建设网站的分析网站制作与管理技术标准实训教程
介绍 | uni-app官网
vue、uniapp中动态添加绑定style、class 9种方法实现_vue style动态绑定-CSDN博客
uniapp使用三元运算符动态绑定元素的style样式_uniapp style动态绑定-CSDN博客
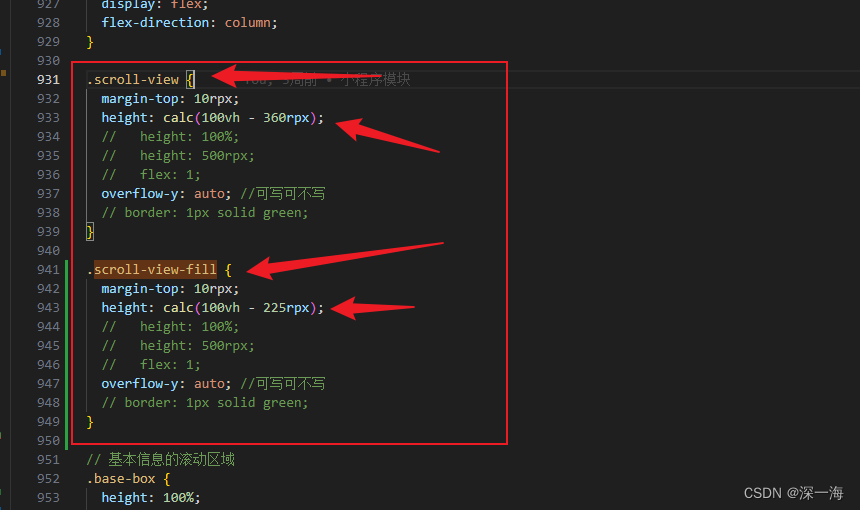
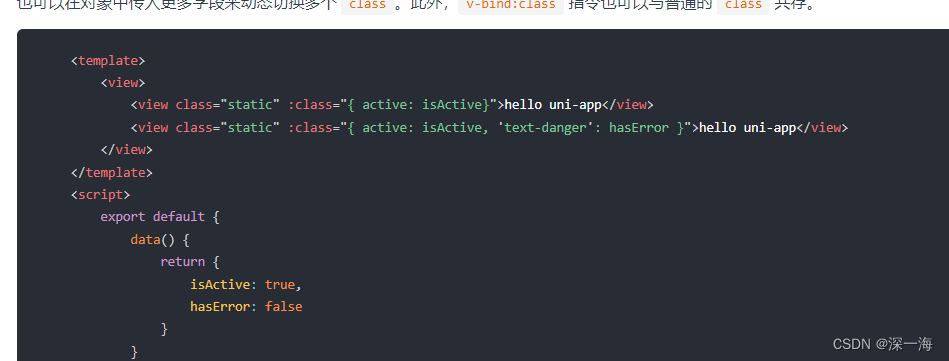
对象写法,可以写多个class类
class类的名字:判断条件,最后结果只有真和假
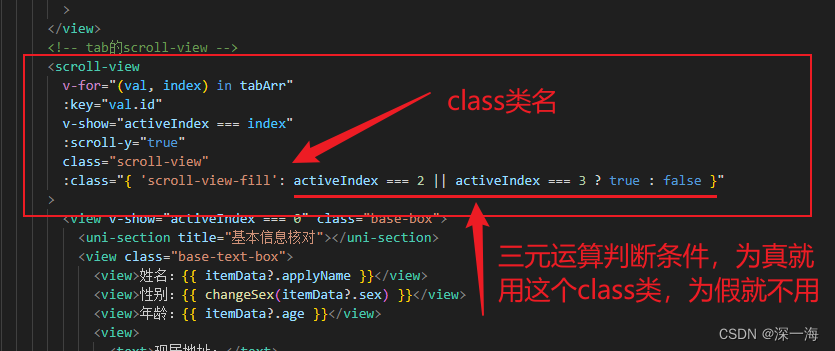
:class="{ 'scroll-view-fill': activeIndex === 2 || activeIndex === 3 ? true : false }"字符串写法,只能写一个class类
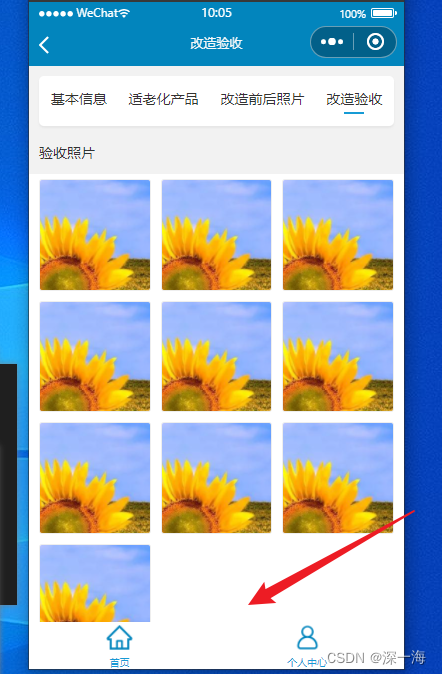
:class="'scroll-view-fill': activeIndex === 2 ? true : false"有的tab页面有灰色块,有的页面没有灰色块。根据选择的tab不同,页面会出现灰色块,想通过判断点击的是哪个tab,来改变页面的scroll-view这个class类的样式,从而把这个灰色的块去掉
写了2个class类,点击基本信息页面时,scroll-view样式起作用,点改造验收页面时,scroll-view-fill样式起作用

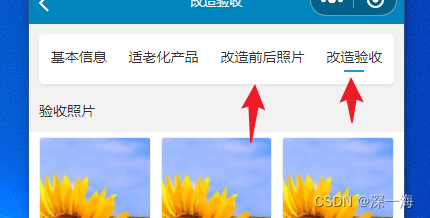

点击改造验收,没有灰色块了