李沧区城市建设管理局网站随便吧在线图片制作
手机端查看

docker 容器,镜像操作命令
1、docker删除所有镜像命令
删除所有镜像的命令是Docker中一个非常常见的操作。下面是具体的实现步骤和命令示例:
$ docker stop $(docker ps -aq) 停止所有正在运行的容器。
$ docker rm $(docker ps -aq) 删除所有容器。
$ docker rmi $(docker images -aq) 删除所有镜像。
这里的 docker ps -aq 和 docker images -aq 是一系列用于查找和选择容器和镜像的 Docker 命令。
2. docker删除镜像文件
如果使用 docker rmi 命令时突然出现“permission denied” 的提示,这应该就是因为 Docker 的镜像文件很可能在使用中。这时候,为了彻底删除这些文件,我们可以采取以下步骤:
$ docker ps -a
$ docker stop containerID (或 containerNAME)
$ docker rm containerID (或 containerNAME)
$ docker rmi imageName
3. docker删除镜像
有些时候,你可能需要单独删除某几个镜像,或者特定名称、标签或ID的所有镜像。以下是实现的具体命令:
1. 根据名称来删除某个镜像。
$ docker rmi imageName2. 根据标签来删除某些镜像。
$ docker rmi imageName:tag3. 根据 ID 来删除某个镜像。
$ docker rmi imageID
4. docker删除镜像后如何还原
如果误删了某些关键镜像,想要将其还原,则可以使用以下命令在 Docker 中重新安装您需要的镜像:
$ docker pull imageName
如果该镜像包含某些特定的标签,则可以通过添加该标签名称来重新安装该镜像:
$ docker pull imageName:tag
小小细节:区分StringUtils.isNotBlank(),StringUtils.isBlank(),StringUtils.isEmpty(),StringUtils.isNotEmpty()
判断str字符串都不为空,==>StringUtils.isNotBlank(String str);对于制表符、换行符、换页符和回车符StringUtils.isBlank()均识为空白符,* StringUtils.isNotBlank(null) = false* StringUtils.isNotBlank("") = false* StringUtils.isNotBlank(" ") = false* StringUtils.isNotBlank("bob") = true* StringUtils.isNotBlank(" bob ") = true*
判断字符串是否只等于null或空("")==>StringUtils.isEmpty(String str);判断为空都返回true ==> StringUtils.isBlank(String str);检查如果一个字符串是否全为空格,空("")或null只有null和空("")会返回false ==>StringUtils.isNotEmpty(String str)检查一个字符串不为空("")与不为null
一般用isNotBlank()这个非空判读比较多点,因为这个较为完整,各种意义上的空都屏蔽掉了
微服务的一般结构
①:接口定义@RestController@RequestMapping("/api/v1/login")public class ApUserLoginController {@PostMapping("/login_auth")public ResponseResult login(@RequestBody LoginDto dto) {return null;}}②:持久层mapperpackage com.heima.user.mapper;import com.baomidou.mybatisplus.core.mapper.BaseMapper;import com.heima.model.user.pojos.ApUser;import org.apache.ibatis.annotations.Mapper;@Mapperpublic interface ApUserMapper extends BaseMapper<ApUser> {}③:业务层servicepackage com.heima.user.service;import com.baomidou.mybatisplus.extension.service.IService;import com.heima.model.common.dtos.ResponseResult;import com.heima.model.user.dtos.LoginDto;import com.heima.model.user.pojos.ApUser;public interface ApUserService extends IService<ApUser>{/*** app端登录* @param dto* @return*/public ResponseResult login(LoginDto dto);}④:实现类package com.heima.user.service.impl;import com.baomidou.mybatisplus.core.toolkit.Wrappers;import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl;import com.heima.model.common.dtos.ResponseResult;import com.heima.model.common.enums.AppHttpCodeEnum;import com.heima.model.user.dtos.LoginDto;import com.heima.model.user.pojos.ApUser;import com.heima.user.mapper.ApUserMapper;import com.heima.user.service.ApUserService;import com.heima.utils.common.AppJwtUtil;import org.apache.commons.lang3.StringUtils;import org.springframework.stereotype.Service;import org.springframework.util.DigestUtils;import java.util.HashMap;import java.util.Map;@Servicepublic class ApUserServiceImpl extends ServiceImpl<ApUserMapper, ApUser> implements ApUserService {@Overridepublic ResponseResult login(LoginDto dto) {return null;}}一. nacos
- 1. docker下载安装
nacos安装①:docker拉取镜像 docker pull nacos/nacos-server:1.2.0②:创建容器docker run --env MODE=standalone --name nacos --restart=always -d -p 8848:8848 nacos/nacos-server:1.2.0- MODE=standalone 单机版
- --restart=always 开机启动
- -p 8848:8848 映射端口
- -d 创建一个守护式容器在后台运行③:访问地址:http://192.168.200.130:8848/nacos - 2. 微服务导入nacos注册,服务发现和配置管理
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency>
- 3. 引导上加注解@EnableDiscoveryClient开启服务注册
@SpringBootApplication
@EnableDiscoveryClient
@MapperScan("com.heima.user.mapper")
public class UserApplication {public static void main(String[] args) {SpringApplication.run(UserApplication.class,args);}
}
- 4. 在nacos配置中心撰写配置文件
注意:mysql版本在8.0以及之上的需要注意driver-class-name: com.mysql.cj.jdbc.Driverpassword需要根据需求进行变化url也需要根据需求变化,当用的非本地的mysql时需要更改localhost为虚拟机地址
spring:datasource:driver-class-name: com.mysql.jdbc.Driverurl: jdbc:mysql://localhost:3306/leadnews_user?useUnicode=true&characterEncoding=UTF-8&serverTimezone=UTCusername: rootpassword: root
# 设置Mapper接口所对应的XML文件位置,如果你在Mapper接口中有自定义方法,需要进行该配置
mybatis-plus:mapper-locations: classpath*:mapper/*.xml# 设置别名包扫描路径,通过该属性可以给包中的类注册别名type-aliases-package: com.heima.model.user.pojos
- 5. bootstrap.yml进行配置
基本上每个微服务都需要在bootstrap.yml中引入这个
server:port: 51801
spring:application:name: leadnews-usercloud:nacos:discovery: //nacos服务注册server-addr: 192.168.200.130:8848config: //nacos配置的发现server-addr: 192.168.200.130:8848file-extension: yml
- 6. logback.xml配置
<!--定义日志文件的存储地址,使用绝对路径--> <property name="LOG_HOME" value="e:/logs"/>这个可以根据需要自己更改
<?xml version="1.0" encoding="UTF-8"?><configuration><!--定义日志文件的存储地址,使用绝对路径--><property name="LOG_HOME" value="e:/logs"/><!-- Console 输出设置 --><appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender"><encoder><!--格式化输出:%d表示日期,%thread表示线程名,%-5level:级别从左显示5个字符宽度%msg:日志消息,%n是换行符--><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern><charset>utf8</charset></encoder></appender><!-- 按照每天生成日志文件 --><appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender"><rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy"><!--日志文件输出的文件名--><fileNamePattern>${LOG_HOME}/leadnews.%d{yyyy-MM-dd}.log</fileNamePattern></rollingPolicy><encoder><pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n</pattern></encoder></appender><!-- 异步输出 --><appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender"><!-- 不丢失日志.默认的,如果队列的80%已满,则会丢弃TRACT、DEBUG、INFO级别的日志 --><discardingThreshold>0</discardingThreshold><!-- 更改默认的队列的深度,该值会影响性能.默认值为256 --><queueSize>512</queueSize><!-- 添加附加的appender,最多只能添加一个 --><appender-ref ref="FILE"/></appender><logger name="org.apache.ibatis.cache.decorators.LoggingCache" level="DEBUG" additivity="false"><appender-ref ref="CONSOLE"/></logger><logger name="org.springframework.boot" level="debug"/><root level="info"><!--<appender-ref ref="ASYNC"/>--><appender-ref ref="FILE"/><appender-ref ref="CONSOLE"/></root>
</configuration>
二. Swagger和knife4j
像Swagger和knife4j这种每个微服务都需要的就写在common模块中,直接让所有微服务的父亲去引用即可
<dependency><groupId>com.heima</groupId><artifactId>heima-leadnews-common</artifactId></dependency>
1 swagger
(1) SpringBoot集成Swagger
- 引入依赖,在heima-leadnews-model和heima-leadnews-common模块中引入该依赖
<dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger2</artifactId>
</dependency>
<dependency><groupId>io.springfox</groupId><artifactId>springfox-swagger-ui</artifactId>
</dependency>
只需要在heima-leadnews-common中进行配置即可,因为其他微服务工程都直接或间接依赖即可。
- 在heima-leadnews-common工程中添加一个配置类
新增:com.heima.common.swagger.SwaggerConfiguration
@Configuration
@EnableSwagger2
public class SwaggerConfiguration {@Beanpublic Docket buildDocket() {return new Docket(DocumentationType.SWAGGER_2).apiInfo(buildApiInfo()).select()// 要扫描的API(Controller)基础包.apis(RequestHandlerSelectors.basePackage("com.heima")).paths(PathSelectors.any()).build();}private ApiInfo buildApiInfo() {Contact contact = new Contact("黑马程序员","","");return new ApiInfoBuilder().title("黑马头条-平台管理API文档").description("黑马头条后台api").contact(contact).version("1.0.0").build();}
}
- 在heima-leadnews-common模块中的resources目录中新增以下目录和文件
文件:resources/META-INF/Spring.factories
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.heima.common.swagger.SwaggerConfiguration
(2)Swagger常用注解
在Java类中添加Swagger的注解即可生成Swagger接口文档,常用Swagger注解如下:
@Api:修饰整个类,描述Controller的作用
@ApiOperation:描述一个类的一个方法,或者说一个接口
@ApiParam:单个参数的描述信息
@ApiModel:用对象来接收参数
@ApiModelProperty:用对象接收参数时,描述对象的一个字段
@ApiResponse:HTTP响应其中1个描述
@ApiResponses:HTTP响应整体描述
@ApiIgnore:使用该注解忽略这个API
@ApiError :发生错误返回的信息
@ApiImplicitParam:一个请求参数
@ApiImplicitParams:多个请求参数的描述信息
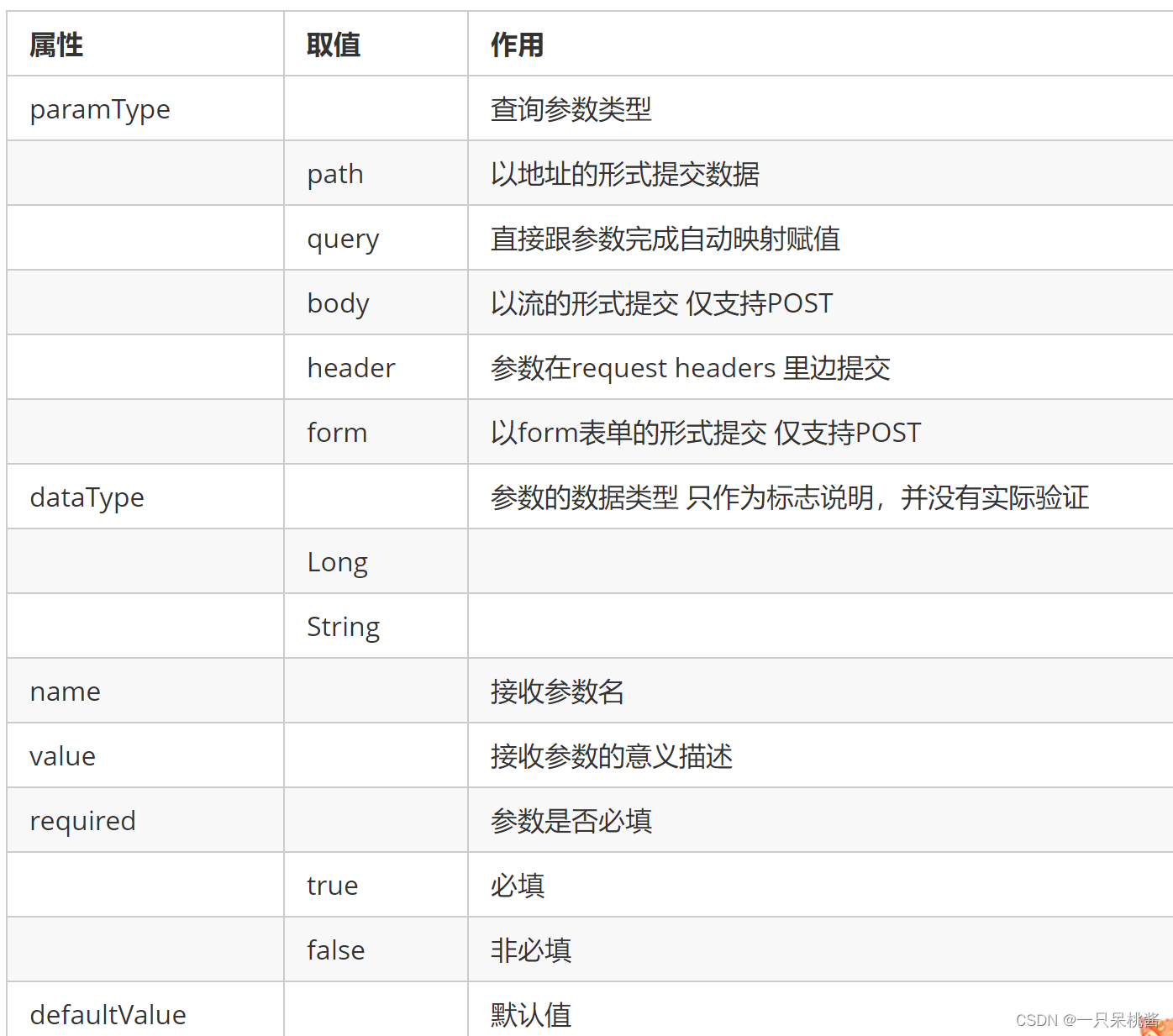
@ApiImplicitParam属性:
我们在ApUserLoginController中添加Swagger注解,代码如下所示:
@RestController@RequestMapping("/api/v1/login")@Api(value = "app端用户登录", tags = "ap_user", description = "app端用户登录API")public class ApUserLoginController {@Autowiredprivate ApUserService apUserService;@PostMapping("/login_auth")@ApiOperation("用户登录")public ResponseResult login(@RequestBody LoginDto dto){return apUserService.login(dto);}}
LoginDto
@Data
public class LoginDto {/*** 手机号*/@ApiModelProperty(value = "手机号",required = true)private String phone;/*** 密码*/@ApiModelProperty(value = "密码",required = true)private String password;
}
启动user微服务,访问地址:http://localhost:51801/swagger-ui.html
2 knife4j
(1)简介
knife4j是为Java MVC框架集成Swagger生成Api文档的增强解决方案,前身是swagger-bootstrap-ui,取名kni4j是希望它能像一把匕首一样小巧,轻量,并且功能强悍!
(2)核心功能
该UI增强包主要包括两大核心功能:文档说明 和 在线调试
- 文档说明:根据Swagger的规范说明,详细列出接口文档的说明,包括接口地址、类型、请求示例、请求参数、响应示例、响应参数、响应码等信息,使用swagger-bootstrap-ui能根据该文档说明,对该接口的使用情况一目了然。
- 在线调试:提供在线接口联调的强大功能,自动解析当前接口参数,同时包含表单验证,调用参数可返回接口响应内容、headers、Curl请求命令实例、响应时间、响应状态码等信息,帮助开发者在线调试,而不必通过其他测试工具测试接口是否正确,简介、强大。
- 个性化配置:通过个性化ui配置项,可自定义UI的相关显示信息
- 离线文档:根据标准规范,生成的在线markdown离线文档,开发者可以进行拷贝生成markdown接口文档,通过其他第三方markdown转换工具转换成html或pdf,这样也可以放弃swagger2markdown组件
- 接口排序:自1.8.5后,ui支持了接口排序功能,例如一个注册功能主要包含了多个步骤,可以根据swagger-bootstrap-ui提供的接口排序规则实现接口的排序,step化接口操作,方便其他开发者进行接口对接
(3)快速集成
- 在heima-leadnews-common模块中的pom.xml文件中引入knife4j的依赖,如下:
<dependency><groupId>com.github.xiaoymin</groupId><artifactId>knife4j-spring-boot-starter</artifactId>
</dependency>
- 创建Swagger配置文件
在heima-leadnews-common模块中新建配置类
新建Swagger的配置文件SwaggerConfiguration.java文件,创建springfox提供的Docket分组对象,代码如下:
@Configuration
@EnableSwagger2
@EnableKnife4j
@Import(BeanValidatorPluginsConfiguration.class)
public class Swagger2Configuration {@Bean(value = "defaultApi2")public Docket defaultApi2() {Docket docket=new Docket(DocumentationType.SWAGGER_2).apiInfo(apiInfo())//分组名称.groupName("1.0").select()//这里指定Controller扫描包路径.apis(RequestHandlerSelectors.basePackage("com.heima")).paths(PathSelectors.any()).build();return docket;}private ApiInfo apiInfo() {return new ApiInfoBuilder().title("黑马头条API文档").description("黑马头条API文档").version("1.0").build();}
}
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.heima.common.swagger.Swagger2Configuration
(4) 以上有两个注解需要特别说明,如下表:
| 注解 | 说明 |
|---|---|
| @EnableSwagger2 | 该注解是Springfox-swagger框架提供的使用Swagger注解,该注解必须加 |
| @EnableKnife4j | 该注解是knife4j提供的增强注解,Ui提供了例如动态参数、参数过滤、接口排序等增强功能,如果你想使用这些增强功能就必须加该注解,否则可以不用加 |
- 添加配置
在Spring.factories中新增配置
org.springframework.boot.autoconfigure.EnableAutoConfiguration=\com.heima.common.swagger.Swagger2Configuration, \com.heima.common.swagger.SwaggerConfiguration
- 访问
在浏览器输入地址:http://host:port/doc.html
三. gateway
详细的gateway学习链接
网关gateway也是一个微服务
(1)在heima-leadnews-gateway导入以下依赖
pom文件
<dependencies><dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-starter-gateway</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId></dependency><dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId></dependency><dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId></dependency>
</dependencies>
其中jjwt是用于进行实现JWT(Json Web Token)是实现token技术的一种解决方案,用于前端和服务端进行身份认证,本文只是基于如何快速创建秘钥和解析秘钥,至于后端使用过滤器校验逻辑,可自行补充。
<dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId></dependency>
(2)在heima-leadnews-gateway下创建heima-leadnews-app-gateway微服务
引导类:
package com.heima.app.gateway;import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.client.discovery.EnableDiscoveryClient;@SpringBootApplication
@EnableDiscoveryClient //开启注册中心
public class AppGatewayApplication {public static void main(String[] args) {SpringApplication.run(AppGatewayApplication.class,args);}
}
bootstrap.yml
server:port: 51601
spring:application:name: leadnews-app-gatewaycloud:nacos:discovery:server-addr: 192.168.200.130:8848config:server-addr: 192.168.200.130:8848file-extension: yml
在nacos的配置中心创建dataid为leadnews-app-gateway的yml配置
spring:cloud:gateway:globalcors:add-to-simple-url-handler-mapping: truecorsConfigurations:'[/**]':allowedHeaders: "*"allowedOrigins: "*"allowedMethods:- GET- POST- DELETE- PUT- OPTIONroutes:# 平台管理- id: useruri: lb://leadnews-userpredicates:- Path=/user/**filters:- StripPrefix= 1
1. 配置全局过滤器
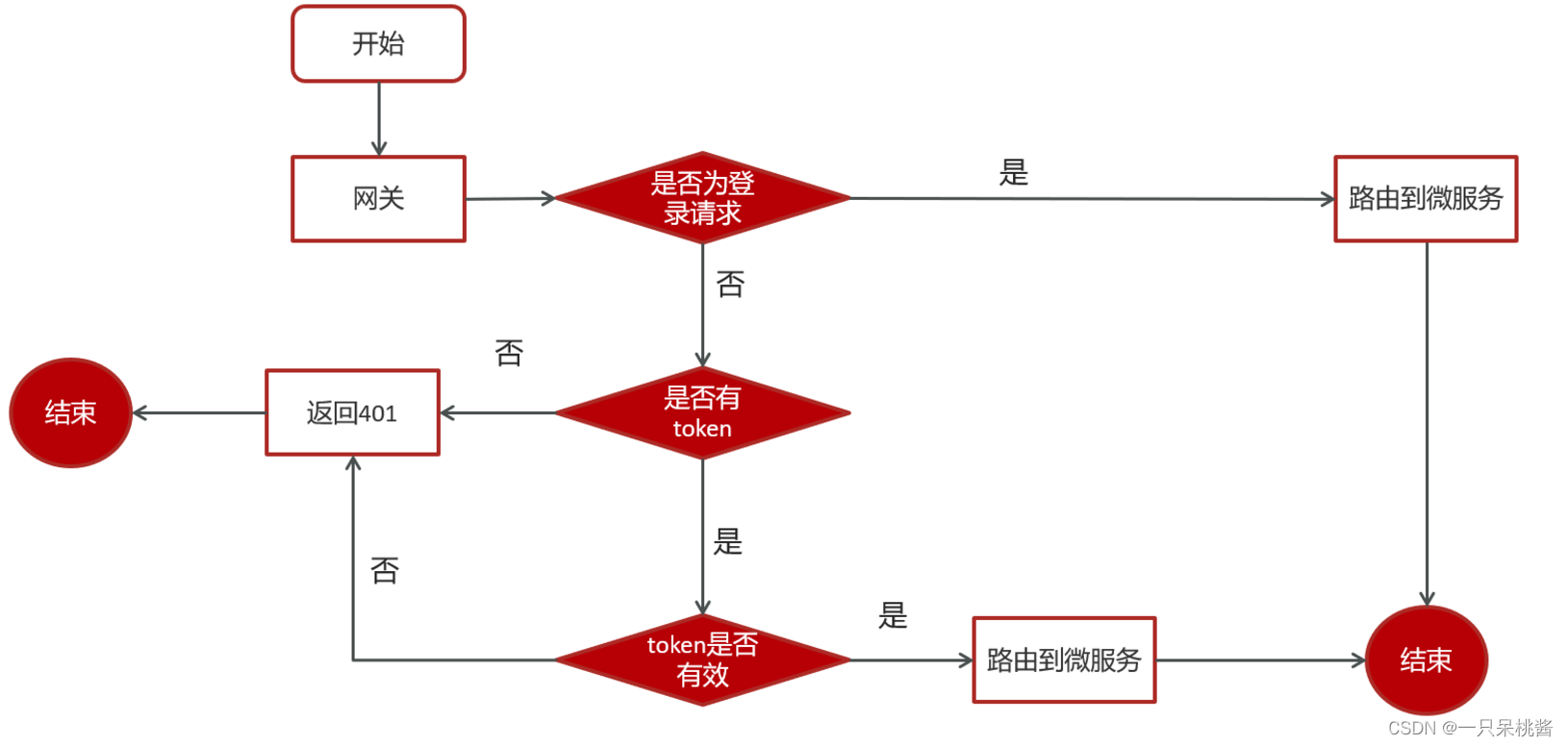
@Component
@Slf4j
public class AuthorizeFilter implements Ordered, GlobalFilter {@Overridepublic Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {//1.获取request和response对象ServerHttpRequest request = exchange.getRequest();ServerHttpResponse response = exchange.getResponse();//2.判断是否是登录if(request.getURI().getPath().contains("/login")){//放行return chain.filter(exchange);}//3.获取tokenString token = request.getHeaders().getFirst("token");//4.判断token是否存在if(StringUtils.isBlank(token)){response.setStatusCode(HttpStatus.UNAUTHORIZED);return response.setComplete();}//5.判断token是否有效try {Claims claimsBody = AppJwtUtil.getClaimsBody(token);//是否是过期int result = AppJwtUtil.verifyToken(claimsBody);if(result == 1 || result == 2){response.setStatusCode(HttpStatus.UNAUTHORIZED);return response.setComplete();}}catch (Exception e){e.printStackTrace();response.setStatusCode(HttpStatus.UNAUTHORIZED);return response.setComplete();}//6.放行return chain.filter(exchange);}/*** 优先级设置 值越小 优先级越高* @return*/@Overridepublic int getOrder() {return 0;}
}
2. JWT鉴权
- 首先在gateway中导入以下依赖
<dependency><groupId>io.jsonwebtoken</groupId><artifactId>jjwt</artifactId></dependency>
其中jjwt是用于进行实现JWT(Json Web Token)是实现token技术的一种解决方案,用于前端和服务端进行身份认证,本文只是基于如何快速创建秘钥和解析秘钥,至于后端使用过滤器校验逻辑,可自行补充。
- 然后写JWT鉴权的方法
public class AppJwtUtil {// TOKEN的有效期一天(S)private static final int TOKEN_TIME_OUT = 3_600;// 加密KEYprivate static final String TOKEN_ENCRY_KEY = "MDk4ZjZiY2Q0NjIxZDM3M2NhZGU0ZTgzMjYyN2I0ZjY";// 最小刷新间隔(S)private static final int REFRESH_TIME = 300;// 生产IDpublic static String getToken(Long id){Map<String, Object> claimMaps = new HashMap<>();claimMaps.put("id",id);long currentTime = System.currentTimeMillis();return Jwts.builder().setId(UUID.randomUUID().toString()).setIssuedAt(new Date(currentTime)) //签发时间.setSubject("system") //说明.setIssuer("heima") //签发者信息.setAudience("app") //接收用户.compressWith(CompressionCodecs.GZIP) //数据压缩方式.signWith(SignatureAlgorithm.HS512, generalKey()) //加密方式.setExpiration(new Date(currentTime + TOKEN_TIME_OUT * 1000)) //过期时间戳.addClaims(claimMaps) //cla信息.compact();}/*** 获取token中的claims信息** @param token* @return*/private static Jws<Claims> getJws(String token) {return Jwts.parser().setSigningKey(generalKey()).parseClaimsJws(token);}/*** 获取payload body信息** @param token* @return*/public static Claims getClaimsBody(String token) {try {return getJws(token).getBody();}catch (ExpiredJwtException e){return null;}}/*** 获取hearder body信息** @param token* @return*/public static JwsHeader getHeaderBody(String token) {return getJws(token).getHeader();}/*** 是否过期** @param claims* @return -1:有效,0:有效,1:过期,2:过期*/public static int verifyToken(Claims claims) {if(claims==null){return 1;}try {claims.getExpiration().before(new Date());// 需要自动刷新TOKENif((claims.getExpiration().getTime()-System.currentTimeMillis())>REFRESH_TIME*1000){return -1;}else {return 0;}} catch (ExpiredJwtException ex) {return 1;}catch (Exception e){return 2;}}/*** 由字符串生成加密key** @return*/public static SecretKey generalKey() {byte[] encodedKey = Base64.getEncoder().encode(TOKEN_ENCRY_KEY.getBytes());SecretKey key = new SecretKeySpec(encodedKey, 0, encodedKey.length, "AES");return key;}public static void main(String[] args) {/* Map map = new HashMap();map.put("id","11");*/System.out.println(AppJwtUtil.getToken(1102L));Jws<Claims> jws = AppJwtUtil.getJws("eyJhbGciOiJIUzUxMiIsInppcCI6IkdaSVAifQ.H4sIAAAAAAAAADWLQQqEMAwA_5KzhURNt_qb1KZYQSi0wi6Lf9942NsMw3zh6AVW2DYmDGl2WabkZgreCaM6VXzhFBfJMcMARTqsxIG9Z888QLui3e3Tup5Pb81013KKmVzJTGo11nf9n8v4nMUaEY73DzTabjmDAAAA.4SuqQ42IGqCgBai6qd4RaVpVxTlZIWC826QA9kLvt9d-yVUw82gU47HDaSfOzgAcloZedYNNpUcd18Ne8vvjQA");Claims claims = jws.getBody();System.out.println(claims.get("id"));}
}