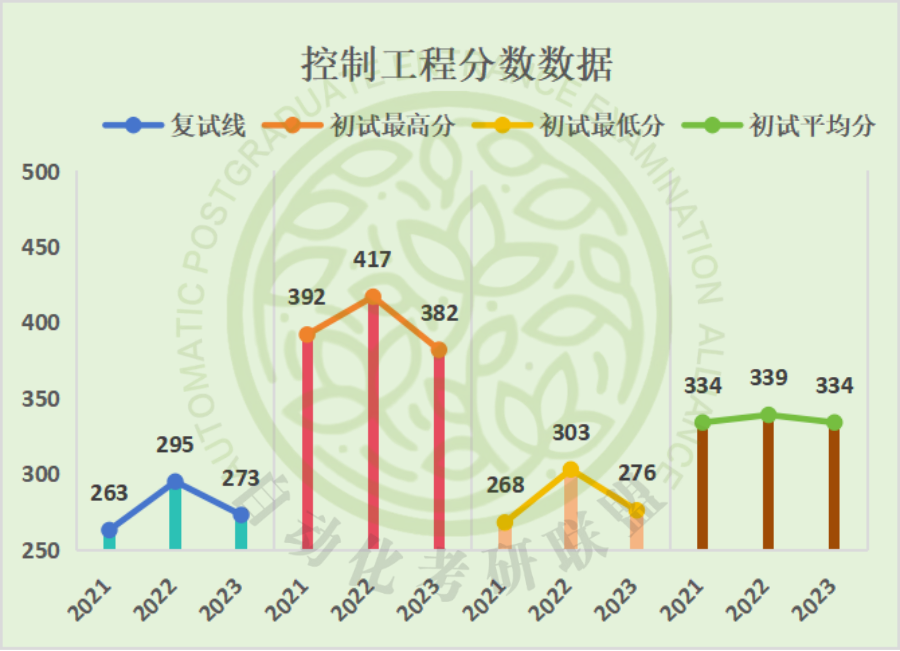

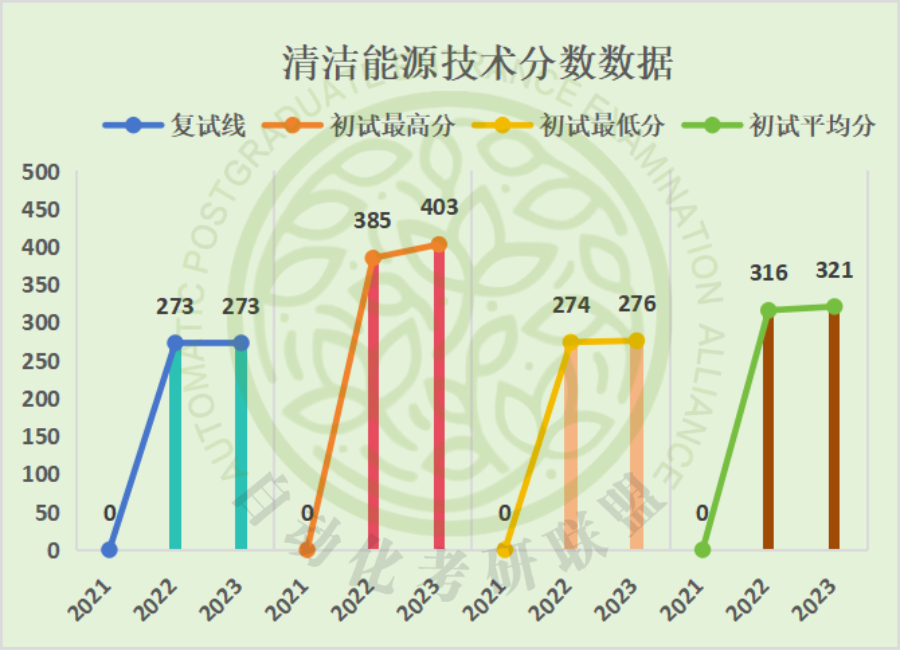
三、考试科目
控制科学与工程(专业代码081100)
初试内容:
①201英语一
②301数学一
③830自动控制原理
复试内容
单片机原理及应用、自动控制原理、过程控制原理三选一,不能与初试相同
控制工程(专业代码085406)
初试内容:
①204英语二
②302数学二
③830自动控制原理
复试内容:
单片机原理及应用、自动控制原理、过程控制原理三选一,不能与初试相同
人工智能(专业代码085410)
初试内容:
①204英语二
②302数学二
③830自动控制原理
复试内容:
单片机原理及应用、自动控制原理、过程控制原理三选一,不能与初试相同
清洁能源技术(专业代码085807)
初试内容:
①204英语二
②302数学二
③830自动控制原理
复试内容:
单片机原理及应用、自动控制原理、过程控制原理三选一,不能与初试相同
四、初试考试大纲&参考书目

830自动控制原理
杨平 等.自动控制原理-理论篇(第3版),中国电力出版社,2016

杨平 等.自动控制原理-练习与测试篇,中国电力出版社,2012

五、复试大纲
1.F024过程控制及系统设计考试大纲


参考书目
王再英、刘淮霞、彭倩编著. 《过程控制系统与仪表》(第2版),机械工业出版社,2020年 。

2.F002单片机原理及应用







参考书目
1. 程启明, 黄云峰, 徐进, 赵永熹. 基于汇编与C语言的单片机原理及应用. 北京: 中国水利水电出版社. 2012.10

2. 郭天祥. 新概念51单片机C语言教程-入门、提高、开发、拓展全攻略. 北京. 电子工业出版社. 2015.12

3.程启明, 徐进 黄云峰, 杨艳华. 基于汇编与C语言的单片机实践与学习指导. 北京: 中国水利水电出版社. 2019.7


六、近三年录取情况
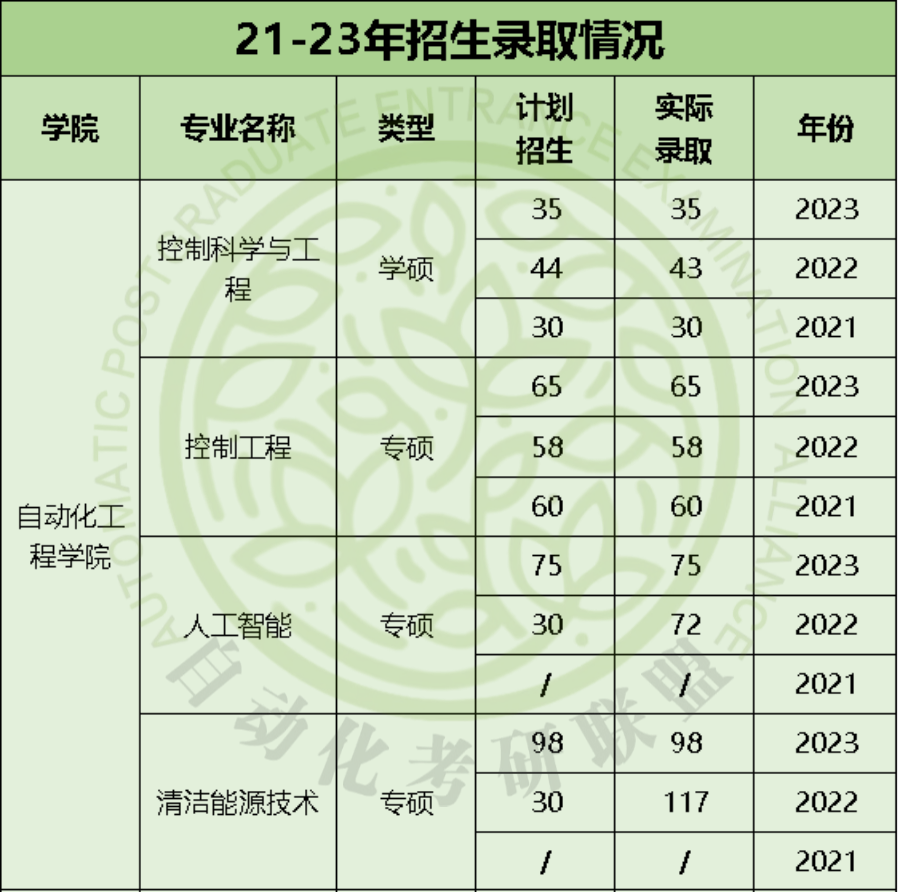
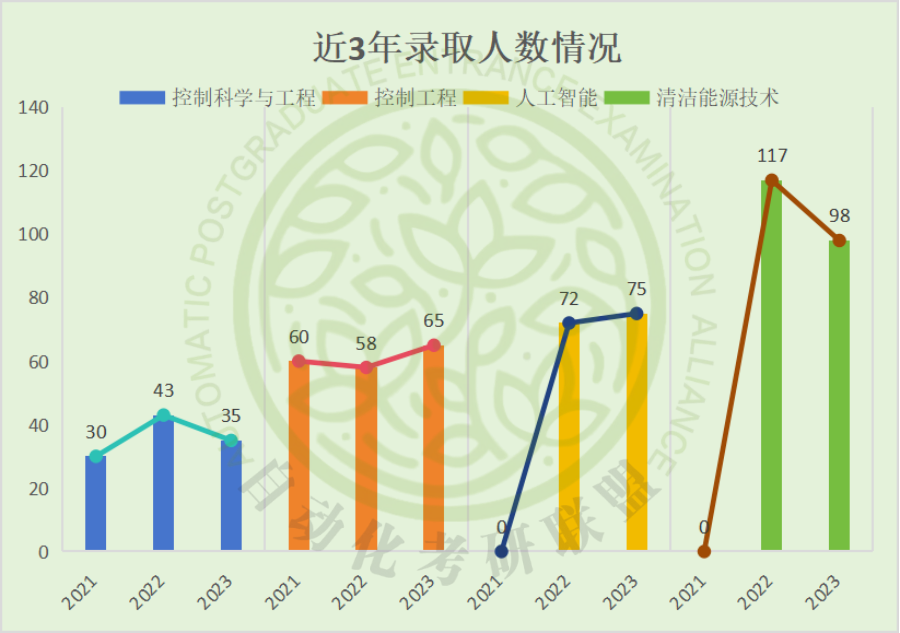
注:计划招生和实际招生有所出入,大家以官网信息为准。

七、学费&奖学金&就业方向
学费

奖学金
上海电力大学奖学金分为:
国家奖学金、国家助学金、校长奖学金、新生入学奖学金、课程奖学金、成果奖学金、企业奖学金、“三助”助学金及相关配套政策措施的研究生奖助体系。
全日制硕士研究生奖学金获奖比例超过90%,国家助学金获得资助比例达到100%。
此外,全日制硕士研究生在学期间表现优异的可获得国家奖学金奖励,每人奖励2万元。在校研究生还可通过“三助”岗位获得劳务报酬及助研津贴。非全日制硕士研究生不享受奖助学金。
就业方向
自动化专业毕业生就业率一直保持在95%以上。就业方向包括IT行业、交通行业和汽车制造业。工作单位包括IT公司、高速公路管理公司、城市轨道交通公司以及科研院所和政府机关等。就业地区主要分布在各主要省会城市。

八、Q&A
Q : 我想知道其他学校的考研信息,该怎样获取呢?
A : 如果你有什么想了解的,例如学校往年的自动化报考情况、复试笔试的难易情况、面试涉及的主要问题、就业待遇等信息,可以后台私信留言哦~学姐一定知无不答,言无不尽!