河北集团网站建设团队介绍网站建设
一、问题背景
因为在fluent中用Discard Data, Replace Mesh选项替换了网格,但是没有抛弃算例设置等参数。
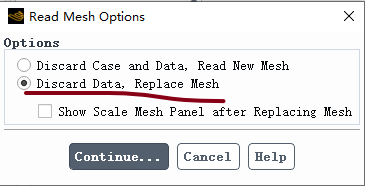
当时我以为网格是完全一样的,便忽略了产生冲突/错误的可能。
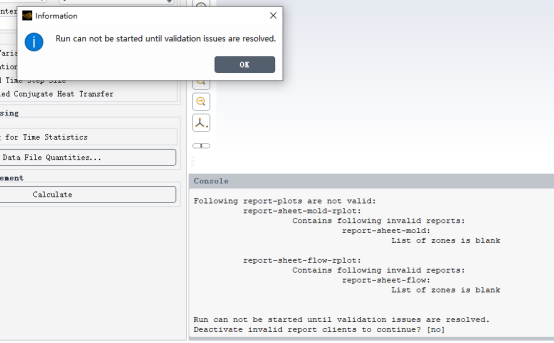
之后在calculate的时候,报错:Run can not be started until validation issues are resolved.
二、解决办法
Run can not be started until validation issues are resolved.的错误信息,总归是抽象和无从下手的。
我们在console中多向上翻翻,就会发现Following report-plota are not valid。
大概可以猜测到是导入新的网格后,边界命名等改变,导致一些报告监测的定义出现了依赖对象缺失的问题。
于是乎,展开Report Definitions,就可以发现fluent给有问题的报告监测打上了invalid的标号,非常贴心!
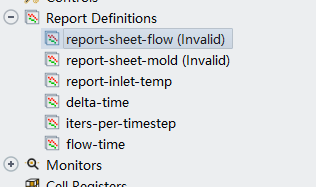
我们将它们删除或者更改为正确的设置,然后在Monitors下的Report Files、Report Plots中,将在Definitions中确定为invalid的定义删除或更改。(下图是已经删除了invalid的情况)

三、扩展篇
如果你只得到Run can not be started until validation issues are resolved.错误信息,并没有上图中console的Following report-plots are not valid的描述。
那么其实也可能是授权证书的问题,一个license只能用一个算例。
你记得不要同时启动太多fluent在一台机器上计算。