广州建设工程造价管理网站网站建设互联网推广
通常情况下,我们可以使用GET或POST来发送请求和数据,但GET和POST两种方法所携带的数据都是比较简单的数据,接下来在我们这个基础上,列举5种比较负责的参数传递方法,并对这些参数如何发送,后台改如何接收做详细的讲解。
常见的参数种类有:
·普通参数
·POJO类型参数
·嵌套POJO类型参数
·数组类型参数
·集合类型参数
普通参数
普通参数:url地址传参,地址参数名与形参变量名相同,定义形参即可接收参数。

如果形参与地址参数名不一致该如何解决呢?
发送请求与参数,示例代码如下:
http://localhost/commonParamDifferentName?name=张三&age=18后台接收参数:
@RequestMapping("/commonParamDifferentName")
@ResponseBody
public String commonParamDifferentName(String userName, int age) {System.out.println("普通参数传递 userName ==> " + userName);System.out.println("普通参数传递 age ==> " + age);return "{'module':'common param different name'}";
}因为前端给的是name ,后台接收使用的是userName ,两个名称对不上,导致接收数据失败:

使用@RequestParam注解,可以避免接受数据失败。
@RequestMapping("/commonParamDifferentName")@ResponseBodypublic String commonParamDifferentName(@RequestPaam("name") String
userName, int age) {System.out.println("普通参数传递 userName ==> " + userName);System.out.println("普通参数传递 age ==> " + age);return "{'module':'common param different name'}";
}注意:写上@RequestParam注解框架就不需要自己去解析注入,能提升框架处理性能。
POJO数据类型
简单数据类型一般处理的是参数个数比较少的请求,如果参数比较多,那么后台接收参数的时候就比较复杂,这个时候我们可以考虑使用POJO数据类型。
POJO参数:请求参数名与形参对象属性名相同,定义POJO类型形参即可接收参数此时需要使用前面准备好的POJO类,先来看下User
public class User {private String name;private int age;//setter...getter...略
}发送请求和参数:
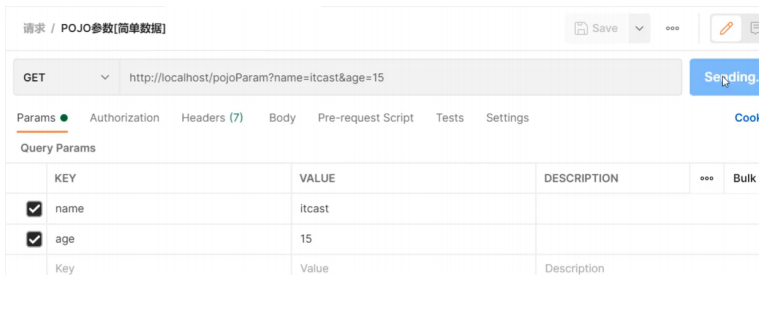
后台接收参数:
//POJO参数:请求参数与形参对象中的属性对应即可完成参数传递
@RequestMapping("/pojoParam")
@ResponseBody
public String pojoParam(User user){System.out.println("pojo参数传递 user ==> "+user);return "{'module':'pojo param'}";
}注意:
POJO参数接收,前端GET和POST发送请求数据的方式不变。 请求参数key的名称要和POJO中属性的名称一致,否则无法封装。
嵌套POJO类型参数
如果POJO对象中嵌套了其他的POJO类,如:
public class Address {private String province;private String city;//setter...getter...略
}
public class User {private String name;private int age;private Address address;//setter...getter...略
}嵌套POJO参数:请求参数名与形参对象属性名相同,按照对象层次结构关系即可接收嵌套POJO属性参数发送请求和参数:
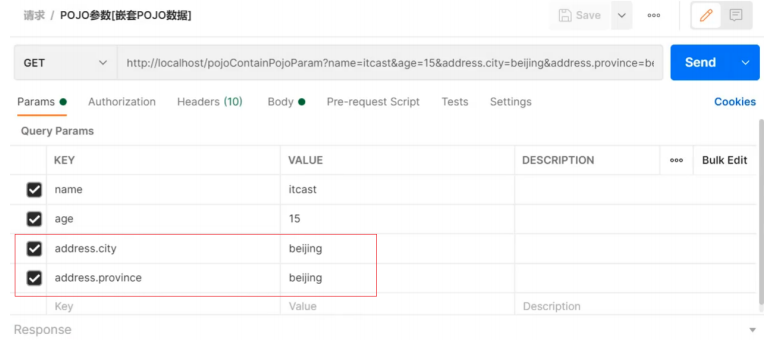
后台接收参数:
//POJO参数:请求参数与形参对象中的属性对应即可完成参数传递
@RequestMapping("/pojoParam")
@ResponseBody
public String pojoParam(User user){System.out.println("pojo参数传递 user ==> "+user);return "{'module':'pojo param'}";
}注意:
请求参数key的名称要和POJO中属性的名称一致,否则无法封装。
数组类型参数
举个简单的例子,如果前端需要获取用户的爱好,爱好绝大多数情况下都是多个,如何发送请求数据和接收数据呢?
数组参数:请求参数名与形参对象属性名相同且请求参数为多个,定义数组类型即可接收参数,发送请求和参数的示例代码如下:
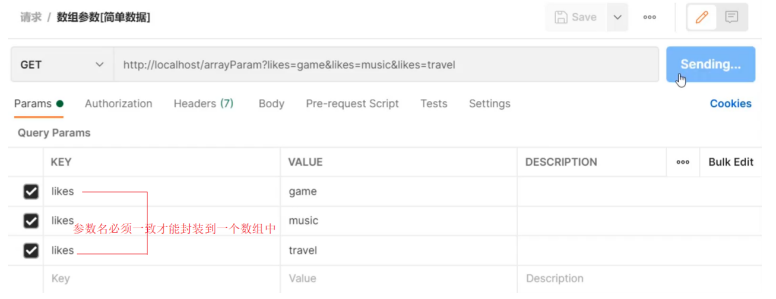
后台接收参数:
//数组参数:同名请求参数可以直接映射到对应名称的形参数组对象中@RequestMapping("/arrayParam")@ResponseBodypublic String arrayParam(String[] likes) {System.out.println("数组参数传递 likes ==> " + Arrays.toString(likes));return "{'module':'array param'}";
}集合类型参数
数组能接收多个值,那么集合是否也可以实现这个功能呢? 发送请求和参数:
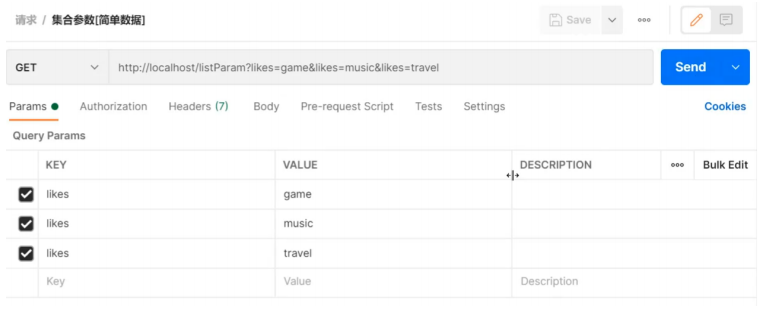
后台接收参数
//集合参数:同名请求参数可以使用@RequestParam注解映射到对应名称的集合对象中作为数据
@RequestMapping("/listParam")
@ResponseBody
public String listParam(List < String > likes) {System.out.println("集合参数传递 likes ==> " + likes);return "{'module':'list param'}";
}运行会报错,
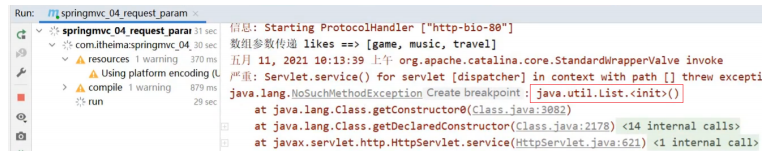
错误的原因是:SpringMVC将List看做是一个POJO对象来处理,将其创建一个对象并准备把前端的数 据封装到对象中,但是List是一个接口无法创建对象,所以报错。 解决方案是:使用@RequestParam注解
//集合参数:同名请求参数可以使用@RequestParam注解映射到对应名称的集合对象中作为数据
@RequestMapping("/listParam")
@ResponseBody
public String listParam(@RequestParam List < String > likes) {System.out.println("集合参数传递 likes ==> " + likes);return "{'module':'list param'}";
}集合保存普通参数:请求参数名与形参集合对象名相同且请求参数为多个,@RequestParam绑定参数关系。对于简单数据类型使用数组会比集合更简单些。