上海公司网站建设以子为什么不要做外包员工
RBAC权限模型
Role-Based Access Control,中文意思是:基于角色(Role)的访问控制。这是一种广泛应用于计算机系统和网络安全领域的访问控制模型。
简单来说,就是通过将权限分配给➡角色,再将角色分配给➡用户,来实现对系统资源的访问控制。一个用户拥有若干角色,每一个角色拥有若干权限。这样,就构造成“用户-角色-权限”的授权模型。在这种模型中,用户与角色之间,角色与权限之间,一般者是多对多的关系
具体概念可以查看RBAC——基于角色权限的模型
这里我只演示如何在Mybatis中实现RBAC权限模型的查询
现在有四张表
CREATE TABLE `user`
(`username` varchar(50) NOT NULL,`password` varchar(200) NOT NULL,`name` varchar(50),PRIMARY KEY (`username`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- 创建角色表
CREATE TABLE `role`
(`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(50),PRIMARY KEY (`id`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- 创建用户角色表
CREATE TABLE `user_role`
(`username` varchar(50),`role_id` int(11),PRIMARY KEY (`username`, `role_id`),FOREIGN KEY (`role_id`) REFERENCES `role` (`id`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- 创建菜单表
CREATE TABLE `menu`
(`id` int(11) NOT NULL AUTO_INCREMENT,`name` varchar(50),`parent_id` int(11),PRIMARY KEY (`id`),FOREIGN KEY (`parent_id`) REFERENCES `menu` (`id`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;-- 创建角色菜单表
CREATE TABLE `role_menu`
(`role_id` int(11),`menu_id` int(11),PRIMARY KEY (`role_id`, `menu_id`),FOREIGN KEY (`role_id`) REFERENCES `role` (`id`),FOREIGN KEY (`menu_id`) REFERENCES `menu` (`id`)
) ENGINE = InnoDBDEFAULT CHARSET = utf8mb4;# ------------------------------------------------------------------------- 插入用户数据
INSERT INTO user (username, password, name) VALUES ('user1', 'password1', 'User 1');
INSERT INTO user (username, password, name) VALUES ('user2', 'password2', 'User 2');-- 插入角色数据
INSERT INTO role (name) VALUES ('file_role');
INSERT INTO role (name) VALUES ('db_role');-- 插入用户角色数据
INSERT INTO user_role (username, role_id) VALUES ('user1', 1);
INSERT INTO user_role (username, role_id) VALUES ('user2', 2);-- 插入菜单数据
INSERT INTO menu (name, parent_id) VALUES ('File', NULL);
INSERT INTO menu (name, parent_id) VALUES ('Database', NULL);
INSERT INTO menu (name, parent_id) VALUES ('File Access', 1);
INSERT INTO menu (name, parent_id) VALUES ('Database Access', 2);-- 插入角色菜单数据
INSERT INTO role_menu (role_id, menu_id) VALUES (1, 3);
INSERT INTO role_menu (role_id, menu_id) VALUES (2, 4);
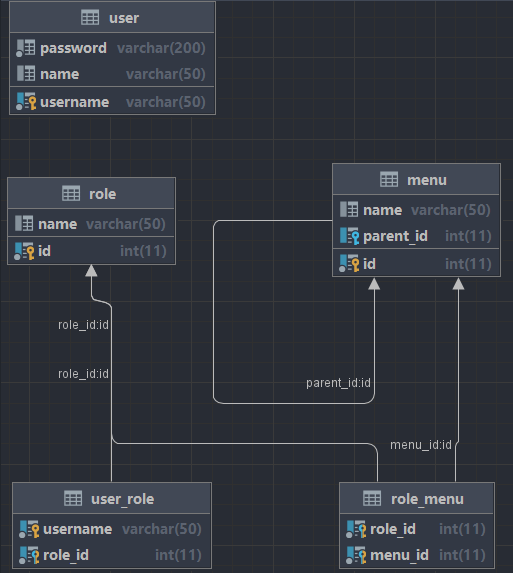
根据表分析,其实具有对应实体类的表只有user用户表和menu菜单表,其他的表都是用来关联和描述关系的,所以实体类只需要User和Menu
准备实体类User、Menu
@Data
public class User {private String username;private String password;private String name;private Menu menu;//一个用户只有一个菜单
}
//-------------------------------------------------
@Data
public class Menu {private Integer id;private String name;private Integer parentId;private List<Menu> sonMenus;//一个父级菜单下可能有多个子菜单
}
准备userMapper接口
public interface UserMapper {// 使用mybatis完成任意用户拥有的菜单查询List<User> getUsers();//使用mybatis的级联查询完成菜单的查询(包含子菜单)List<User> getUsersInclude();
}
准备userMapper.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="cn.cnmd.mapper.UserMapper"><resultMap id="map1" type="user"><result property="username" column="username"/><result property="name" column="name"/><association property="menu" javaType="menu"><id property="id" column="menuId"/><result property="name" column="menuName"/><result property="parentId" column="menuParentId"/></association></resultMap><!--任意用户拥有的菜单查询--><select id="getUsers" resultMap="map1">SELECT u.username, u.name, m.name menuName, m.id menuId, m.parent_id menuParentIdFROM rbac.user uJOIN rbac.user_role ur ON u.username = ur.usernameJOIN rbac.role r ON ur.role_id = r.idJOIN rbac.role_menu rm ON r.id = rm.role_idJOIN rbac.menu m ON rm.menu_id = m.id;</select><!-- ================================================================ --><resultMap id="map2" type="user"><result property="username" column="username"/><result property="name" column="name"/><association property="menu" javaType="menu"><result property="name" column="parent_menu_name"/><collection property="sonMenus" ofType="menu"><result property="name" column="son_menu_name"/></collection></association></resultMap><!--完成菜单的查询(包含子菜单)--><select id="getUsersInclude" resultMap="map2">SELECT u.username, u.name, mp.name as parent_menu_name, m.name as son_menu_nameFROM rbac.user uJOIN rbac.user_role ur ON u.username = ur.usernameJOIN rbac.role r ON ur.role_id = r.idJOIN rbac.role_menu rm ON r.id = rm.role_idJOIN rbac.menu m ON rm.menu_id = m.idJOIN rbac.menu mp ON m.parent_id = mp.id;</select></mapper>
Java代码
SqlSession session = MybatisUtil.getSession();
UserMapper mapper = session.getMapper(UserMapper.class);List<User> users = mapper.getUsers();
users.forEach(System.out::println);System.out.println("====================================");List<User> usersInclude = mapper.getUsersInclude();
usersInclude.forEach(System.out::println);
查询结果
User(username=user1, password=null, name=User 1, menu=Menu(id=3, name=File Access, parentId=1, sonMenus=null))
User(username=user2, password=null, name=User 2, menu=Menu(id=4, name=Database Access, parentId=2, sonMenus=null))====================================User(username=user1, password=null, name=User 1, menu=Menu(id=null, name=File, parentId=null, sonMenus=[Menu(id=null, name=File Access, parentId=null, sonMenus=null)]))
User(username=user2, password=null, name=User 2, menu=Menu(id=null, name=Database, parentId=null, sonMenus=[Menu(id=null, name=Database Access, parentId=null, sonMenus=null)]))
如果需要单独完成菜单的查询(包含子菜单)
只需要重新创建MenuMapper接口
public interface MenuMapper {List<Menu> getMenus();
}
创建MenuMapper.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapperPUBLIC "-//mybatis.org//DTD Mapper 3.0//EN""http://mybatis.org/dtd/mybatis-3-mapper.dtd"><mapper namespace="cn.cnmd.mapper.MenuMapper"><resultMap id="map" type="menu"><id property="id" column="parent_menu_id"/><result property="name" column="parent_menu_name"/><collection property="sonMenus" ofType="menu"><id property="id" column="son_menu_id"/><result property="name" column="son_menu_name"/></collection></resultMap><select id="getMenus" resultMap="map">SELECT m.id parent_menu_id, m.name as parent_menu_name, ms.id son_menu_id, ms.name as son_menu_nameFROM rbac.menu mJOIN rbac.menu msON m.id = ms.parent_id;</select></mapper>
查询结果
Menu(id=1, name=File, parentId=null, sonMenus=[Menu(id=3, name=File Access, parentId=null, sonMenus=null)])
Menu(id=2, name=Database, parentId=null, sonMenus=[Menu(id=4, name=Database Access, parentId=null, sonMenus=null)])