dw做的网站怎么被别人打开阀门网站建设
前言
我们在使用Windows系统的时候经常会遇到一些程序不会释放已分配的内存,从而导致电脑变得缓慢。今天给大家推荐一款.NET开源的小巧、智能、免费的Windows内存清理工具:WinMemoryCleaner。
使用Windows内存清理工具来优化内存,这样不必浪费时间去重新启动电脑。
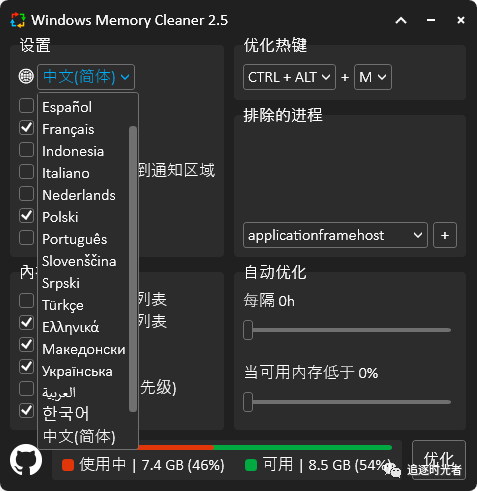
工具主要特点
-
自动优化
-
每隔X小时 - 优化将按照设定的时间间隔运行
-
当空闲内存低于X百分比时 - 如果空闲内存低于指定百分比,优化将会运行
-
-
紧凑模式
-
最小化按钮旁边的箭头(上/下)用于折叠和展开窗口
-
-
内存区域
-
清理组合页列表 - 仅在启用页面组合时有效地刷新组合页列表中的块
-
清理修改后的页列表 - 刷新来自修改后的页列表的内存,将未保存的数据写入磁盘并将页面移动到待机列表
-
清理进程工作集 - 从所有用户模式和系统工作集中删除内存,并将其移动到待机或已修改的页列表。请注意,到进程运行时,任何代码都必然会填充它们的工作集以便运行
-
清理待机列表 - 从所有待机列表中刷新页面到空闲列表
-
清理待机列表(低优先级) - 从最低优先级的待机列表中刷新页面到空闲列表
-
清理系统工作集 - 从系统缓存工作集中删除内存
-
-
排除优化的进程
-
您可以建立一个在优化内存时忽略的进程列表
-
-
优化热键(全局)
-
CTRL + ALT + M(可定制) - 优化
-
工具设置
-
始终置顶 - 将窗口固定在所有窗口的顶部
-
自动更新 - 保持应用程序处于最新状态
-
优化后关闭 - 在优化后关闭应用程序
-
关闭到通知区域 - 点击关闭(X)按钮时将应用程序最小化到系统托盘
-
开机自启 - 系统启动后运行应用程序
-
显示优化通知 - 在优化后向通知区域发送消息
-
启动时最小化 - 应用程序将以最小化状态启动到系统托盘。单击/双击图标可恢复显示
支持语言
阿拉伯语、中文、荷兰语、英语、法语、德语、希腊语、印尼语、意大利语、日语、韩语、马其顿语、波兰语、葡萄牙语、塞尔维亚语、斯洛文尼亚语、西班牙语、土耳其语、乌克兰语。
项目源码

项目下载
-
下载地址:https://github.com/IgorMundstein/WinMemoryCleaner/releases/download/2.5/WinMemoryCleaner.exe
工具使用

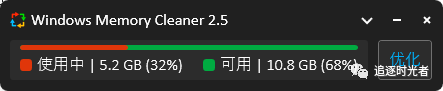
点击优化后的内存情况(直接少了2.9G)

项目源码地址
更多项目实用功能和特性欢迎前往项目开源地址查看👀,别忘了给项目一个Star支持💖。
https://github.com/IgorMundstein/WinMemoryCleaner
优秀项目和框架精选
该项目已收录到C#/.NET/.NET Core优秀项目和框架精选中,关注优秀项目和框架精选能让你及时了解C#、.NET和.NET Core领域的最新动态和最佳实践,提高开发工作效率和质量。坑已挖,欢迎大家踊跃提交PR推荐或自荐(让优秀的项目和框架不被埋没🤞)。
https://github.com/YSGStudyHards/DotNetGuide/blob/main/docs/DotNet/DotNetProjectPicks.md