外贸网站建站方案外卖网站建设
目录
什么是位段?
位段的内存分配
位段的跨平台问题
什么是位段?
位段的声明与结构是类似的,但是有两个不同:
- 位段的成员必须是 int、unsigned int 或signed int 等整型家族。
- 位段的成员名后边有一个冒号和一个数字
这是一个结构体
struct S
{int a;int b;int c;int d;
};这是一个位段
struct A
{int a : 2;int b : 5;int c : 10;int d : 30;
};位段的样子看起来奇奇怪怪的,那个冒号和后面的数字是什么意思呢?
位段位段,它名字里的“位”就是二进制位。
冒号和后面的数字其实是它的成员变量在告诉编译器:
- 成员a:我只需要2个比特的空间足以!
- 成员b:请给我分配5个比特的空间吧!
- 成员c:给我来10个!
- 成员d:我需要的空间大,给我来40个比特的空间吧!
每个成员都得到了自己想要的大小的空间,那么位段A的总大小是多少呢?
我们用sizeof来计算一下:
#include<stdio.h>struct S
{int a;int b;int c;int d;
};struct A
{int a : 2;int b : 5;int c : 10;int d : 30;
};int main()
{printf("结构体S的大小为: %d字节\n", sizeof(struct S));printf("位段A的大小为: %d字节\n", sizeof(struct A));return 0;
}
学完上一章之后,我们很轻松的计算出结构体S的大小4*4=16字节与结果一致。
再看位段,把成员们所需要的空间大小加起来2+5+10+30=47比特。
已知1字节=8比特。换算一下位段A的总大小应该是6字节就够了,可结果却是8字节。
位段的内存分配
位段的成员可以是 int unsigned int signed int 或者是 char (属于 整形家族 )类型。
位段的空间上是按照需要以4个字节( int )或者1个字节( char )的方式来开辟的。
位段涉及很多不确定因素,位段是不跨平台的,注重 可移植的程序应该避免使用位段 。
首先声明:位段有很多用法是标准未定义的,也就是说不同的机器上或者不同的编译器上内存如何
分配都有所差异,所以一下内容中有关内存分配的插图并不是严格正确的!!!
举个例子:
这是一个成员是int类型的位段:
struct A
{int a : 2;int b : 5;int c : 10;int d : 30;
};
这是一个成员是char类型的位段:
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};
现在假定义一个位段的变量并进行初始化:
struct S
{char a : 3;char b : 4;char c : 5;char d : 4;
};
struct S s = { 0 };
s.a = 10;
s.b = 12;
s.c = 3;
s.d = 4;其在VS2013环境下是这样进行存储数据的:
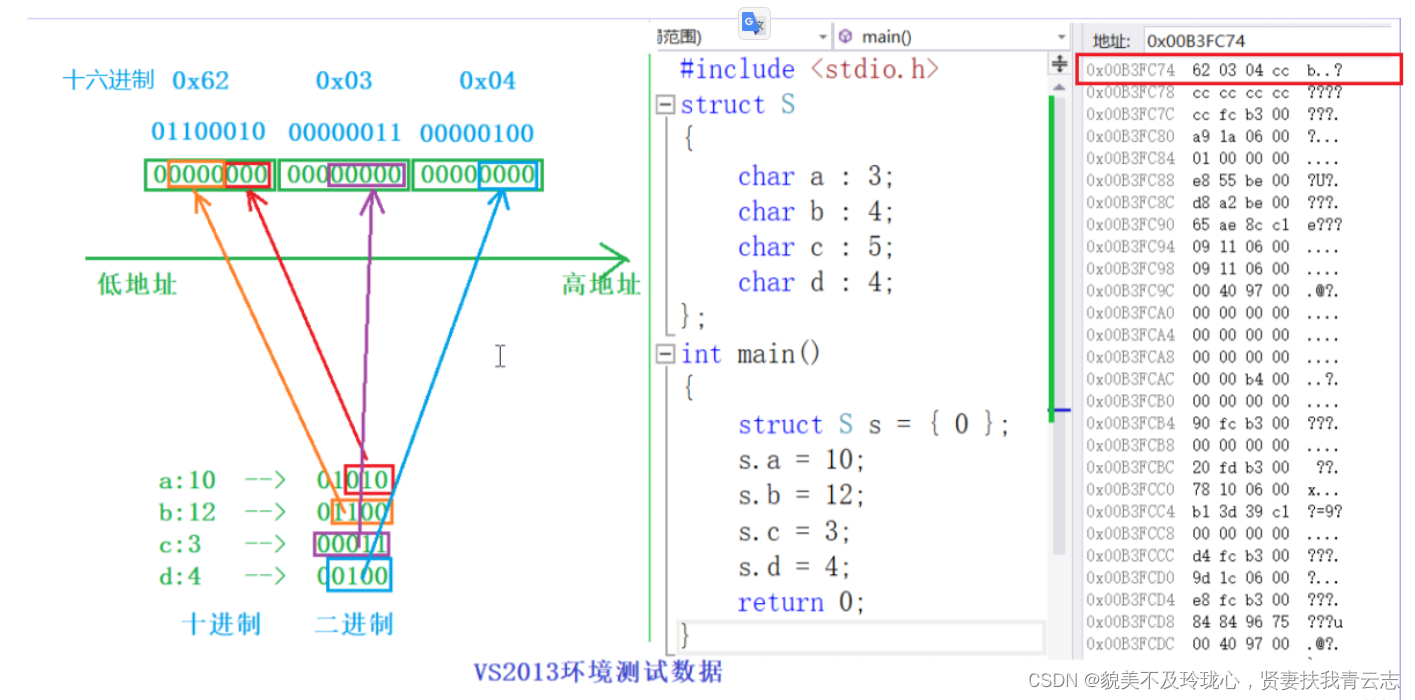
说明:数据是以二进制的方式进行存储的。
再次强调:以上的存储形式仅仅是vs2013环境下的,每种不同的编译器在不同的环境下都有自己存储的方式 。
位段的跨平台问题
问题一:int 位段被当成有符号数还是无符号数是不确定的。
说明:例如一个整型存储的时候,它的最高位是有符号位还是无符号位是有明确的规定的,而位段标准并没有规定。有的平台会当作有符号数处理,有的反之。
问题二:位段中最大位的数目不能确定。
说明:16位机器最大16,32位机器最大32,写成27,在16位机器会出问题。
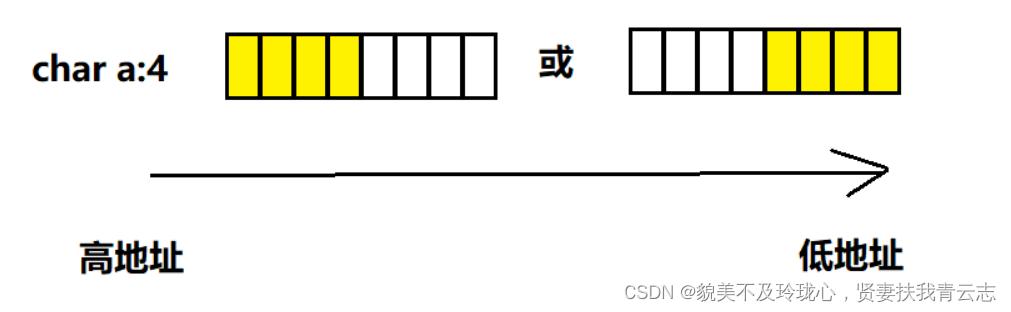
问题三:位段中的成员在内存中从左向右分配,还是从右向左分配标准尚未定义。
说明:
问题四:当一个结构包含两个位段,第二个位段成员比较大,无法容纳于第一个位段剩余的位时,是舍弃剩余的位还是利用,这是不确定的。
说明:

总结:跟结构相比,位段可以达到同样的效果,但是可以很好的节省空间,但是有跨平台的问题存在。