网站制作语言有哪些做网站 用什么空间
文章目录
- 前言
- 1. MacOS打开远程登录
- 2. 局域网内测试ssh远程
- 3. 公网ssh远程连接MacOS
- 3.1 MacOS安装配置cpolar
- 3.2 获取ssh隧道公网地址
- 3.3 测试公网ssh远程连接MacOS
- 4. 配置公网固定TCP地址
- 4.1 保留一个固定TCP端口地址
- 4.2 配置固定TCP端口地址
- 5. 使用固定TCP端口地址ssh远程
💡推荐
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。【点击跳转到网站】
前言
本次教程将分享如何使用cpolar内网穿透工具,映射ssh服务默认端口:22端口,获取公网地址,实现在公网环境下的ssh远程登录MacOS系统设备,无需公网IP,也无需设置路由器。
MacOS系统自带有Secure Shell 客户端,它可让您登录到侦听传入SSH连接的远程服务器和台式机。我们可以用ssh username@ip来ssh到服务器,但通常局限于局域网内的远程。
1. MacOS打开远程登录
- 打开系统偏好设置,点击
共享

- 勾选打开
远程登录,复制右侧的ssh远程登录命令

2. 局域网内测试ssh远程
本例以windows系统测试ssh远程,点击开始菜单栏搜索cmd,打开命令提示符,输入ssh命令,提示确认,输入yes并回车,提示输入MacOS登录密码
ssh username@ip地址
如:
ssh eve@192.168.0.106
局域网内ssh远程登录MacOS成功。

3. 公网ssh远程连接MacOS
当成功实现在局域网内ssh远程登录MacOS后,接下来,我们将通过cpolar内网穿透映射22端口,实现在公网环境下ssh远程连接MacOS,无需公网IP,也无需设置路由器。
cpolar官网:https://www.cpolar.com/
3.1 MacOS安装配置cpolar
MacOS安装cpolar内网穿透可通过homebrew包管理器进行安装,无需手动下载安装包。
- 安装homebrew
Homebrew是一款Mac OS下的套件管理工具,拥有安装、卸载、更新、查看、搜索等很多实用的功能。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
- 通过Homebrew包管理器安装cpolar内网穿透
brew tap probezy/core && brew install cpolar
- token认证
登录cpolar官网后台,点击左侧的验证,查看自己的认证token,之后将token贴在命令行里
cpolar authtoken xxxxxxx

- 安装服务
sudo cpolar service install
- 启动服务
sudo cpolar service start
- 登录cpolar web UI管理界面
在浏览器上访问本地9200端口【http://127.0.0.1:9200/】,使用cpolar账号登录。

登录成功后,点击左侧仪表盘的隧道管理——隧道列表,可以看到两条样例隧道(可自行编辑或者删减)
- ssh隧道:指向本地22端口,tcp协议
- website隧道:指向本地8080端口,tcp协议
本次我们可以直接使用ssh样例隧道,或者也可以创建一条新的隧道。

3.2 获取ssh隧道公网地址
点击左侧仪表盘的状态——在线隧道列表,找到ssh隧道,可以看到系统有自动生成相应的公网地址,将其复制下来,注意tcp://无需复制,本例为6.tcp.cpolar.top:14946。

3.3 测试公网ssh远程连接MacOS
打开命令提示符,输入ssh命令:
ssh MacOS用户名@公网地址 -p 公网端口号
注意:由于我们的本地22端口到了公网被映射到了14946端口,所以,ssh命令需要加-p参数,后面加公网隧道端口号
如:
ssh eve@6.tcp.cpolar.top -p 14946

ssh远程登录成功!
4. 配置公网固定TCP地址
cpolar默认安装的ssh样例隧道使用的是随机端口地址,它会在24小时内随机变化,这对于经常访问的用户,或者生产环境的服务来说很不方便。为此,我们可以为其配置一个永久固定的公网TCP地址来进行远程,同时提高带宽。
注意需要将cpolar套餐升级至专业套餐或以上。
4.1 保留一个固定TCP端口地址
登录cpolar官网后台,点击左侧的预留,找到保留的TCP地址:
- 地区:选择China VIP
- 描述:即备注,可自定义填写
点击保留

固定TCP地址保留成功,系统生成相应的公网地址+固定端口号,将其复制下来

4.2 配置固定TCP端口地址
访问http://127.0.0.1:9200/登录cpolar web UI管理界面,点击左侧仪表盘的隧道管理——隧道列表,找到ssh隧道,点击右侧的编辑

修改隧道信息,配置固定TCP端口地址:
- 端口类型:改为选择
固定TCP端口 - 预留的TCP地址:填写刚刚保留成功的固定TCP端口地址
点击更新

提示更新隧道成功,点击左侧仪表盘的状态——在线隧道列表,可以看到ssh隧道的公网地址已经更新为固定TCP端口地址,将其复制下来。

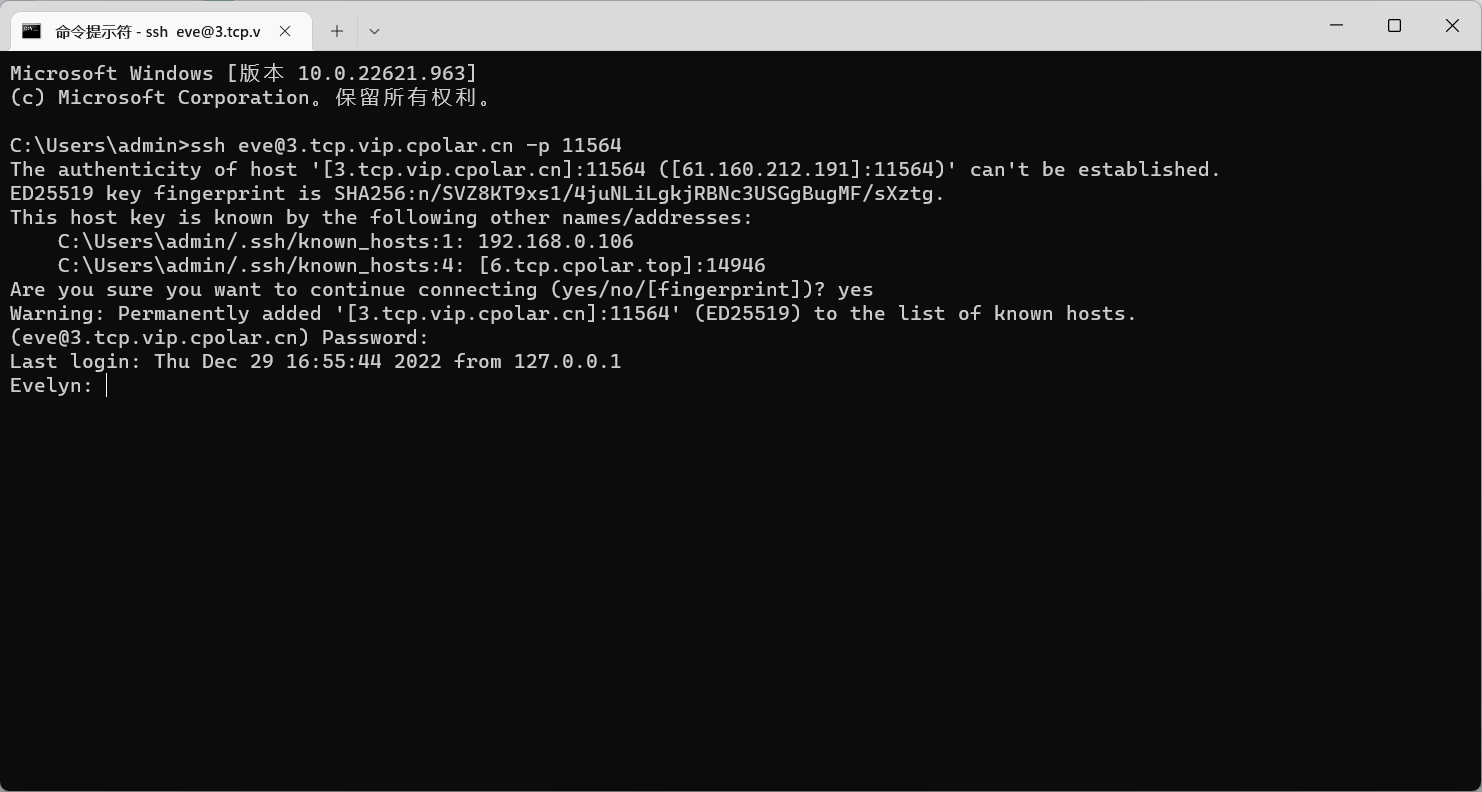
5. 使用固定TCP端口地址ssh远程
ssh eve@3.tcp.vip.cpolar.cn -p 11564
ssh远程登录成功,现在该公网地址不会再随机变化。