智能建站做网站好吗国外个人网站
文章目录
- 前文提要
- 代码需求描述
- 插值语法实现
- methods实现
- 计算属性
- getter执行时间:
- setter
- 计算属性简写形式(只读不改,才能如此简写)
- slice截取元素,限制输入字符数量
前文提要
本人仅做个人学习记录,如有错误,请多包涵
代码需求描述
输入姓和名,能够将二者结合起来输出,姓和名之间使用’-'符号分隔
插值语法实现
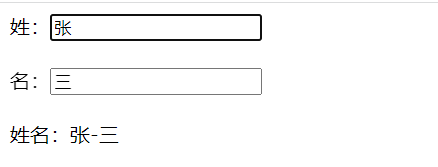
<body><div id="box">姓:<input type="text" placeholder="姓" v-model:value="firstName"><br/><br/>名:<input type="text" placeholder="名" v-model:value="secondName"><br/><br/>姓名:{{firstName}}-{{secondName}}</div><script type="text/javascript">Vue.config.productionTip = falseconst vm = new Vue({el: '#box',data: {firstName:'张',secondName:'三',}})</script>
</body>
其中v-model:value=可以简写为v-model=,也就是’:value’可以省略掉
实现效果如下:

methods实现
代码如下:
<body><div id="box">姓:<input type="text" placeholder="姓" v-model:value="firstName"><br /><br />名:<input type="text" placeholder="名" v-model:value="secondName"><br /><br />姓名:{{name()}}<br /><br />测试:<input type="text" placeholder="测试" v-model:value="nn"><br /><br /></div><script type="text/javascript">Vue.config.productionTip = falseconst vm = new Vue({el: '#box',data: {firstName: '张',secondName: '三',nn:'yi'},methods: {name(){console.log(1)return this.firstName+'-'+this.secondName}}})</script>
</body>
methods中的函数会被添加到Vue实例中,因此可以直接在插值语法中调用。
data中的任何数据发生变化的时候,Vue的模版都会被重新解析,模版中含有methods中的name函数,methods不管函数返回值有没有变化,都会调用一次函数,因此会多次调用name函数。
所以每次查看和修改姓和名,都会调用一次该函数。
method中的函数,没有写成箭头函数,则可以从this指针这里访问Vue实例,Vue实例中因为数据代理添加了data中的数据,因此可以如此写。
呈现效果:


每在名中添加、删除一次字符,都会调用一次函数,在控制台输出一次1。
就算修改的不是和函数返回值有关的属性,也会调用函数

计算属性
将上文的代码修改为这样,使用计算属性computed也可以起到上文的效果,而且效率更高。
<body><div id="box">姓:<input type="text" placeholder="姓" v-model:value="firstName"><br /><br />名:<input type="text" placeholder="名" v-model:value="secondName"><br /><br />姓名:{{name_}}<br /><br />测试:<input type="text" placeholder="测试" v-model:value="nn"><br /><br /></div><script type="text/javascript">Vue.config.productionTip = falseconst vm = new Vue({el: '#box',data: {firstName: '张',secondName: '三',nn:"yi"},methods: {name(){return this.firstName+'-'+this.secondName}},computed:{name_:{get(){console.log('调用了get')return this.firstName+'-'+this.secondName},set(value){console.log('调用了set')const arr=value.split('-')this.firstName=arr[0]this.secondName=arr[1]}}}})</script>
</body>
呈现效果:

代码解释:
computed中的属性不能和methods中的函数名一致,会出错。
set函数中无法直接通过firstName访问到data中的firstName,必须通过this指针锁定Vue实例,再进一步锁定firstName
计算属性中的属性是不存在的,是使用其他的属性计算出来的,这也是为什么叫做计算属性的原因。
原理:底层借助了Object.defineproperty提供的getter和setter。
getter执行时间:
(1)初次读取时,会执行一次。
(2)当依赖的数据被改变时会再次调用。
注意点:不要使用vm.data_.get()调用函数,这是错误的
和methods方法不同,当返回的数据没有发生变化的时候,methods是会继续执行一遍了,而computed内部含有缓存机制(复用),当没有触发get函数执行的时候,有用到该计算属性的时候,会直接从缓存中提取,效率更高,调试更加方便。
示例图片:

当你修改的属性,和计算属性中包含的属性全无关系的时候,就算整个模版被重新解析,methods中的函数重新执行,computed中的计算属性也只会执行最开始的那次(因为相关data属性没有发生变化)
setter

当你对计算属性进行更改的时候,会调用setter,而和计算属性有关的属性发生变化的时候,会触发调用get函数,因此控制台会如此输出
计算属性简写形式(只读不改,才能如此简写)
当你规定的计算属性只读不写,则可以通过修改上文代码,写成这样应用:
computed:{name_:function(){console.log('调用了get')return this.firstName+'-'+this.secondName}
}
注意:要求只读不写,别修改计算属性。
不过这还不是最简形式,还可以进一步简化:
computed:{name_(){console.log('调用了get')return this.firstName+'-'+this.secondName}
}
注意name_不是函数,依旧是属性。
slice截取元素,限制输入字符数量
可以将getter中的代码改为下述样式:
return this.firstName.slice(0,3)+'-'+this.secondName
从而限制字符个数,最少为0,最多3个
示例图片:

超过3个字符的无法记录到计算属性中。
至此,结束。
如果你觉得这篇文章写的不错,多多点赞~收藏吧!