沈阳市建设工程质量检测中心网站如何制作微信小程序店铺
windows 10 系统 vs code 编译运行和调试 C/C++_vscode windows编译_雪的期许的博客-CSDN博客
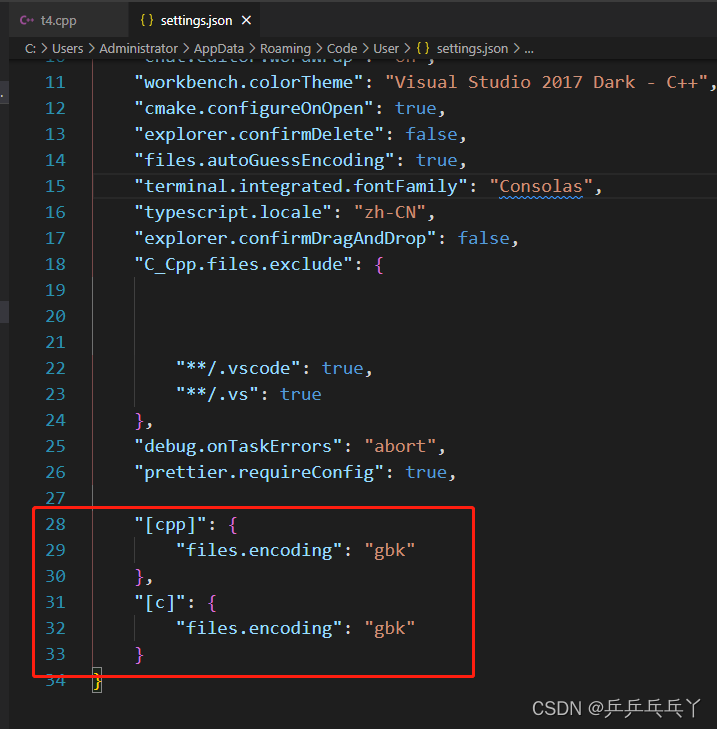
VS Code默认文件编码时UTF-8,这对大多数情况是没有问题的,却偏偏对C/C++有问题。如果以UTF-8编码保存C/C++代码,那么只能输出英文,另外使用不同的编辑器打开改代码时,中文注释也可能会乱码。
解决方法:ctrl+p ——> 搜 settings.json

windows 10 系统 vs code 编译运行和调试 C/C++_vscode windows编译_雪的期许的博客-CSDN博客
VS Code默认文件编码时UTF-8,这对大多数情况是没有问题的,却偏偏对C/C++有问题。如果以UTF-8编码保存C/C++代码,那么只能输出英文,另外使用不同的编辑器打开改代码时,中文注释也可能会乱码。
解决方法:ctrl+p ——> 搜 settings.json