网站建设知识点深圳 网站 传播
CAN 简介
CAN 是 Controller Area Network 的缩写(以下称为 CAN),是 ISO 国际标准化的串行通信 协议。在当前的汽车产业中,出于对安全性、舒适性、方便性、低公害、低成本的要求,各种 各样的电子控制系统被开发了出来。由于这些系统之间通信所用的数据类型及对可靠性的要求 不尽相同,由多条总线构成的情况很多,线束的数量也随之增加。为适应“减少线束的数量”、 “通过多个 LAN,进行大量数据的高速通信”的需要,1986 年德国电气商博世公司开发出面向 汽车的 CAN 通信协议。此后,CAN 通过 ISO11898 及 ISO11519 进行了标准化,现在在欧洲已 是汽车网络的标准协议。
现在,CAN 的高性能和可靠性已被认同,并被广泛地应用于工业自动化、船舶、医疗设备、 工业设备等方面。现场总线是当今自动化领域技术发展的热点之一,被誉为自动化领域的计算 机局域网。它的出现为分布式控制系统实现各节点之间实时、可靠的数据通信提供了强有力的 技术支持。
CAN 协议具有一下特点:
1) 多主控制。在总线空闲时,所有单元都可以发送消息(多主控制),而两个以上的单 元同时开始发送消息时,根据标识符(Identifier以下称为ID)决定优先级。ID并不是表示 发送的目的地址,而是表示访问总线的消息的优先级。两个以上的单元同时开始发送消息 时,对各消息ID的每个位进行逐个仲裁比较。仲裁获胜(被判定为优先级最高)的单元 可继续发送消息,仲裁失利的单元则立刻停止发送而进行接收工作。
2) 系统的柔软性。与总线相连的单元没有类似于“地址”的信息。因此在总线上增加单元 时,连接在总线上的其它单元的软硬件及应用层都不需要改变。
3) 通信速度较快,通信距离远。最高1Mbps(距离小于40M),最远可达10KM(速率低 于5Kbps)。
4) 具有错误检测、错误通知和错误恢复功能。所有单元都可以检测错误(错误检测功 能),检测出错误的单元会立即同时通知其他所有单元(错误通知功能),正在发送消息的 单元一旦检测出错误,会强制结束当前的发送。强制结束发送的单元会不断反复地重新发 送此消息直到成功发送为止(错误恢复功能)。
5) 故障封闭功能。CAN可以判断出错误的类型是总线上暂时的数据错误(如外部噪声 等)还是持续的数据错误(如单元内部故障、驱动器故障、断线等)。由此功能,当总线 上发生持续数据错误时,可将引起此故障的单元从总线上隔离出去。
6) 连接节点多。CAN总线是可同时连接多个单元的总线。可连接的单元总数理论上是 没有限制的。但实际上可连接的单元数受总线上的时间延迟及电气负载的限制。降低通信 速度,可连接的单元数增加;提高通信速度,则可连接的单元数减少。
正是因为 CAN 协议的这些特点,使得 CAN 特别适合工业过程监控设备的互连,因此,越 来越受到工业界的重视,并已公认为最有前途的现场总线之一。
CAN 协议经过 ISO 标准化后有两个标准:ISO11898 标准(高速 CAN)和 ISO11519-2 标准 (低速CAN)。其中 ISO11898 是针对通信速率为125Kbps~1Mbps 的高速通信标准,而 ISO11519- 2 是针对通信速率为 125Kbps 以下的低速通信标准。
CAN物理层
本章,我们使用的是 ISO11898 标准,也就是高速 CAN,其拓扑图如图 37.1.1.1 所示。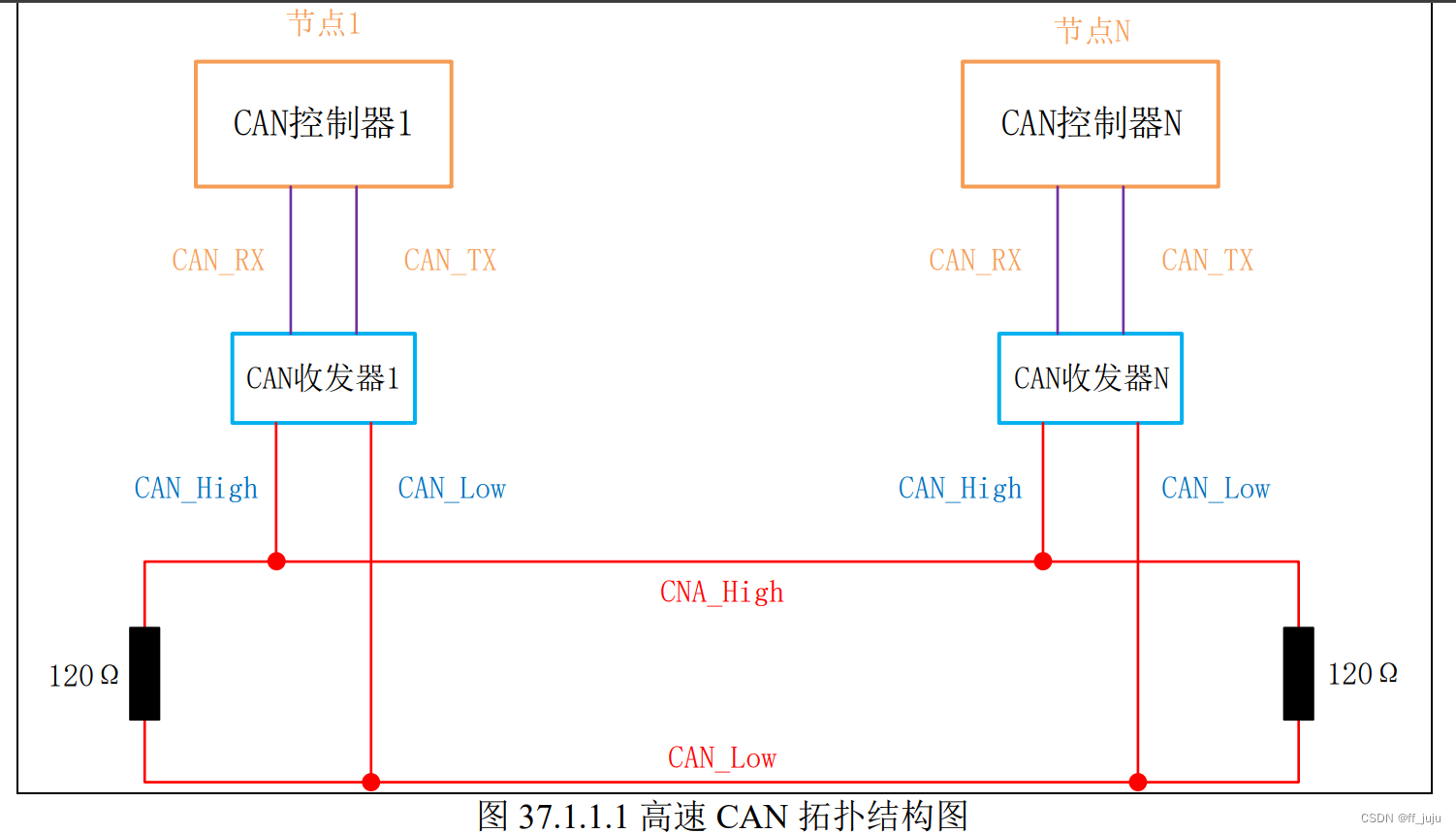 从上图可知,高速 CAN 总线呈现的是一个闭环结构,总线是由两根线 CAN_High 和 CAN_Low 组成,且在总线两端各串联了 120Ω的电阻(用于阻抗匹配,减少回波反射),同时 总线上可以挂载多个节点。每个节点都有 CAN 收发器以及 CAN 控制器,CAN 控制器通常是 MCU 的外设,集成在芯片内部;CAN 收发器则是需要外加芯片转换电路。
从上图可知,高速 CAN 总线呈现的是一个闭环结构,总线是由两根线 CAN_High 和 CAN_Low 组成,且在总线两端各串联了 120Ω的电阻(用于阻抗匹配,减少回波反射),同时 总线上可以挂载多个节点。每个节点都有 CAN 收发器以及 CAN 控制器,CAN 控制器通常是 MCU 的外设,集成在芯片内部;CAN 收发器则是需要外加芯片转换电路。
CAN 类似 RS485 也是通过差分信号传输数据。根据 CAN 总线上两根线的电位差来判断总 线电平。总线电平分为显性电平和隐性电平,二者必居其一。这是属于物理层特征,ISO11898 物理层特性如图 37.1.1.2 所示: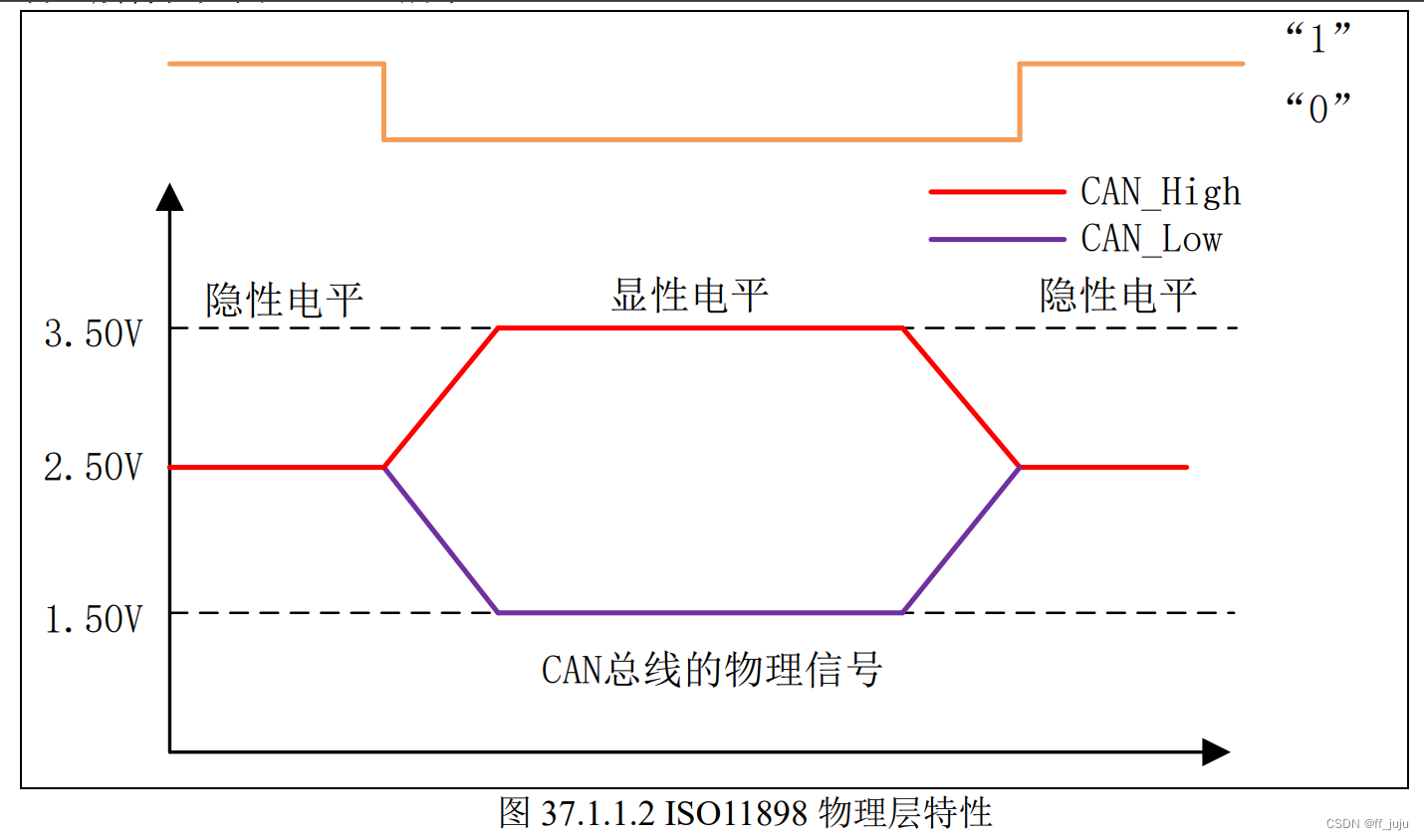 从该特性可以看出,显性电平对应逻辑 0,CAN_H 和 CAN_L 之差为 2V 左右。而隐性电 平对应逻辑 1,CAN_H 和 CAN_L 之差为 0V。在总线上显性电平具有优先权,只要有一个单元 输出显性电平,总线上即为显性电平。而隐形电平则具有包容的意味,只有所有的单元都输出 隐性电平,总线上才为隐性电平(显性电平比隐性电平更强)
从该特性可以看出,显性电平对应逻辑 0,CAN_H 和 CAN_L 之差为 2V 左右。而隐性电 平对应逻辑 1,CAN_H 和 CAN_L 之差为 0V。在总线上显性电平具有优先权,只要有一个单元 输出显性电平,总线上即为显性电平。而隐形电平则具有包容的意味,只有所有的单元都输出 隐性电平,总线上才为隐性电平(显性电平比隐性电平更强)
CAN 协议层
CAN 协议是通过以下 5 种类型的帧进行的:
另外,数据帧和遥控帧有标准格式和扩展格式两种格式。标准格式有 11 个位的标识符(ID), 扩展格式有 29 个位的 ID。各种帧的用途如表 37.1.2.1 所示: 由于篇幅所限,我们这里仅对数据帧进行详细介绍,数据帧一般由 7 个段构成,即:
由于篇幅所限,我们这里仅对数据帧进行详细介绍,数据帧一般由 7 个段构成,即:
帧起始。表示数据帧开始的段。
仲裁段。表示该帧优先级的段。
控制段。表示数据的字节数及保留位的段。
数据段。数据的内容,一帧可发送 0~8 个字节的数据。
CRC 段。检查帧的传输错误的段。
ACK 段。表示确认正常接收的段。
帧结束。表示数据帧结束的段。
数据帧的构成如图 37.1.2.1 所示: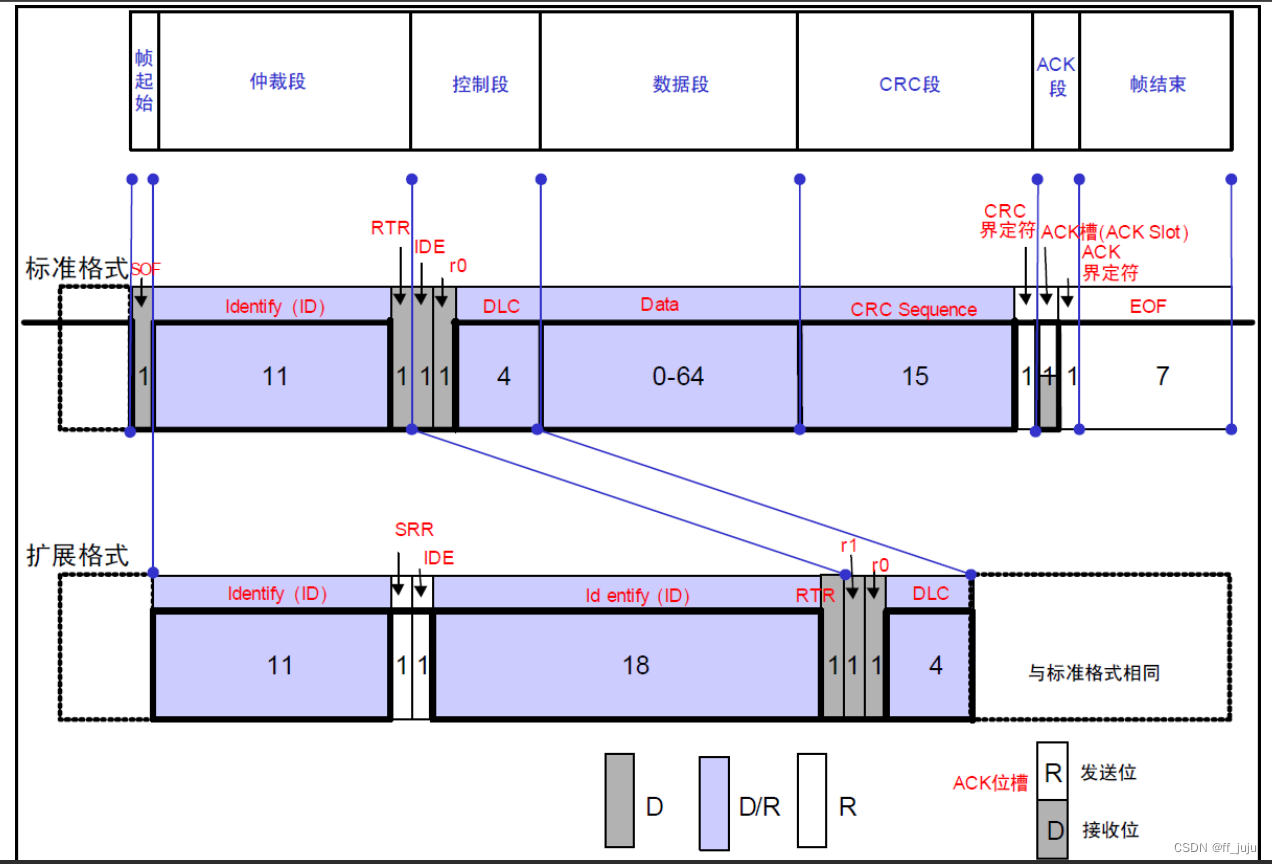 图中 D 表示显性电平,R 表示隐形电平(下同)。
图中 D 表示显性电平,R 表示隐形电平(下同)。
帧起始,这个比较简单,标准帧和扩展帧都是由 1 个位的显性电平表示帧起始。
仲裁段,表示数据优先级的段,标准帧和扩展帧格式在本段有所区别,如图 37.1.2.2 所示: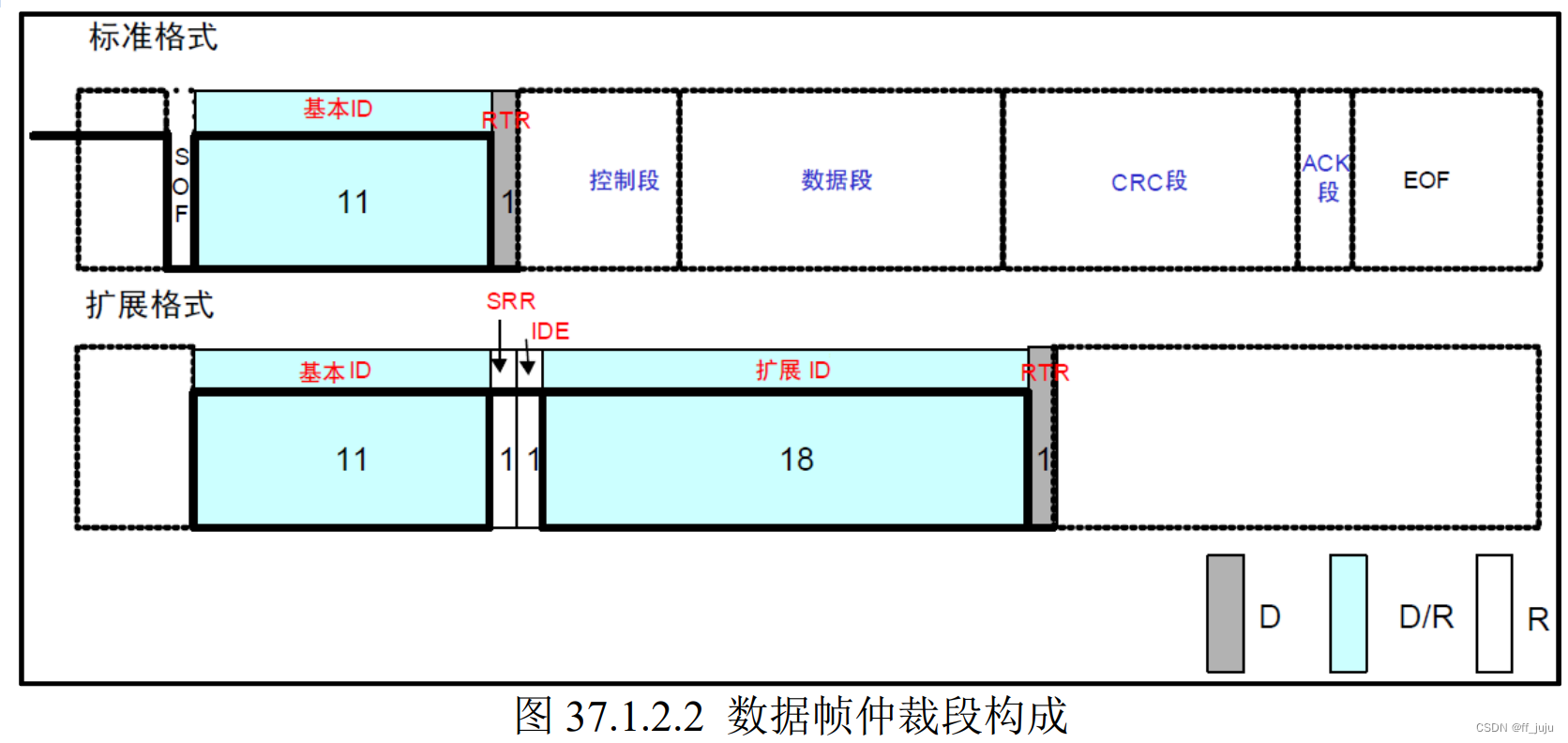 标准格式的 ID 有 11 个位。禁止高 7 位都为隐性(禁止设定:ID=1111111XXXX)。扩展格 式的 ID 有 29 个位。基本 ID 从 ID28 到 ID18,扩展 ID 由 ID17 到 ID0 表示。基本 ID 和标准格 式的 ID 相同。禁止高 7 位都为隐性(禁止设定:基本 ID=1111111XXXX)。
标准格式的 ID 有 11 个位。禁止高 7 位都为隐性(禁止设定:ID=1111111XXXX)。扩展格 式的 ID 有 29 个位。基本 ID 从 ID28 到 ID18,扩展 ID 由 ID17 到 ID0 表示。基本 ID 和标准格 式的 ID 相同。禁止高 7 位都为隐性(禁止设定:基本 ID=1111111XXXX)。
其中 RTR 位用于标识是否是远程帧(0,数据帧;1,远程帧),IDE 位为标识符选择位(0, 使用标准标识符;1,使用扩展标识符),SRR 位为代替远程请求位,为隐性位,它代替了标准 帧中的 RTR 位。
控制段,由 6 个位构成,表示数据段的字节数。标准帧和扩展帧的控制段稍有不同,如图 37.1.2.3 所示: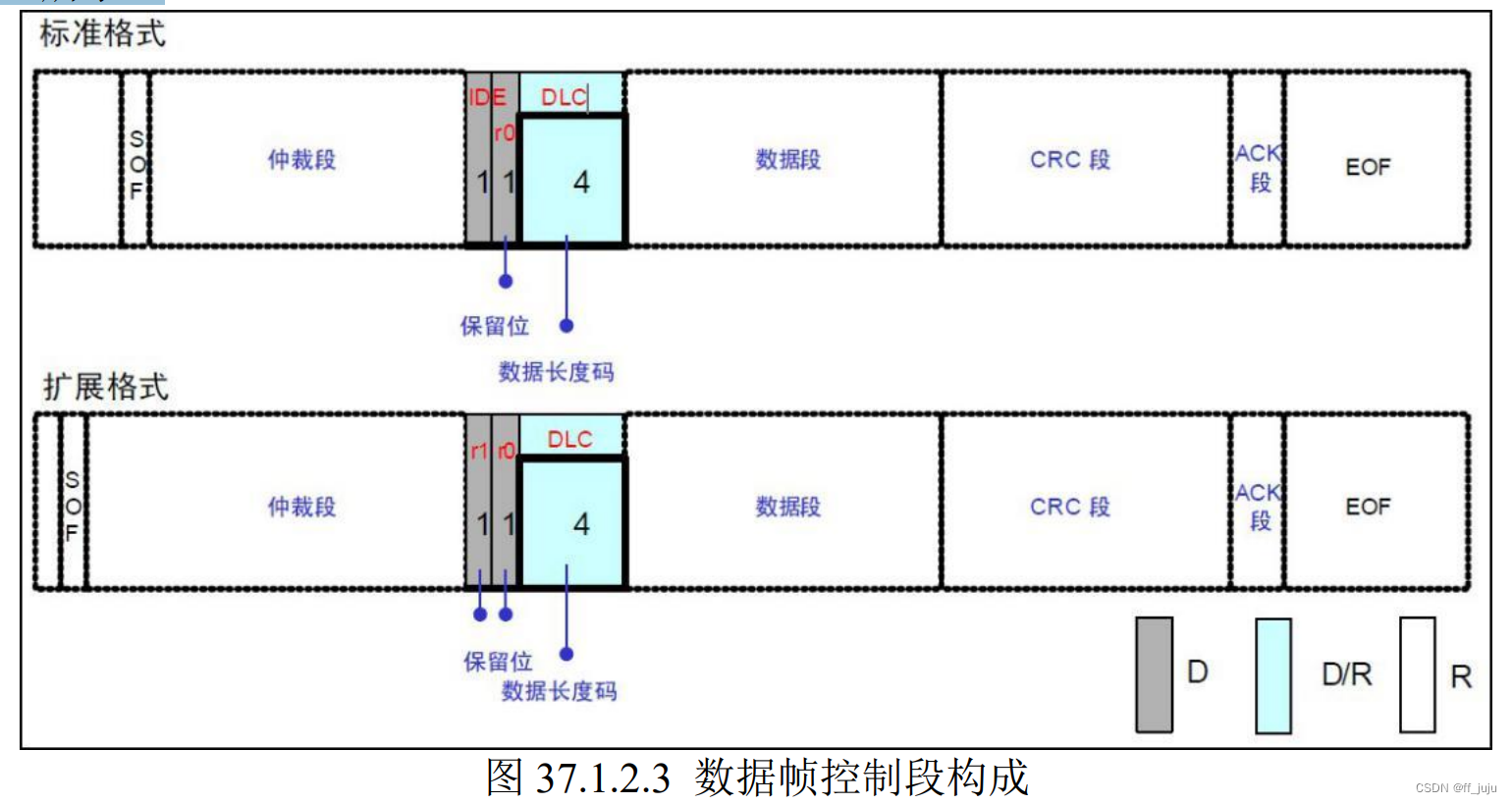 上图中,r0 和 r1 为保留位,必须全部以显性电平发送,但是接收端可以接收显性、隐性及 任意组合的电平。DLC 段为数据长度表示段,高位在前,DLC 段有效值为 0~8,但是接收方接 收到 9~15 的时候并不认为是错误。
上图中,r0 和 r1 为保留位,必须全部以显性电平发送,但是接收端可以接收显性、隐性及 任意组合的电平。DLC 段为数据长度表示段,高位在前,DLC 段有效值为 0~8,但是接收方接 收到 9~15 的时候并不认为是错误。
数据段,该段可包含 0~8 个字节的数据。从最高位(MSB)开始输出,标准帧和扩展帧在 这个段的定义都是一样的。如图 37.1.2.4 所示: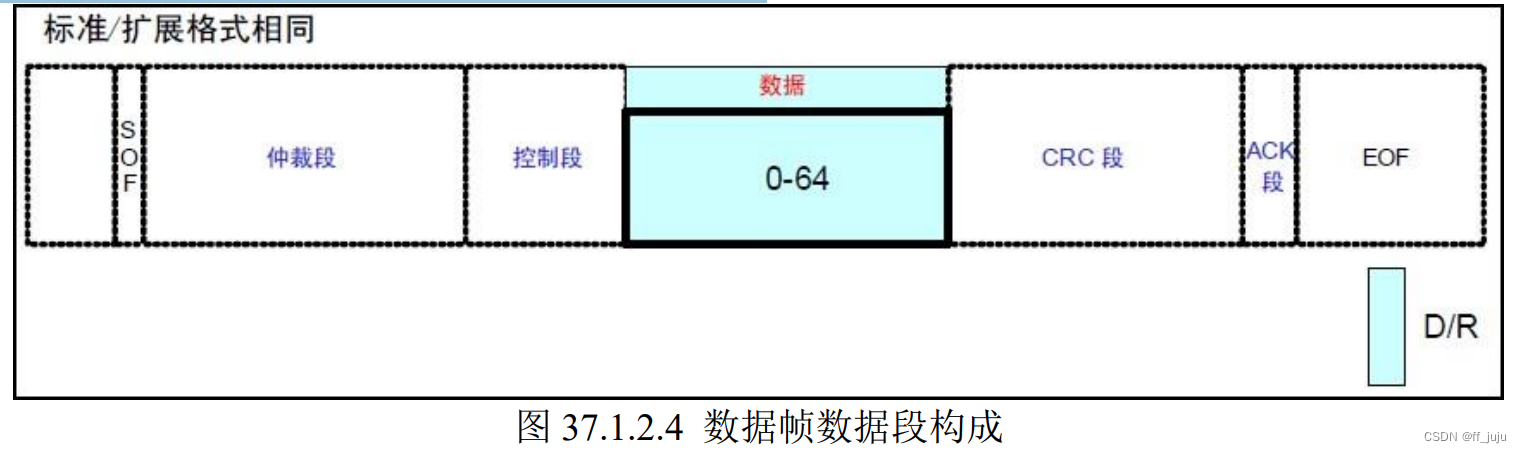
CRC 段,该段用于检查帧传输错误。由 15 个位的 CRC 顺序和 1 个位的 CRC 界定符(用 于分隔的位)组成,标准帧和扩展帧在这个段的格式也是相同的。如图 37.1.2.5 所示: 此段 CRC 的值计算范围包括:帧起始、仲裁段、控制段、数据段。接收方以同样的算法计 算 CRC 值并进行比较,不一致时会通报错误。
此段 CRC 的值计算范围包括:帧起始、仲裁段、控制段、数据段。接收方以同样的算法计 算 CRC 值并进行比较,不一致时会通报错误。
ACK 段,此段用来确认是否正常接收。由 ACK 槽(ACK Slot)和 ACK 界定符 2 个位组成。 标准帧和扩展帧在这个段的格式也是相同的。如图 37.1.2.6 所示: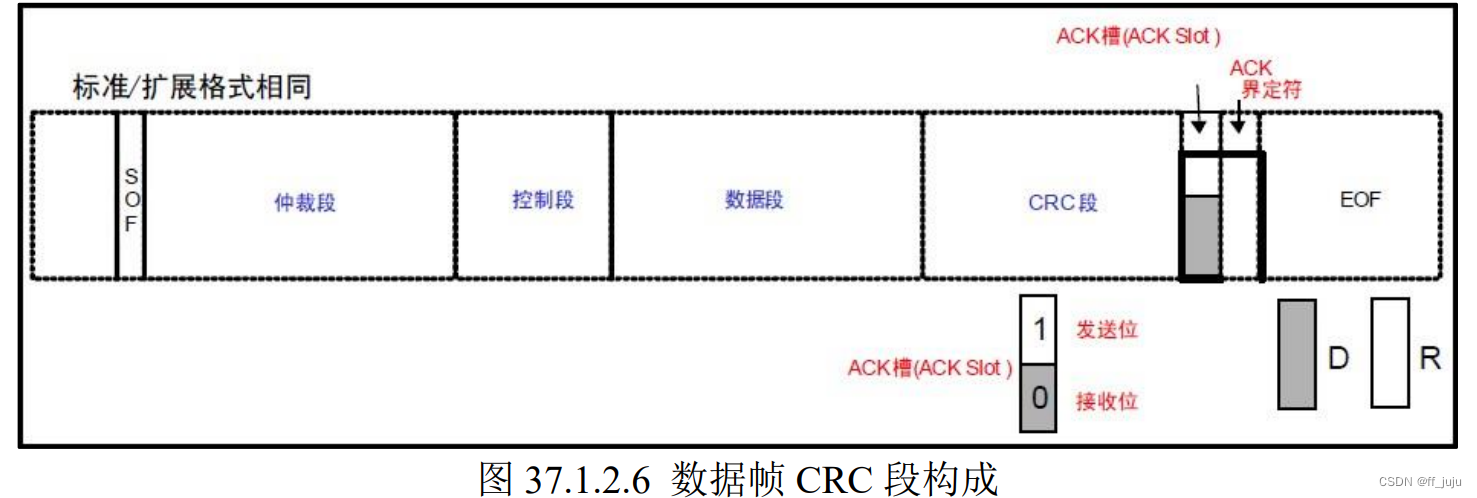 发送单元的 ACK,发送 2 个位的隐性位,而接收到正确消息的单元在 ACK 槽(ACK Slot) 发送显性位,通知发送单元正常接收结束,这个过程叫发送 ACK/返回 ACK。发送 ACK 的是在 既不处于总线关闭态也不处于休眠态的所有接收单元中,接收到正常消息的单元(发送单元不 发送 ACK)。所谓正常消息是指不含填充错误、格式错误、CRC 错误的消息。
发送单元的 ACK,发送 2 个位的隐性位,而接收到正确消息的单元在 ACK 槽(ACK Slot) 发送显性位,通知发送单元正常接收结束,这个过程叫发送 ACK/返回 ACK。发送 ACK 的是在 既不处于总线关闭态也不处于休眠态的所有接收单元中,接收到正常消息的单元(发送单元不 发送 ACK)。所谓正常消息是指不含填充错误、格式错误、CRC 错误的消息。
帧结束,这个段也比较简单,标准帧和扩展帧在这个段格式一样,由 7 个位的隐性位组成。
CAN 位时序
由发送单元在非同步的情况下发送的每秒钟的位数称为位速率。一个位可分为 4 段。
⚫ 同步段(SS)
⚫ 传播时间段(PTS)
⚫ 相位缓冲段 1(PBS1)
⚫ 相位缓冲段 2(PBS2)
这些段又由可称为 Time Quantum(以下称为 Tq)的最小时间单位构成。
1 位分为 4 个段,每个段又由若干个 Tq 构成,这称为位时序。
1 位由多少个 Tq 构成、每个段又由多少个 Tq 构成等,可以任意设定位时序。通过设定位 时序,多个单元可同时采样,也可任意设定采样点。各段的作用和 Tq 数如表 37.1.2.2 所示: 1 个位的构成如图 37.1.2.7 所示:
1 个位的构成如图 37.1.2.7 所示: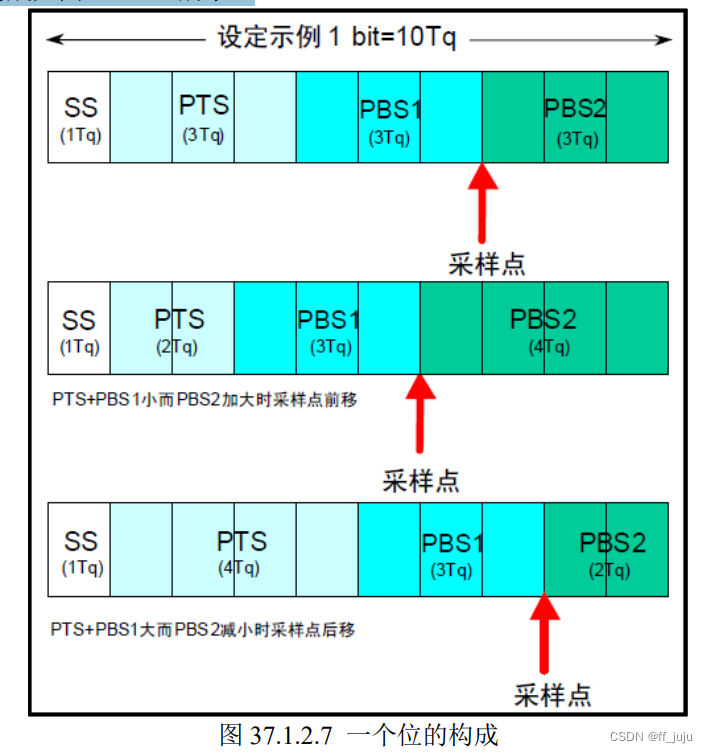 上图的采样点,是指读取总线电平,并将读到的电平作为位值的点。位置在 PBS1 结束处。 根据这个位时序,我们就可以计算 CAN 通信的波特率了。
上图的采样点,是指读取总线电平,并将读到的电平作为位值的点。位置在 PBS1 结束处。 根据这个位时序,我们就可以计算 CAN 通信的波特率了。
CAN 协议仲裁功能
在总线空闲态,最先开始发送消息的单元获得发送权。当多个单元同时开始发送时,各发 送单元从仲裁段的第一位开始进行仲裁。连续输出显性电平最多的单元可继续发送。实现过程, 如图 37.1.2.8 所示: 上图中,单元 1 和单元 2 同时开始向总线发送数据,开始部分他们的数据格式是一样的, 故无法区分优先级,直到 T 时刻,单元 1 输出隐性电平,而单元 2 输出显性电平,此时单元 1 仲裁失利,立刻转入接收状态工作,不再与单元 2 竞争,而单元 2 则顺利获得总线使用权,继 续发送自己的数据。这就实现了仲裁,让连续发送显性电平多的单元获得总线使用权。
上图中,单元 1 和单元 2 同时开始向总线发送数据,开始部分他们的数据格式是一样的, 故无法区分优先级,直到 T 时刻,单元 1 输出隐性电平,而单元 2 输出显性电平,此时单元 1 仲裁失利,立刻转入接收状态工作,不再与单元 2 竞争,而单元 2 则顺利获得总线使用权,继 续发送自己的数据。这就实现了仲裁,让连续发送显性电平多的单元获得总线使用权。
CAN 控制器
STM32F1 自带的是 bxCAN,即基本扩展 CAN。它支持 CAN 协议 2.0A 和 2.0B。CAN2.0A 只能处理标准数据帧,扩展帧的内容会识别错误;CAN2.0BActive 可以处理标准数据帧和扩展 数据帧;而 CAN2.0B passive 只能处理标准数据帧,扩展帧的内容会忽略。它的设计目标是,以 最小的 CPU 负荷来高效处理大量收到的报文。它也支持报文发送的优先级要求(优先级特性可 软件配置)。对于安全紧要的应用,bxCAN 提供所有支持时间触发通信模式所需的硬件功能。
STM32F1 的 bxCAN 的主要特点有:
⚫ 支持 CAN 协议 2.0A 和 2.0B 主动模式
⚫ 波特率最高达 1Mbps
⚫ 支持时间触发通信
⚫ 具有 3 个发送邮箱
⚫ 具有 3 级深度的 2 个接收 FIFO
⚫ 可变的过滤器组(最多 28 个)
在 STM32 互联型产品中,带有 2 个 CAN 控制器,而我们使用的 STM32F103ZET6 属于增 强型,不是互联型,只有 1 个 CAN 控制器。双 CAN 的框图如图 37.1.2.9 所示: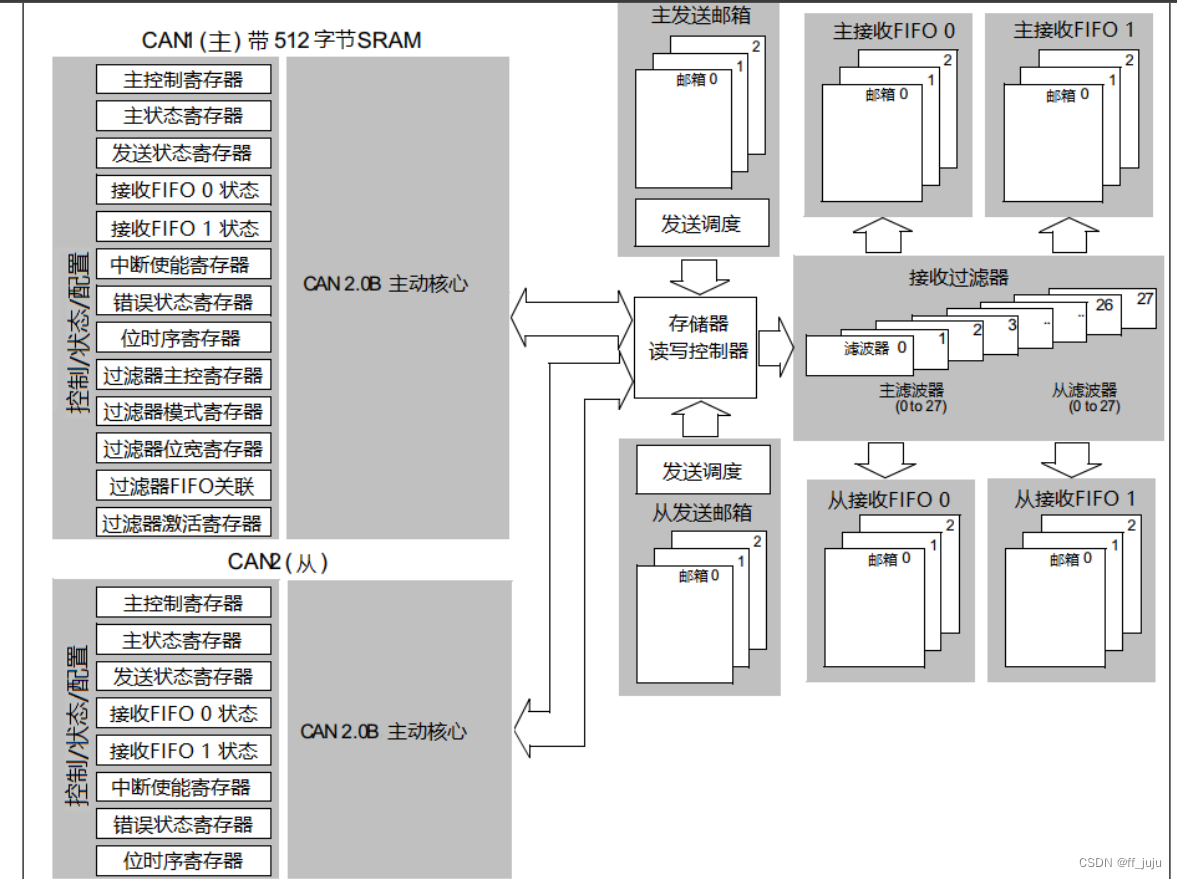 从图中可以看出两个 CAN 都分别拥有自己的发送邮箱和接收 FIFO,但是他们共用 28 个 过滤器。通过 CAN_FMR 寄存器的设置,可以设置过滤器的分配方式。
从图中可以看出两个 CAN 都分别拥有自己的发送邮箱和接收 FIFO,但是他们共用 28 个 过滤器。通过 CAN_FMR 寄存器的设置,可以设置过滤器的分配方式。
STM32 的标识符过滤比较复杂,它的存在减少了 CPU 处理 CAN 通信的开销。STM32 的 过滤器组最多有 28 个(互联型),但是 STM32F103ZET6 只有 14 个(增强型),每个过滤器组 x 由 2 个 32 为寄存器,CAN_FxR1 和 CAN_FxR2 组成。
STM32F1 每个过滤器组的位宽都可以独立配置,以满足应用程序的不同需求。根据位宽的 不同,每个过滤器组可提供:
⚫ 1 个 32 位过滤器,包括:STDID[10:0]、EXTID[17:0]、IDE 和 RTR 位
⚫ 2 个 16 位过滤器,包括:STDID[10:0]、IDE、RTR 和 EXTID[17:15]位
此外过滤器可配置为:屏蔽位模式和标识符列表模式。
在屏蔽位模式下,标识符寄存器和屏蔽寄存器一起,指定报文标识符的任何一位,应该按 照“必须匹配”或“不用关心”处理。
而在标识符列表模式下,屏蔽寄存器也被当作标识符寄存器用。因此,不是采用一个标识 符加一个屏蔽位的方式,而是使用 2 个标识符寄存器。接收报文标识符的每一位都必须跟过滤 器标识符相同。
通过 CAN_FMR 寄存器,可以配置过滤器组的位宽和工作模式,如图 37.1.2.10 所示: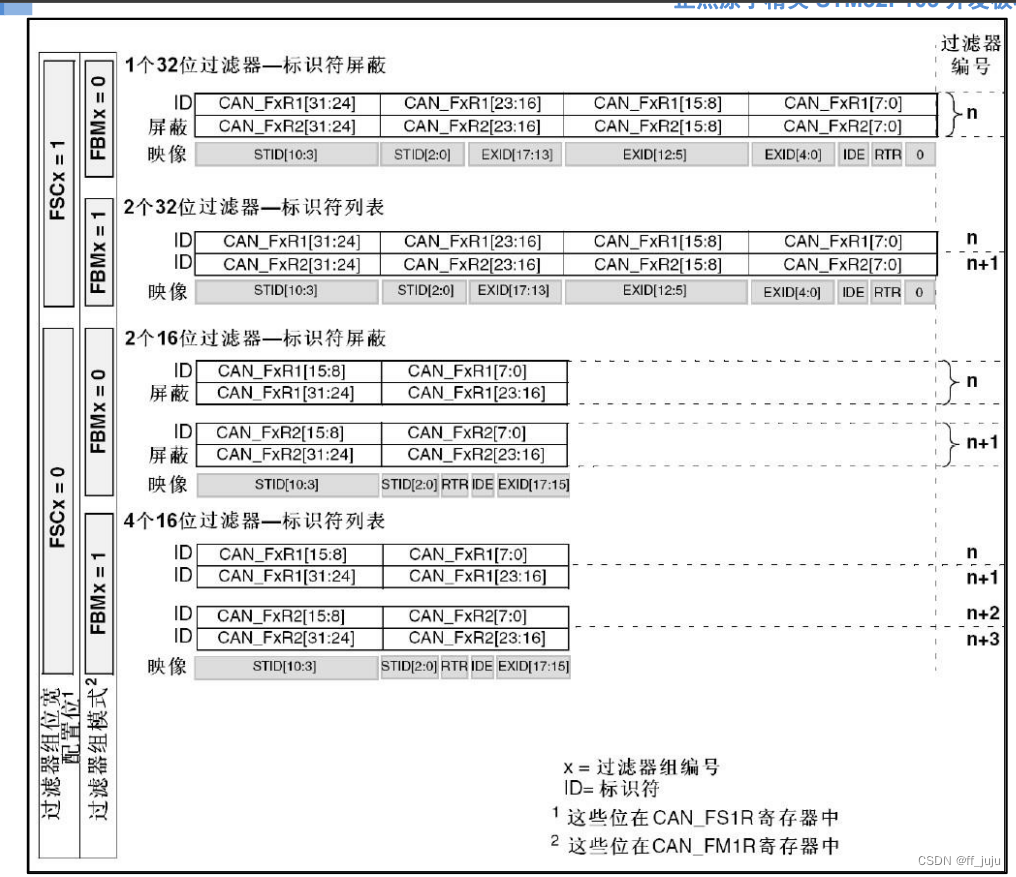 为了过滤出一组标识符,应该设置过滤器组工作在屏蔽位模式。
为了过滤出一组标识符,应该设置过滤器组工作在屏蔽位模式。
为了过滤出一个标识符,应该设置过滤器组工作在标识符列表模式。应用程序不用的过滤 器组,应该保持在禁用状态。
过滤器组中的每个过滤器,都被编号为(叫做过滤器号,图 37.1.2.9 中的 n)从 0 开始,到某 个最大数值-取决于过滤器组的模式和位宽的设置。
举个简单的例子,我们设置过滤器组 0 工作在:1 个 32 为位过滤器-标识符屏蔽模式,然后 设置 CAN_F0R1=0XFFFF0000,CAN_F0R2=0XFF00FF00。其中存放到 CAN_F0R1 的值就是期 望收到的 ID,即我们希望收到的映像(STID+EXTID+IDE+RTR)最好是:0XFFFF0000。而 0XFF00FF00 就是设置我们需要必须关心的 ID,表示收到的映像,其位[31:24]和位[15:8]这 16 个位的必须和 CAN_F0R1 中对应的位一模一样,而另外的 16 个位则不关心,可以一样,也可 以不一样,都认为是正确的 ID,即收到的映像必须是 0XFFxx00xx,才算是正确的(x 表示不关 心),这里需要注意的是标识符选择位 IDE 和帧类型 RTR 需要一致。其情况如下图 37.1.2.11 所 示: 接下来,我们看看 STM32 的 CAN 发送和接收的流程。
接下来,我们看看 STM32 的 CAN 发送和接收的流程。
CAN 发送流程
CAN 发送流程为:程序选择 1 个空置的邮箱(TME=1)→设置标识符(ID),数据长度和 发送数据→设置 CAN_TIxR 的 TXRQ 位为 1,请求发送→邮箱挂号(等待成为最高优先级)→ 预定发送(等待总线空闲)→发送→邮箱空置。整个流程如图 37.1.2.12 所示: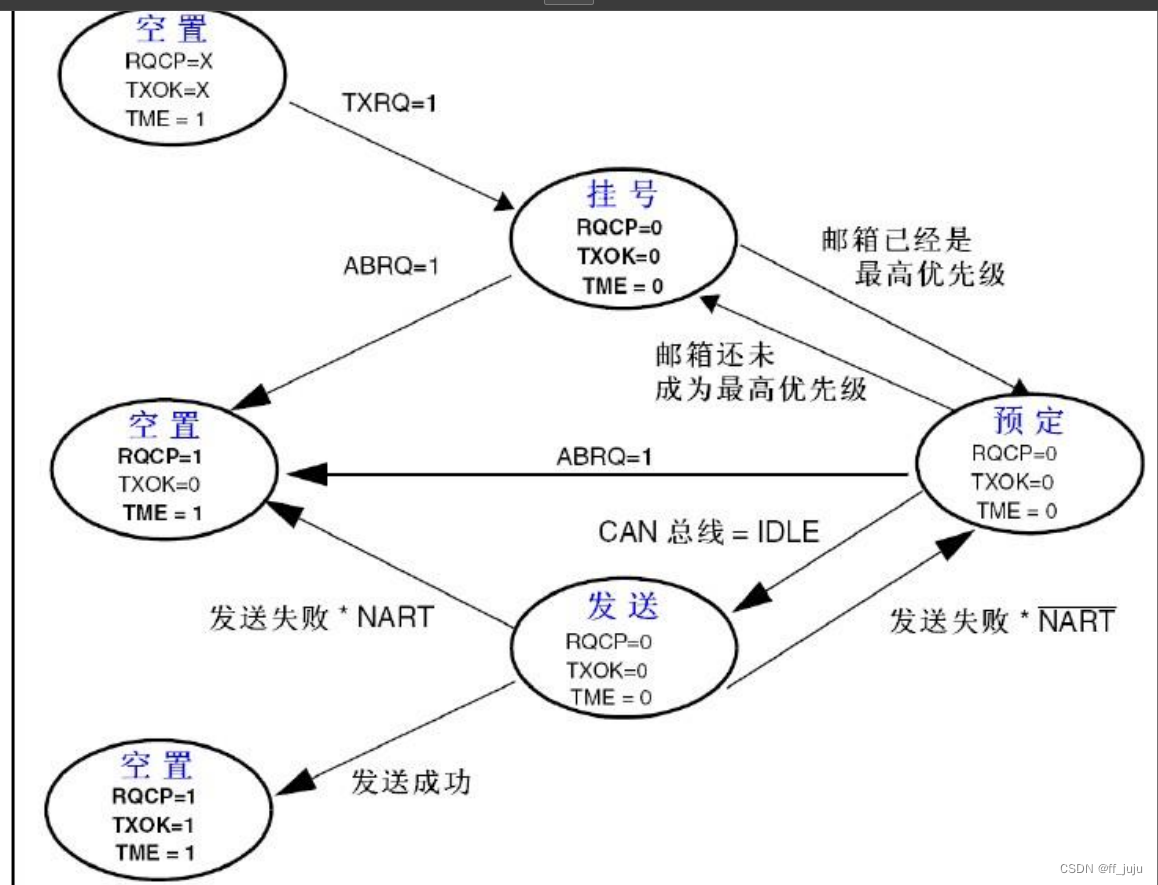 上图中,还包含了很多其他处理,发送中止请求(ABRQ=1)和发送失败处理等。通过这个 流程图,我们大致了解了 CAN 的发送流程,后面的数据发送,我们基本就是按照此流程来走。
上图中,还包含了很多其他处理,发送中止请求(ABRQ=1)和发送失败处理等。通过这个 流程图,我们大致了解了 CAN 的发送流程,后面的数据发送,我们基本就是按照此流程来走。
CAN 接收流程
CAN 接收到的有效报文,被存储在 3 级邮箱深度的 FIFO 中。FIFO 完全由硬件来管理,从 而节省了 CPU 的处理负荷,简化了软件并保证了数据的一致性。应用程序只能通过读取 FIFO 输出邮箱,来读取 FIFO 中最先收到的报文。这里的有效报文是指那些正确被接收的(直到 EOF 都没有错误)且通过了标识符过滤的报文。前面我们知道 CAN 的接收有 2 个 FIFO,我们每个 过滤器组都可以设置其关联的 FIFO,通过 CAN_FFA1R 的设置,可以将过滤器组关联到 FIFO0/FIFO1。
CAN 接收流程为:FIFO 空→收到有效报文→挂号_1(存入 FIFO 的一个邮箱,这个由硬件 控制,我们不需要理会)→收到有效报文→挂号_2→收到有效报文→挂号_3→收到有效报文溢 出。
这个流程里面,我们没有考虑从 FIFO 读出报文的情况,实际情况是:我们必须在 FIFO 溢 出之前,读出至少 1 个报文,否则下个报文到来,将导致 FIFO 溢出,从而出现报文丢失。每读 出 1 个报文,相应的挂号就减 1,直到 FIFO 空。CAN 接收流程如图 37.2.1.13 所示: FIFO 接收到的报文数,我们可以通过查询 CAN_RFxR 的 FMP 寄存器来得到,只要 FMP 不为 0,我们就可以从 FIFO 读出收到的报文。
FIFO 接收到的报文数,我们可以通过查询 CAN_RFxR 的 FMP 寄存器来得到,只要 FMP 不为 0,我们就可以从 FIFO 读出收到的报文。
STM32 的 CAN 位时序特性
接下来,我们简单看看 STM32 的 CAN 位时间特性,STM32 的 CAN 位时间特性和之前我 们介绍的 CAN 协议中,稍有点区别。STM32 把传播时间段和相位缓冲段 1(STM32 称之为时 间段 1)合并了,所以 STM32 的 CAN 一个位只有 3 段:同步段(SYNC_SEG)、时间段 1(BS1) 和时间段 2(BS2)。STM32 的 BS1 段可以设置为 1~16 个时间单元,刚好等于我们上面介绍的 传播时间段和相位缓冲段 1 之和。STM32 的 CAN 位时序如图 37.2.1.14 所示:
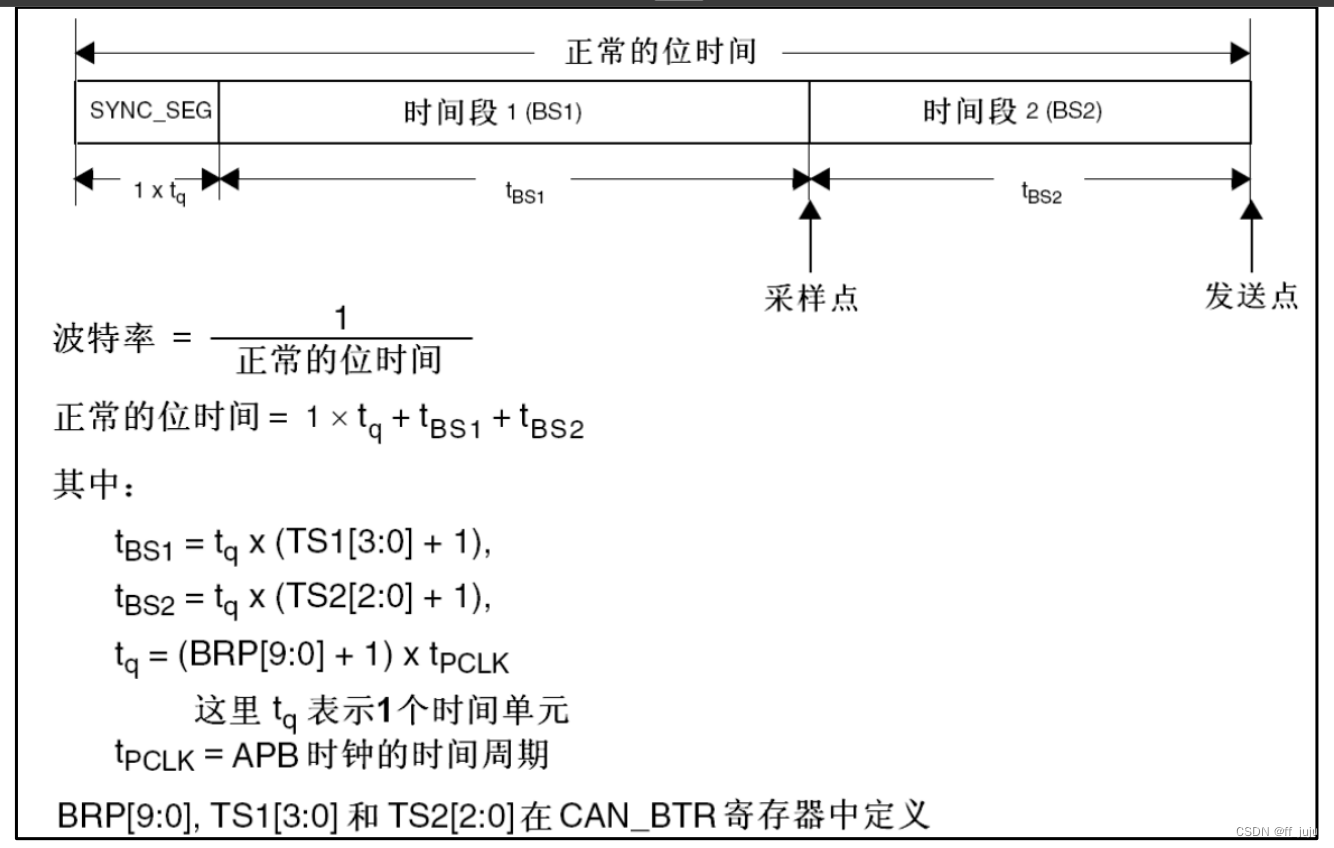 图中还给出了 CAN 波特率的计算公式,我们只需要知道 BS1 和 BS2 的设置,以及 APB1 的时钟频率(一般为 36Mhz),就可以方便的计算出波特率。比如设置 TS1=8、TS2=7 和 BRP=3, 在 APB1 频率为 36Mhz 的条件下,即可得到 CAN 通信的波特率=36000/[(9+8+1)*4]=500Kbps。
图中还给出了 CAN 波特率的计算公式,我们只需要知道 BS1 和 BS2 的设置,以及 APB1 的时钟频率(一般为 36Mhz),就可以方便的计算出波特率。比如设置 TS1=8、TS2=7 和 BRP=3, 在 APB1 频率为 36Mhz 的条件下,即可得到 CAN 通信的波特率=36000/[(9+8+1)*4]=500Kbps。