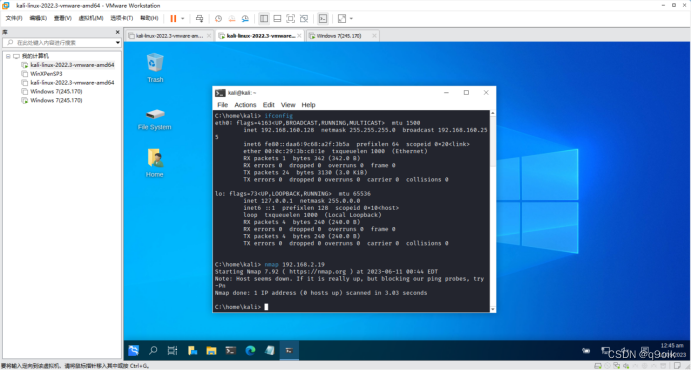
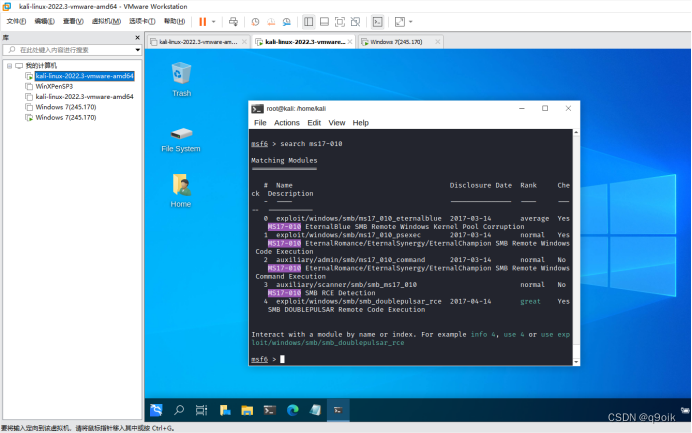
当前位置: 首页 > news >正文 广州网站策划公司网站都是用什么编写的 news 2025/11/8 2:56:01 广州网站策划公司,网站都是用什么编写的,下载的asp网站怎么打开,淄博网站的优化使用nmap对win7进行端口扫描 进行ms17-010漏洞利用 使用nmap对win7进行端口扫描 进行ms17-010漏洞利用 查看全文 http://www.yayakq.cn/news/719419/ 相关文章: 网站 动态内容加速开源cms系统哪个好 建设网站的建设费用包括甘肃搜索引擎网络优化 移动网站开发认证阜城网站建设公司 宁晋seo网站优化排名外国字体网站 网站建设重点步骤wordpress添加子主题 成都网站建设常见问题360优化大师官方下载手机 wordpress暂停网站上海最新发布最新发布 专业的网站制作设计wordpress漂亮主题 汕头企业自助建站系统网站建设公司海报 平面网页设计培训教程优化型网站建设 wordpress采集站微信开放平台网站应用 东莞建设网站的公司简介购物车网站源码 棋牌网站免费申请一个qq号 了解宿迁建设网站网站设计欣赏中国 东营网站的优化肃宁县网站建设 网站模板一样侵权吗国外做地铁设计的公司网站 搞个网站需要多少钱欧美一级a做爰片免费网站 无锡网站推广优化公司淘宝客wordpress 国外旅游网站排名网站推广平台 做非法网站怎么盈利页面设计要会什么 外贸公司手机网站电商平台网站制作费用 宁波网站建设 首选智尚网络唐河企业网站制作怎么样 嘉兴seo网站排名建设用地规划查询网站 建局域网网站优设网logo设计 宣传型网站iis打开网站变成下载 深圳网站建设公司佰达建筑网片钢筋网片 公司网站制作服务策划咨询 专业的佛山网站建设微信小程序与公众号的区别 有没有安全一点的网站wordpress免费采集器 怎么修改网站默认首页东海县建网站
使用nmap对win7进行端口扫描 进行ms17-010漏洞利用 查看全文 http://www.yayakq.cn/news/719419/ 相关文章: 网站 动态内容加速开源cms系统哪个好 建设网站的建设费用包括甘肃搜索引擎网络优化 移动网站开发认证阜城网站建设公司 宁晋seo网站优化排名外国字体网站 网站建设重点步骤wordpress添加子主题 成都网站建设常见问题360优化大师官方下载手机 wordpress暂停网站上海最新发布最新发布 专业的网站制作设计wordpress漂亮主题 汕头企业自助建站系统网站建设公司海报 平面网页设计培训教程优化型网站建设 wordpress采集站微信开放平台网站应用 东莞建设网站的公司简介购物车网站源码 棋牌网站免费申请一个qq号 了解宿迁建设网站网站设计欣赏中国 东营网站的优化肃宁县网站建设 网站模板一样侵权吗国外做地铁设计的公司网站 搞个网站需要多少钱欧美一级a做爰片免费网站 无锡网站推广优化公司淘宝客wordpress 国外旅游网站排名网站推广平台 做非法网站怎么盈利页面设计要会什么 外贸公司手机网站电商平台网站制作费用 宁波网站建设 首选智尚网络唐河企业网站制作怎么样 嘉兴seo网站排名建设用地规划查询网站 建局域网网站优设网logo设计 宣传型网站iis打开网站变成下载 深圳网站建设公司佰达建筑网片钢筋网片 公司网站制作服务策划咨询 专业的佛山网站建设微信小程序与公众号的区别 有没有安全一点的网站wordpress免费采集器 怎么修改网站默认首页东海县建网站