dede网站架设教程番禺响应式网站建设
一、前言
作为一个职业打工人,每天点外卖吃啥东西都有选择综合症,突发奇想让程序帮我们随机选择一个吃的,是不是可以解决我们的选择问题呢,说干就干,我们就使用HarmonyOS元服务实现一下这个功能。为什么选择这个HarmonyOS元服务呢?主要是因为HarmonyOS元服务(HarmonyOS Foundation Services,简称HMF)是HarmonyOS的核心组件之一,它提供了一系列底层功能和服务,为开发者提供了丰富的功能和工具来构建应用程序。HarmonyOS元服务可以帮助开发者构建跨设备的应用程序,实现设备间的互联互通,并提供丰富的功能和工具,简化开发流程,提升开发效率,这样看来实现我们的需求应该不在话下。
二、环境准备
1.安装最新版DevEco Studio。
安装完成如图所示:

2.配置开发环境
这里主要下载Node.js、ohpm和SDK,单击Finish,界面会进入到DevEco Studio欢迎页。
主要注意的是:安装Node.js与ohpm。可以指定本地已安装的Node.js或ohpm(Node.js版本要求为v14.19.1及以上,且低于v17.0.0;对应的npm版本要求为6.14.16及以上)路径位置;如果本地没有合适的版本,可以选择Install按钮,选择下载源和存储路径后,进行在线下载,单击Next进入下一步。
像我们前端开发工程师,本地一般都是安装过Node.js.这个版本不对可以在重新下载合适的版本,不会覆盖。
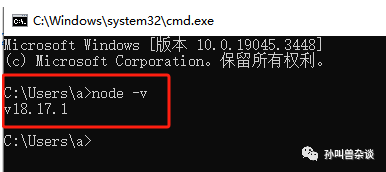
比如我这个版本比较高,需要安装一个v14.19.1及以上,且低于v17.0.0版本node.编译器会提示对应的信息。
具体请参考:https://developer.harmonyos.com/cn/docs/documentation/doc-guides-V3/environment_config-0000001052902427-V3
3.配置HDC工具环境变量
HDC是为开发者提供HarmonyOS应用/服务的调试工具,为方便使用HDC工具,请为HDC端口号设置环境变量。
Windows环境变量设置方法:在此电脑 > 属性 > 高级系统设置 > 高级 > 环境变量中,添加HDC端口变量名为:HDC_SERVER_PORT,变量值可设置为任意未被占用的端口,如7035。
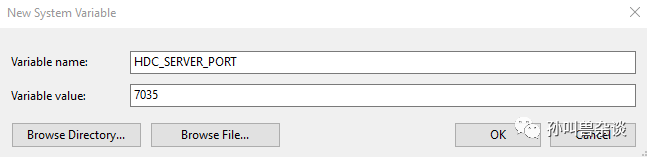
环境变量配置完成后,关闭并重启DevEco Studio。
4.诊断开发环境
DevEco Studio提供了开发环境诊断的功能,帮助您识别开发环境是否完备。您可以在欢迎界面单击Help > Diagnose Development Environment进行诊断。如果您已经打开了工程开发界面,也可以在菜单栏单击Help > Diagnostic Tools > Diagnose Development Environment进行诊断。
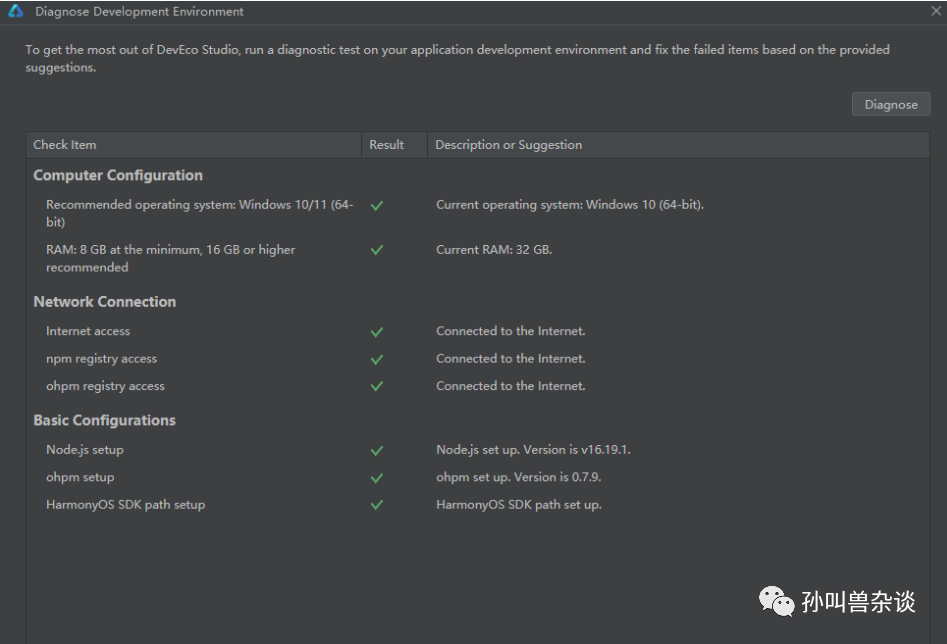
如图所示代表配置环境OK,下面就可以快乐的玩耍了。
三、开发今天吃什么小程序
1.设计思路。
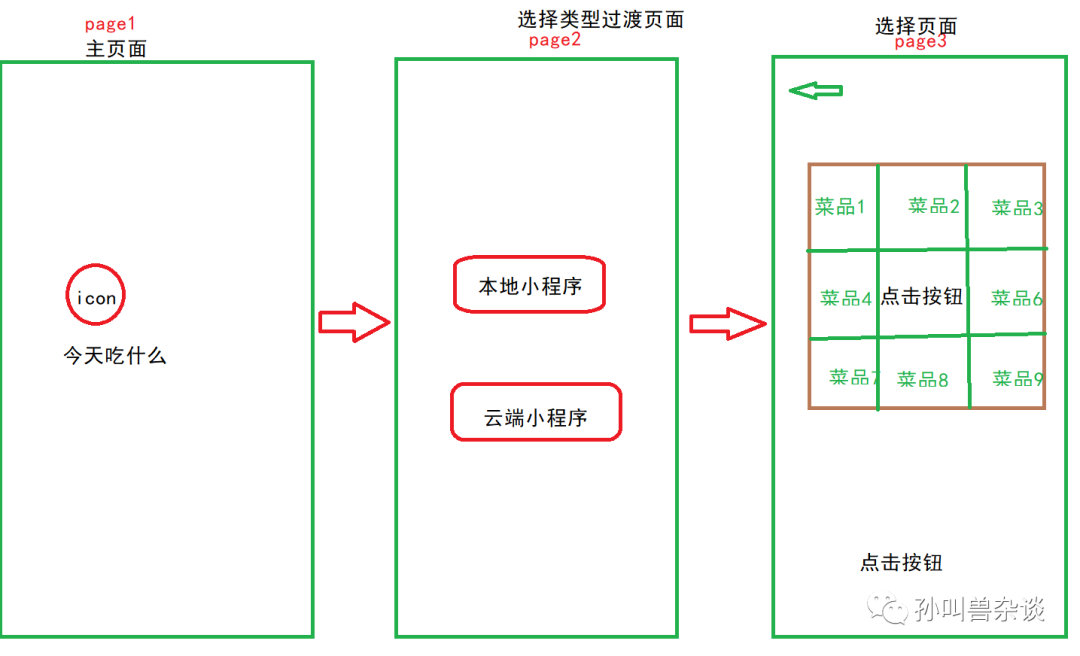
简单画个草图需要实现的功能。主要有三个页面,主屏幕需要提供一个114*114的icon。一个过渡页面用于选择使用本地的小程序还是云端的小程序,也可以直接从page1过渡到page3直接选择,page3主要是一个菜品网格列表,可以使用mock数据或者在线菜品列表进行实时更新,这里简单使用mock数据,里面使用400*400的图片代替。点击中间的按钮触发点击事件随机选择一个菜品并进行弹窗提示。
2.图标设置
在项目路径AppScope/app.json5设置应用的名称及基本参数,在项目路径AppScope/resources/base/media/app_icon.png引入一个自己设计的114*114的icon图片。
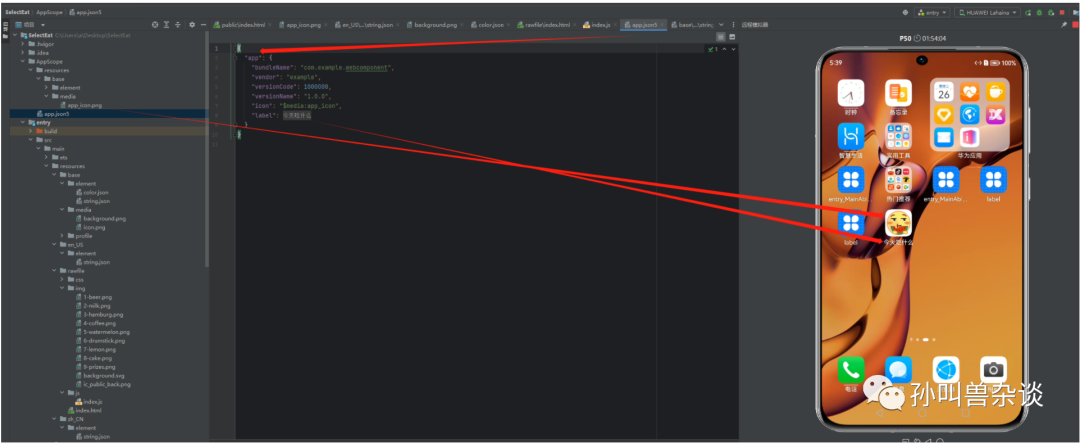
3.构建过渡页面的entryability和pages。
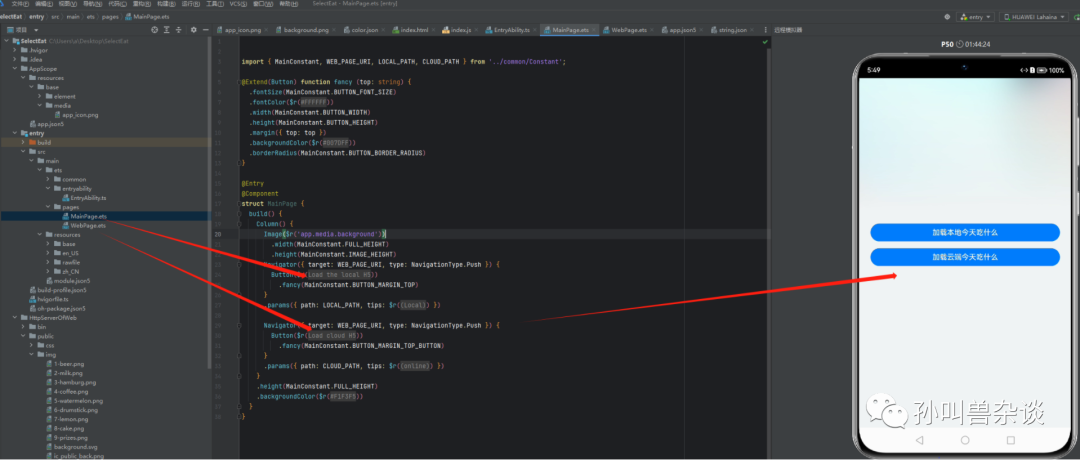
4.搭建一个简单的web服务用于page3的页面展示及数据展示。
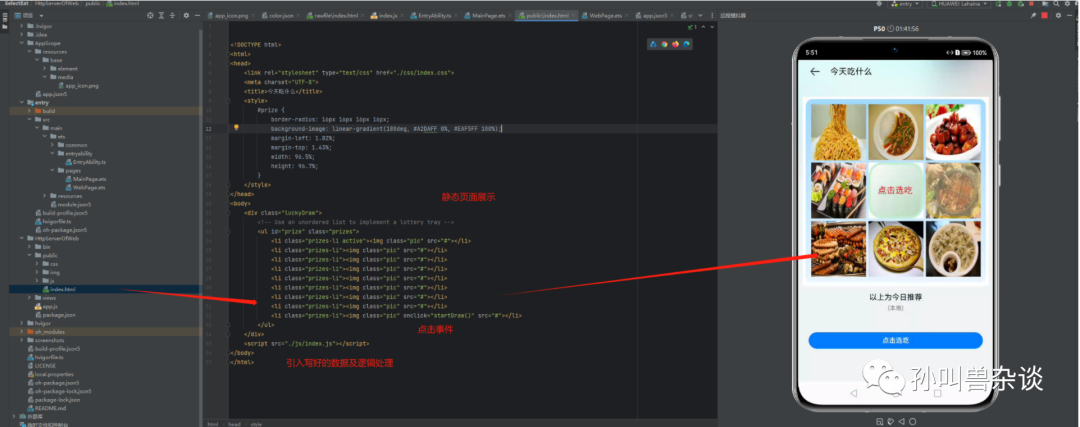
5.定义数据格式及图片,使用js控制点击事件的图片选择并给出提示。
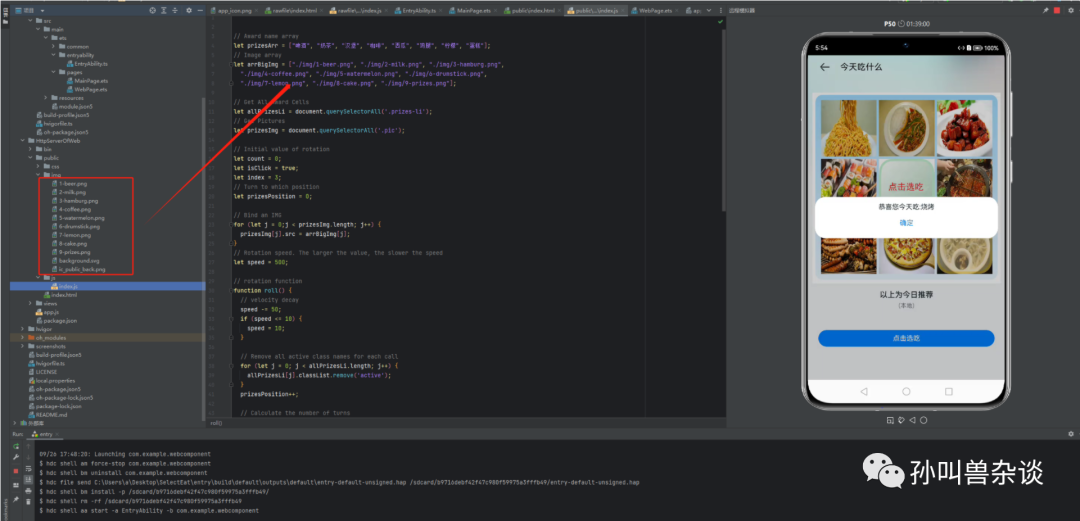
这个一个完整的应用就开发完了,这个数据和图片可以从网络获取,有兴趣的同学可以在此基础上完善。
四、上架及部署
开发、调试完HarmonyOS应用/元服务,就可以在AppGallery Connect申请上架,华为审核通过后,用户即可在华为应用市场获取您的HarmonyOS应用/元服务。HarmonyOS会通过数字证书与Profile文件等签名信息来保证应用的完整性,需要上架的HarmonyOS应用/元服务都必须通过签名校验,所以上架前,您需要先完成签名操作。

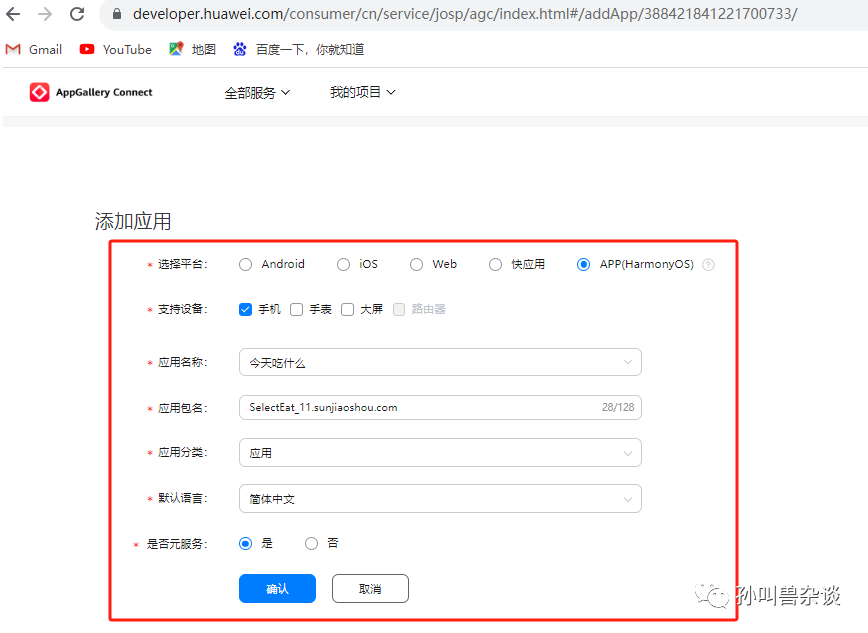
比如我创建一个项目叫“今天吃什么”,不需要勾选华为分析这个指标,这个仅仅是为了跑一边流程。
1.添加应用
2.生成证书及密钥请求文件
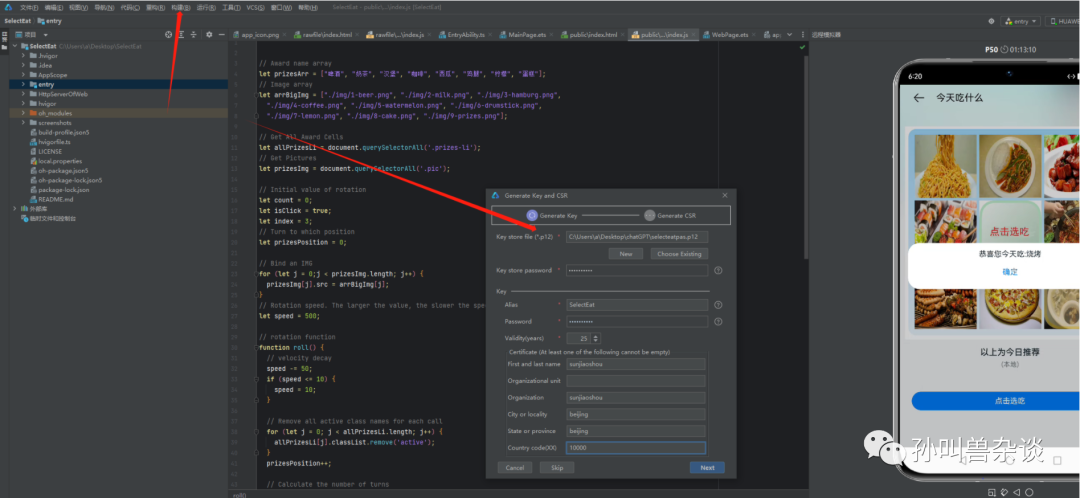
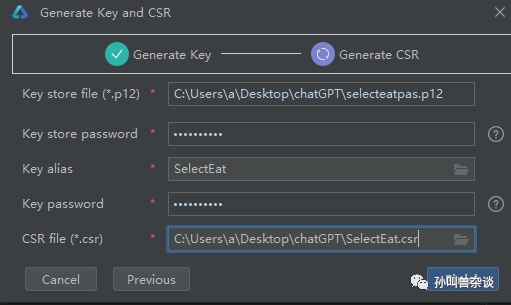
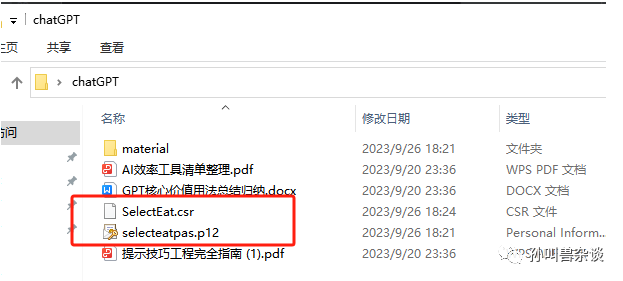
CSR文件创建成功后,将在存储路径下获取生成密钥库文件(.p12)和证书请求文件(.csr)。
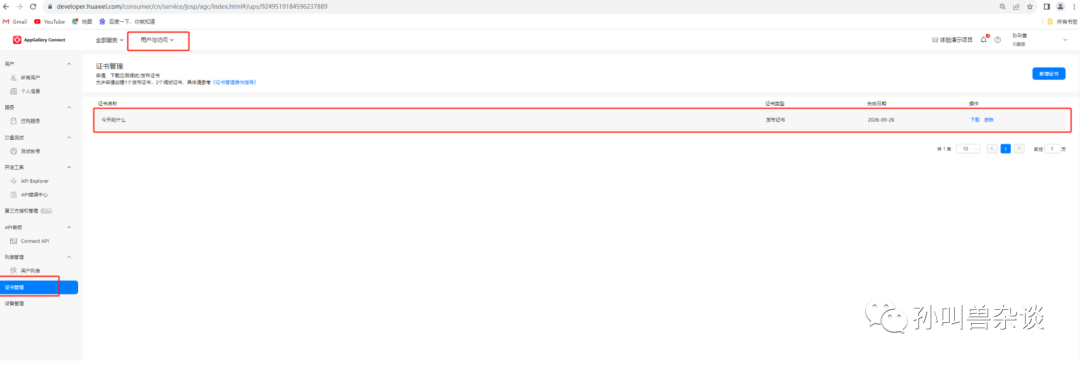
3.申请发布证书
左侧导航栏选择“证书管理”,进入“证书管理”页面,点击“新增证书”,证书申请成功后,“证书管理”页面展示生成的证书内容。点击“下载”将生成的证书保存至本地。每个帐号最多申请1个发布证书,如果证书已过期或者无需使用,点击“废除”即可删除证书。
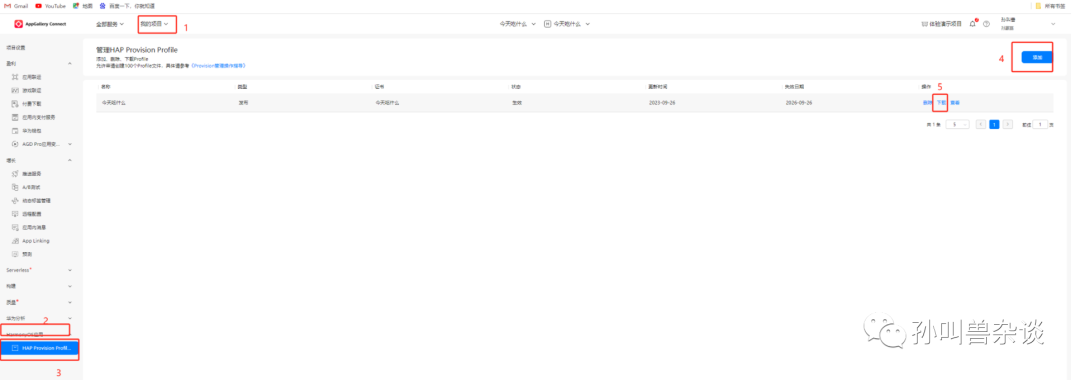
4.申请发布Profile
选择“我的项目”。找到对应项目,点击项目卡片中需要发布的元服务。导航选择“HarmonyOS应用 > HAP Provision Profile管理”,进入“管理HAP Provision Profile”页面,点击“添加”。申请成功,即可在“管理HAP Provision Profile”页面查看Profile信息。点击“下载”,将文件下载到本地。
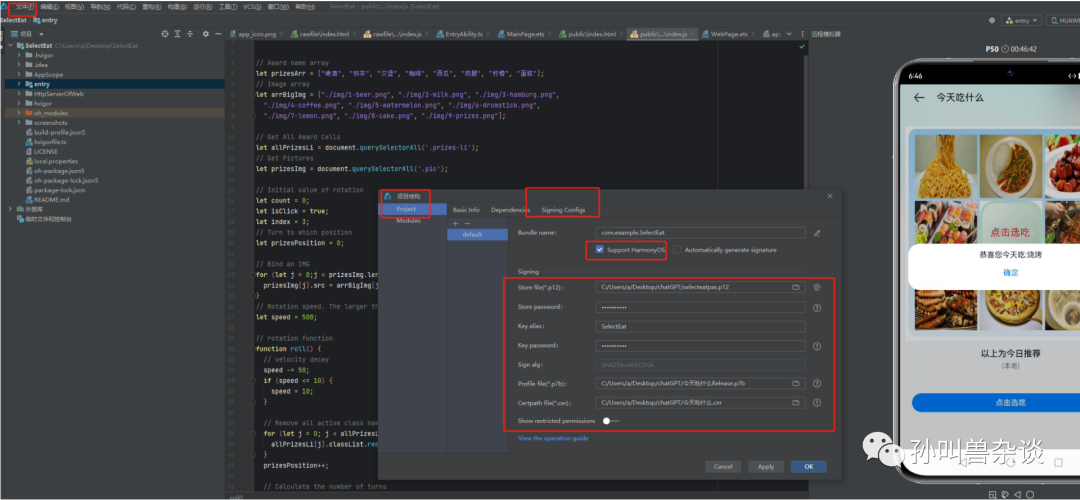
5.配置签名信息
我这个是API 9应用/元服务签名界面。
菜单选择“File > Project Structure”,进入“Project Structure”界面。
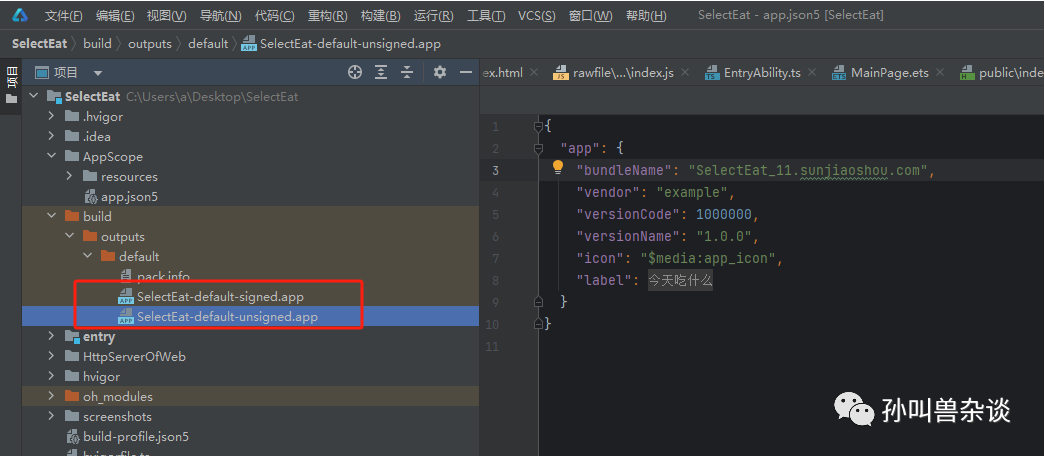
6.编译打包
打开DevEco Studio,菜单选择“Build > Build Hap(s)/APP(s) > Build APP(s)”。API 9应用/元服务软件包获取路径:工程目录build > output > default目录。
7.上架HarmonyOS应用/元服务
选择“我的应用”。在应用列表首页中点击“HarmonyOS应用”页签,点击待发布的应用/元服务,在左侧导航栏选择“应用信息”菜单。填写应用的基本信息,如语言,应用名称,应用介绍等,上传应用图标,所有配置完成后点击“保存”。填写版本信息,如发布国家或地区、上传软件包、提交资质材料等,所有配置完成后点击右上角“提交审核”即可。
五、常见项目结构及快捷键调试方法
1.目录结构

2.常用的快捷键及编译器技巧
2.1 shfit+F10运行项目。
2.2 shfit+F9调试。
2.3 一般可以设备管理器中使用本地模拟器或者远程模拟器,这里我觉得开发调试使用远程的模拟器比较快点,本地的还得下载2G多的镜像文件。
2.4 下载编译器可以直接汉化一下。
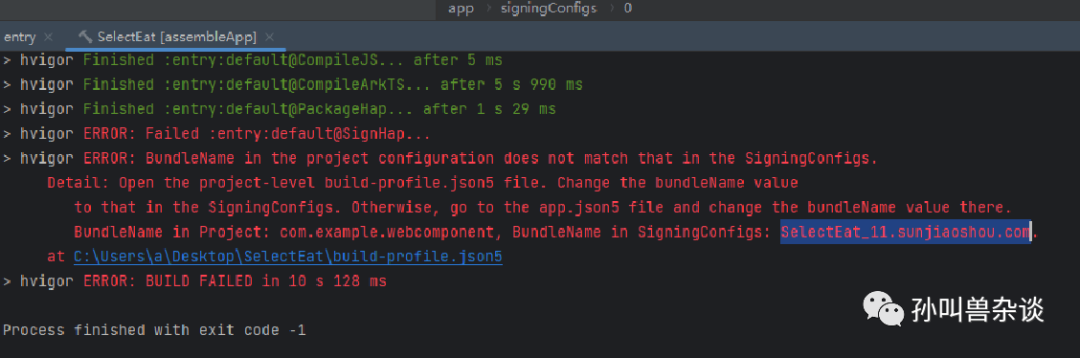
2.5 出现程序错误一般编译器都有错误提示或者快捷连接提供解决办法,仔细查看日志及文档一般都可以自己解决,如果自己解决不了可以在社区提问。比如下图所示报错就是bundleName值与编译的bundleName值不一样导致的,直接在app.json5配置相同的属性值即可。
六、总结
总体体验下来感觉不是很难,比较适合前端开发的小伙伴,官方的文档比较大而全,对于初学者确实需要一些耐心去阅读。建议新来的小伙伴可以看一下官方的一些教学视频方便入门。初学者需要根据自身的兴趣爱好合理的使用对应领域的编程语言,掌握Deveco studio的环境搭建、快捷键使用技巧、远程及本地调试的方法、文档的查阅、ArkTS语言的使用、组件间传值、页面跳转与布局等相关的知识。HarmonyOS的元服务提供系统级别功能的服务,通过这些服务,应用程序可以获得设备级别的能力和资源。使用HarmonyOS的元服务需要先实例化对应的服务对象,然后通过该对象调用相应的方法。可以通过ElementName类来指定要调用的服务和服务所在的设备。例如,要调用设备的位置服务,可以使用Location服务:Location location = new Location(context, new ElementName("", "system"));一些元服务可能需要特定的权限才能使用。在请求使用元服务之前,应用程序需要在清单文件中声明相应的权限,并在运行时请求用户授权。可以使用AbilityShell的requestPermissions()方法请求权限。元服务的生命周期与应用程序的生命周期相互独立。当应用程序终止时,元服务仍然可以继续运行。因此,在使用元服务时,需要注意适当地管理其生命周期,避免资源浪费和不必要的运行。在使用元服务时,可能会遇到各种错误情况,如服务不可用、无权限访问等。为了保证应用程序的稳定性和可靠性,需要适当处理这些错误情况,并给用户提供相应的错误提示和解决方案。除了系统提供的元服务,开发者还可以通过HarmonyOS的分布式能力框架来实现自定义的元服务。通过扩展元服务,开发者可以实现更丰富的功能和服务,以满足不同应用的需求。总而言之,HarmonyOS的元服务为应用程序提供了与设备级别功能交互的能力,开发者可以根据需求调用相应的元服务,并适当管理其生命周期和处理错误情况,以提高应用程序的性能和用户体验。
参考文档
元服务介绍:https://developer.huawei.com/consumer/cn/harmonyos/fa
ArkTS语言介绍:https://developer.harmonyos.com/cn/develop/arkts/
端云一体化开发介绍:https://developer.harmonyos.com/cn/docs/documentation/doc-guides-V3/agc-harmonyos-clouddev-overview-0000001443209792-V3
低代码开发介绍:https://developer.harmonyos.com/cn/docs/documentation/doc-guides-V3/ide-low-code-overview-0000001480179573-V3
官方视频:https://developer.huawei.com/consumer/cn/training/study-path/101667550095504391