北京做养生SPA的网站建设手机微信可以做网站吗
highlight: arduino-light
合理管理 Netty 堆外内存
内存使用目标
•内存占用少(空间) •应用速度快(时间)
即多快好省
对 Java 而言:减少 Full GC 的 STW(Stop the world)时间
内存使用技巧
• 减少对象本身大小
md 例 1:用基本类型就不要用包装类。 例 2: 应该定义成类变量(静态变量)的不要定义为实例变量。 •一个类 -> 一个类变量 •一个实例 -> 一个实例变量 •一个类 -> 多个实例 •实例越多,浪费越多。
例 3: Netty 中结合前两者:

io.netty.channel.ChannelOutboundBuffer#incrementPendingOutboundBytes(long, boolean)统计待写的请求的字节数
AtomicLong -> volatile long + static AtomicLongFieldUpdater
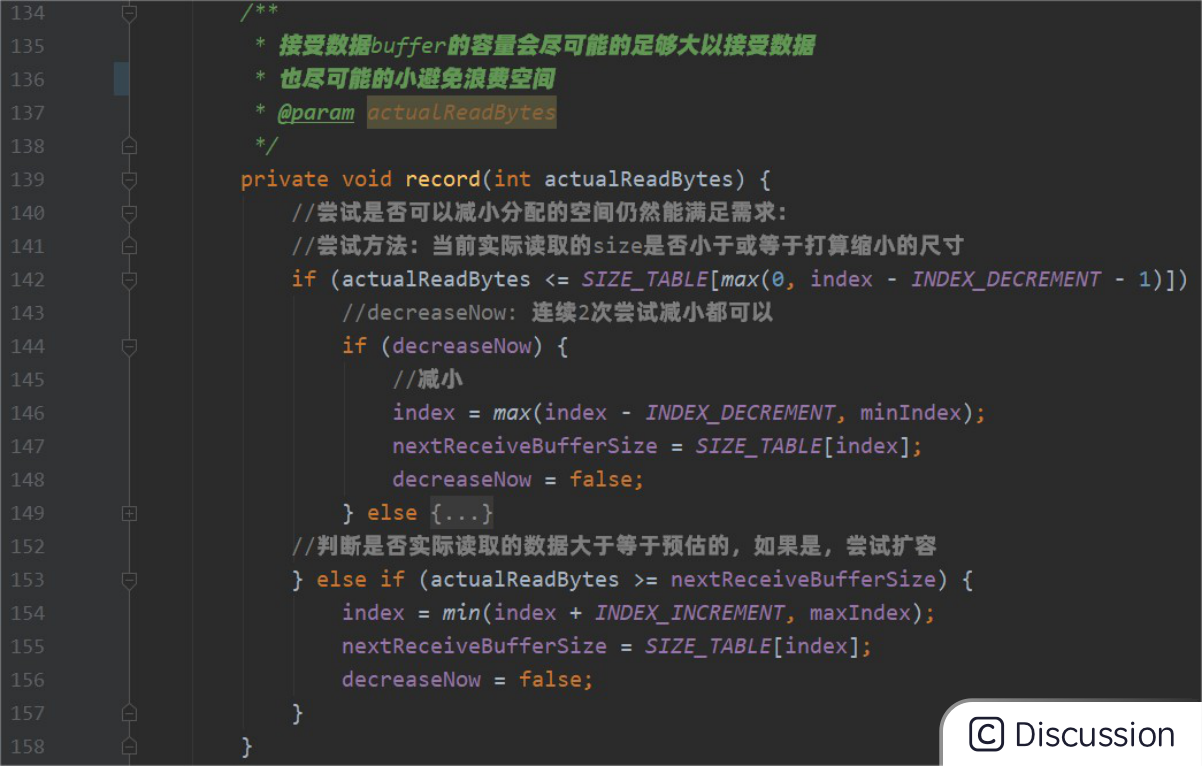
•对分配内存进行预估
例 1:对于已经可以预知固定 size 的 HashMap避免扩容可以提前计算好初始size或者直接使用
com.google.common.collect.Maps#newHashMapWithExpectedSize
例2:Netty 根据接收到的数据动态调整(guess)下个要分配的 Buffer 的大小。可参考io.netty.channel.AdaptiveRecvByteBufAllocator
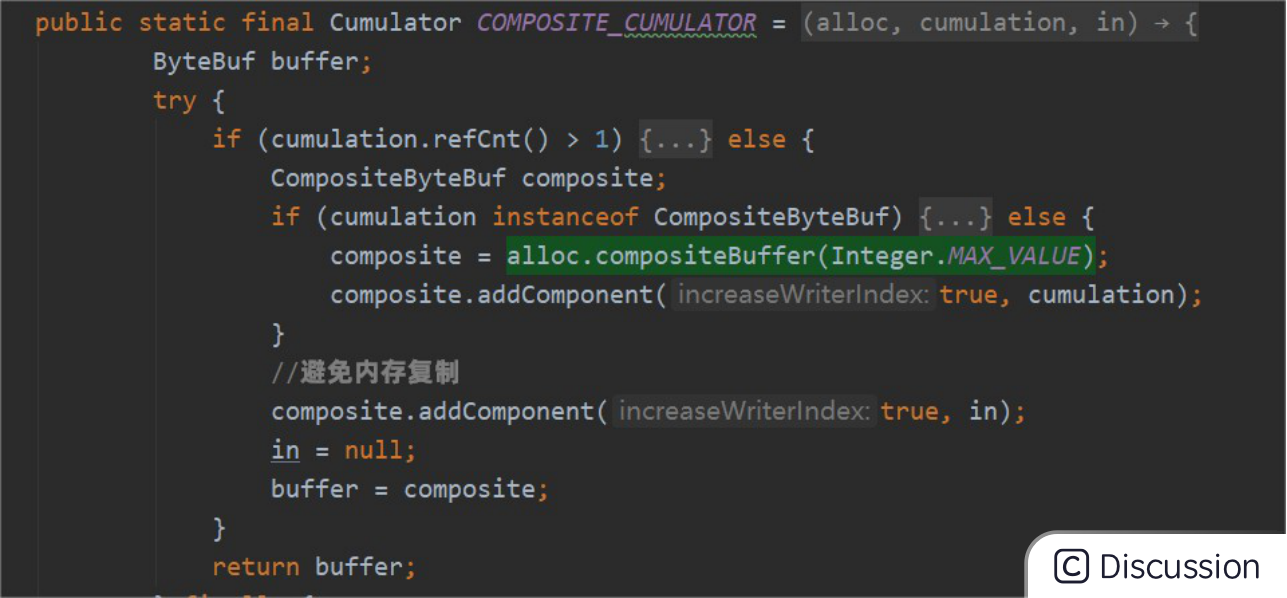
• 零拷贝
使用逻辑组合代替实际复制
例如 CompositeByteBuf: io.netty.handler.codec.ByteToMessageDecoder#COMPOSITE_CUMULATOR
使用包装,代替实际复制
byte[] bytes = data.getBytes(); ByteBuf byteBuf = Unpooled.wrappedBuffer(bytes);
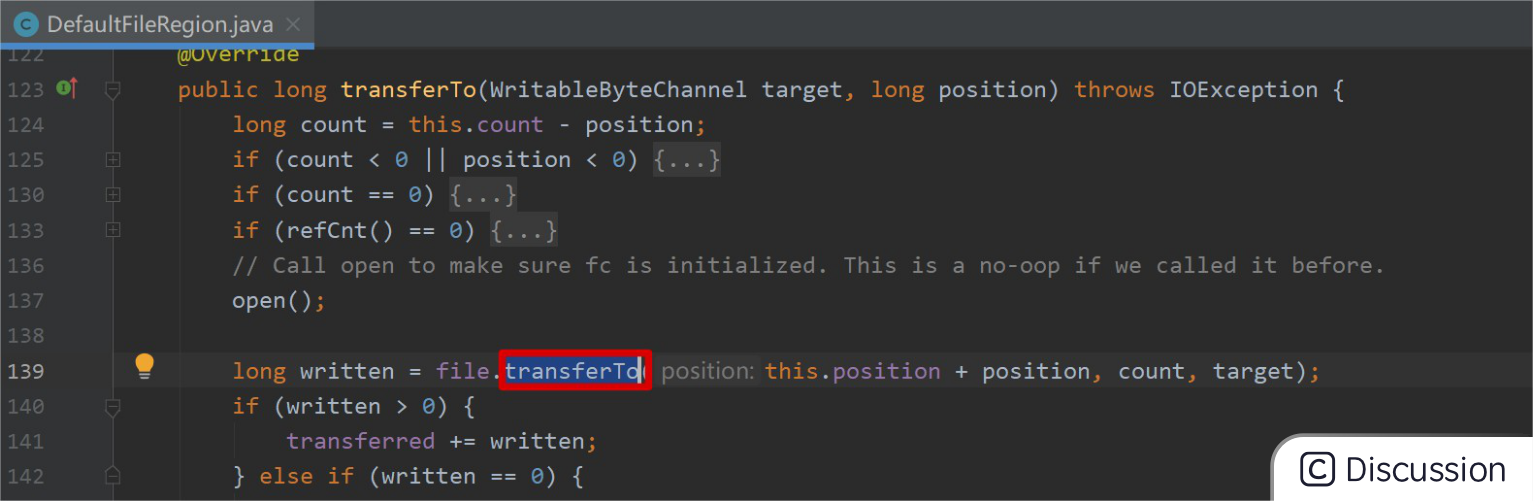
transferTo/transferFrom
Netty 中也通过在 DefaultFileRegion 中包装了 NIO 的 FileChannel.transferTo() 方法实现了零拷贝:io.netty.channel.DefaultFileRegion#transferTo
•堆外内存
堆外内存生活场景: 夏日,小区周边的烧烤店铺,人满为患坐不下,店家常常怎么办? 解决思路:店铺门口摆很多桌子招待客人。 •店内 -> JVM 内部 -> 堆(heap) + 非堆(non heap) •店外 -> JVM 外部 -> 堆外(off heap) 优点: •更广阔的“空间 ”,缓解店铺内压力 -> 破除堆空间限制,减轻 GC 压力 •减少“冗余”细节(假设烧烤过程为了气氛在室外进行:烤好直接上桌:vs 烤好还要进店内)-> 避免复制 缺点: •需要搬桌子 -> 创建速度稍慢 •受城管管、风险大 -> 堆外内存受操作系统管理
•内存池
内存池生活场景:点菜单的演进 •一张纸:一桌客人一张纸 •点菜平板:循环使用 为什么引入对象池: •创建对象开销大 •对象高频率创建且可复用 •支持并发又能保护系统 •维护、共享有限的资源 如何实现对象池? •开源实现:Apache Commons Pool •Netty 轻量级对象池实现 io.netty.util.Recycler
本节课我们将进入 Netty 内存管理的课程学习,在此之前,我们需要了解 Java 堆外内存的基本知识,因为当你在使用 Netty 时,需要时刻与堆外内存打交道。我们经常看到各类堆外内存泄漏的排查案例,堆外内存使用不当会使得应用出错、崩溃的概率变大,所以在使用堆外内存时一定要慎重,本节课我将带你一起认识堆外内存,并探讨如何更好地使用它。
如何实现内存池
java 如何实现对象池? •开源实现:Apache Commons Pool •Netty 轻量级对象池实现 io.netty.util.Recycler final class PooledDirectByteBuf extends PooledByteBuf<ByteBuffer> { private static final Recycler<PooledDirectByteBuf> RECYCLER = new Recycler<PooledDirectByteBuf>() { @Override protected PooledDirectByteBuf newObject(Handle<PooledDirectByteBuf> handle) { return new PooledDirectByteBuf(handle, 0); } }; //从“池”里借一个用 static PooledDirectByteBuf newInstance(int maxCapacity) { PooledDirectByteBuf buf = RECYCLER.get(); buf.reuse(maxCapacity); return buf; } } abstract class PooledByteBuf<T> extends AbstractReferenceCountedByteBuf { //归还对象到“池”里去,pipeline的tail会调用 //该方法继承自PooledByteBuf类 @Override protected final void deallocate() { if (handle >= 0) { final long handle = this.handle; this.handle = -1; memory = null; chunk.arena.free(chunk, tmpNioBuf, handle, maxLength, cache); tmpNioBuf = null; chunk = null; recycle(); } } } 其实最后都调用了RECYLER的方法 public final T get() { if (maxCapacityPerThread == 0) { //表明没有开启池化 return newObject((Handle<T>) NOOP_HANDLE); } Stack<T> stack = threadLocal.get(); DefaultHandle<T> handle = stack.pop(); //试图从“池”中取出一个,没有就新建一个 if (handle == null) { handle = stack.newHandle(); handle.value = newObject(handle); } @Override public void recycle(Object object) { if (object != value) { throw new IllegalArgumentException("object does not belong to handle"); } Stack<?> stack = this.stack; if (lastRecycledId != recycleId || stack == null) { throw new IllegalStateException("recycled already"); } //释放用完的对象到池里面去 stack.push(this); }
• 怎么从堆外内存切换堆内使用?以UnpooledByteBufAllocator为例
```java .childOption(ChannelOption.ALLOCATOR,new PooledByteBufAllocator(false)) .childOption(ChannelOption.ALLOCATOR,new UnpooledByteBufAllocator(false)) Netty参数,ByteBuf的分配器(重用缓冲区),默认值为ByteBufAllocator.DEFAULT,4.0版本为UnpooledByteBufAllocator,4.1版本为PooledByteBufAllocator。该值也可以使用系统参数io.netty.allocator.type配置,使用字符串值:“unpooled”,“pooled”。 额外解释, Netty4.1使用对象池,重用缓冲区(可以直接只用这个配置) bootstrap.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT); bootstrap.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
参考链接:https://blog.csdn.net/zhongzunfa/article/details/94590670 ```
为什么需要堆外内存
在 Java 中对象都是在堆内分配的,通常我们说的JVM 内存也就指的堆内内存,堆内内存完全被JVM 虚拟机所管理,JVM 有自己的垃圾回收算法,对于使用者来说不必关心对象的内存如何回收。
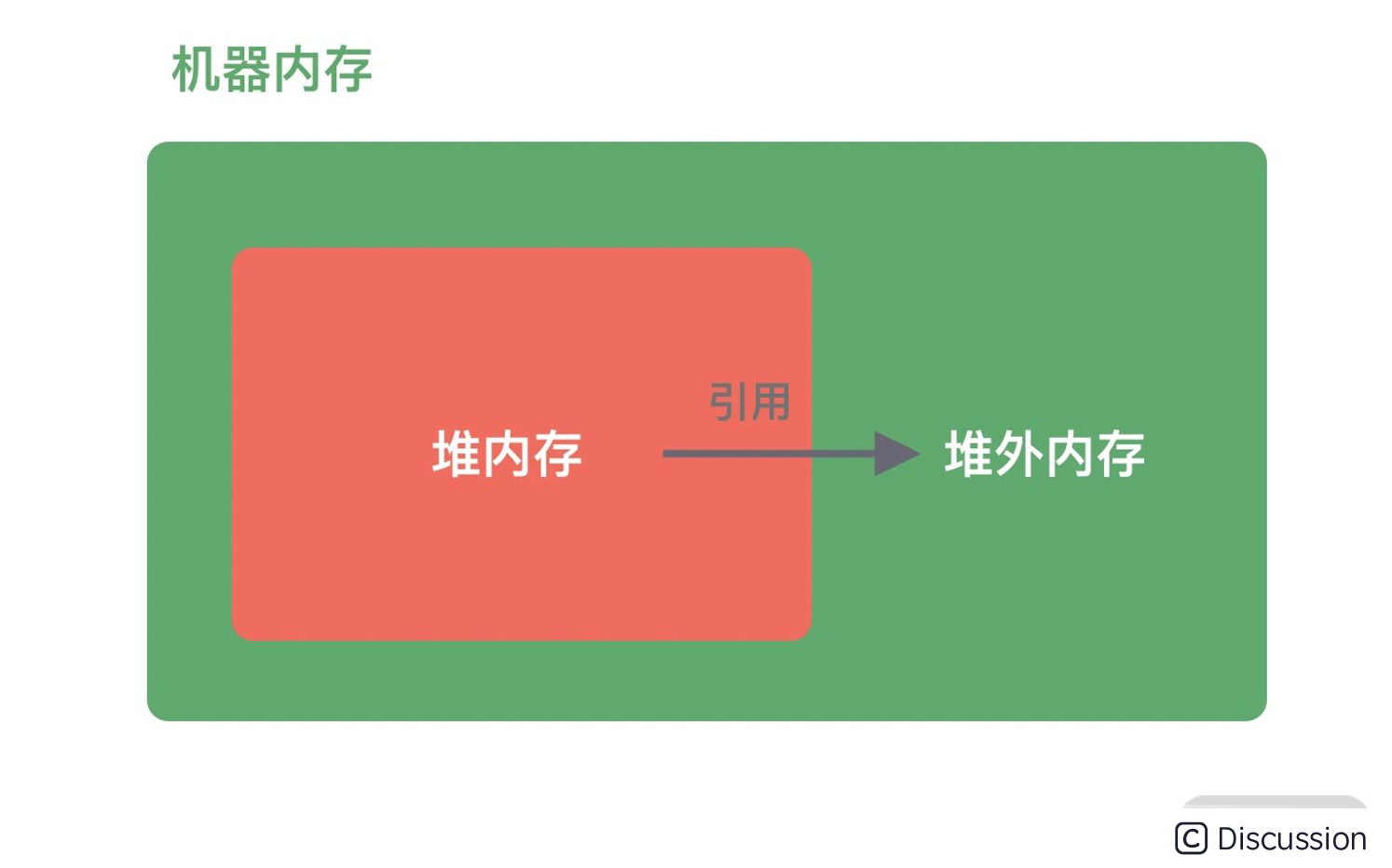
堆外内存与堆内内存相对应,对于整个机器内存而言,除堆内内存以外部分即为堆外内存,如下图所示。堆外内存不受 JVM 虚拟机管理,直接由操作系统管理。
堆外内存和堆内内存各有利弊,这里我针对其中重要的几点进行说明。
- 堆内内存由 JVM GC 自动回收内存,降低了 Java 用户的使用心智,但是 GC 是需要时间开销成本的,堆外内存由于不受 JVM 管理,所以在一定程度上可以降低 GC 对应用运行时带来的影响。
- 堆外内存需要手动释放,这一点跟 C/C++ 很像,稍有不慎就会造成应用程序内存泄漏,当出现内存泄漏问题时排查起来会相对困难。
- 当进行网络 I/O 操作、文件读写时,堆内内存都需要转换为堆外内存,然后再与底层设备进行交互,这一点在介绍 writeAndFlush 的工作原理中也有提到,所以直接使用堆外内存可以减少一次内存拷贝。
- 堆外内存可以实现进程之间、JVM 多实例之间的数据共享。
由此可以看出,如果你想实现高效的 I/O 操作、缓存常用的对象、降低 JVM GC 压力,堆外内存是一个非常不错的选择。
ByteBuf分配直接内存
java // 未池化堆内存 ByteBuf heapByteBuf = Unpooled.buffer(10); // 未池化直接内存 ByteBuf directByteBuf = Unpooled.directBuffer(10); // 池化堆内存 PooledByteBufAllocator allocator = new PooledByteBufAllocator(false); ByteBuf pHeapByteBuf = allocator.buffer(); // 池化直接内存 PooledByteBufAllocator allocator2 = new PooledByteBufAllocator(true);
堆外内存的分配
ByteBuffer#allocateDirect
不要手动释放
首先我们介绍下 Java NIO 包中的 ByteBuffer 类的分配方式,使用方式如下:
java // 分配 10M 堆外内存 ByteBuffer buffer = ByteBuffer.allocateDirect(10 * 1024 * 1024);
跟进 ByteBuffer.allocateDirect 源码,发现其中直接调用的 DirectByteBuffer 构造函数:
java DirectByteBuffer(int cap) { super(-1, 0, cap, cap); boolean pa = VM.isDirectMemoryPageAligned(); int ps = Bits.pageSize(); long size = Math.max(1L, (long)cap + (pa ? ps : 0)); Bits.reserveMemory(size, cap); long base = 0; try { base = unsafe.allocateMemory(size); } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte) 0); if (pa && (base % ps != 0)) { address = base + ps - (base & (ps - 1)); } else { address = base; } //public class Cleaner extends PhantomReference<Object> //注意create是静态方法,Cleaner中内部维护了1个queue //属性:static final ReferenceQueue<Object> dummyQueue = new ReferenceQueue(); //通过ByteBuffer.allocateDirect分配的ByteBuffer对象被回收时 //Cleaner就会用于回收对应的堆外内存 cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); att = null; }
如下图所示,描述了 DirectByteBuffer 的内存引用情况,方便你更好地理解上述源码的初始化过程。
在堆内存放的 DirectByteBuffer 对象并不大,仅仅包含堆外内存的地址、大小等属性,同时还会创建对应的 Cleaner 对象,通过 ByteBuffer 分配的堆外内存不需要手动回收,它可以被 JVM 自动回收。当堆内的 DirectByteBuffer 对象被 GC 回收时,Cleaner 就会用于回收对应的堆外内存。
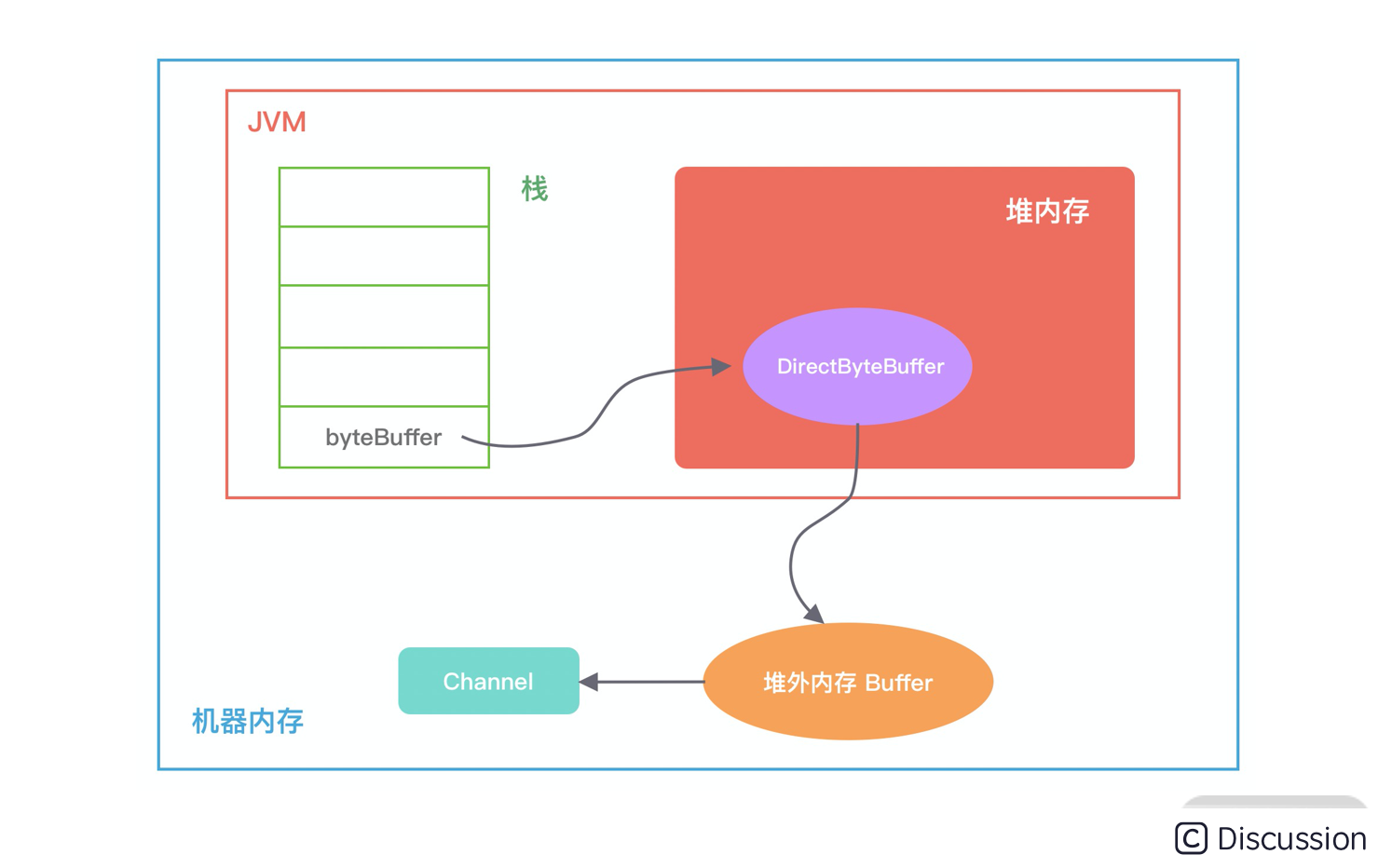
从 DirectByteBuffer 的构造函数中可以看出,真正分配堆外内存的逻辑还是通过 unsafe.allocateMemory(size), 接下来我们一起认识下 Unsafe 这个神秘的工具类。
Unsafe.allocateMemory
需手动释放
在 Java 中是不能直接使用 Unsafe 的,但是我们可以通过反射获取 Unsafe 实例,使用方式如下所示。
java private static Unsafe unsafe = null; static { try { Field getUnsafe = Unsafe.class.getDeclaredField("theUnsafe"); getUnsafe.setAccessible(true); unsafe = (Unsafe) getUnsafe.get(null); } catch (NoSuchFieldException | IllegalAccessException e) { e.printStackTrace(); } }
获得 Unsafe 实例后,我们可以通过 allocateMemory 方法分配堆外内存,allocateMemory 方法返回的是内存地址,使用方法如下所示:
java // 分配 10M 堆外内存 long address = unsafe.allocateMemory(10 * 1024 * 1024);
ByteBuffer.allocateDirect(int size)不需要手动释放。
Unsafe#allocateMemory 所分配的内存必须自己手动释放。
否则会造成内存泄漏,这也是 Unsafe 不安全的体现。
Unsafe 同样提供了内存释放的操作:
java unsafe.freeMemory(address);
ByteBuffer.allocateDirect回收
我们试想这么一种场景,因为 DirectByteBuffer 对象有可能长时间存在于堆内内存,所以它很可能晋升到 JVM 的老年代,所以这时候 DirectByteBuffer 对象的回收需要依赖 Old GC 或者 Full GC 才能触发清理。
如果长时间没有 Old GC 或者 Full GC 执行,那么堆外内存即使不再使用,也会一直在占用内存不释放,很容易将机器的物理内存耗尽,这是相当危险的。
此外在 ByteBuffer.allocateDirect 分配的过程中,如果没有足够的空间分配堆外内存,在 Bits.reserveMemory 方法中也会主动调用 System.gc() 强制执行 Full GC,但是在生产环境一般都是设置了 -XX:+DisableExplicitGC,System.gc() 是不起作用的,所以依赖 System.gc() 并不是一个好办法。
避免耗尽内存:指定堆外内存上限
那么在使用 DirectByteBuffer 时我们如何避免物理内存被耗尽呢?
因为 JVM 并不知道堆外内存是不是已经不足了,所以我们最好通过 JVM 参数 -XX:MaxDirectMemorySize 指定堆外内存的上限大小,当堆外内存的大小超过该阈值时,就会触发一次 Full GC 进行清理回收,如果在 Full GC 之后还是无法满足堆外内存的分配,那么程序将会抛出 OOM 异常。
堆外内存回收机制
通过前面堆外内存分配方式的介绍,我们知道 DirectByteBuffer 在初始化时会创建一个 Cleaner 对象,它会负责堆外内存的回收工作,那么 Cleaner 是如何与 GC 关联起来的呢?
Java 对象有四种引用方式:
强引用 StrongReference、软引用 SoftReference、 弱引用 WeakReference、虚引用 PhantomReference。
其中 PhantomReference 是最不常用的一种引用方式,Cleaner 就属于 PhantomReference 的子类。
如以下源码所示,PhantomReference 不能被单独使用,需要与引用队列 ReferenceQueue 联合使用。
java public static ByteBuffer allocateDirect(int capacity) { return new DirectByteBuffer(capacity); }
在DirectByteBuffer的构造方法中会构建1个Cleaner对象。
java DirectByteBuffer(int cap) { super(-1, 0, cap, cap); boolean pa = VM.isDirectMemoryPageAligned(); int ps = Bits.pageSize(); long size = Math.max(1L, (long)cap + (pa ? ps : 0)); Bits.reserveMemory(size, cap); long base = 0; try { base = unsafe.allocateMemory(size); } catch (OutOfMemoryError x) { Bits.unreserveMemory(size, cap); throw x; } unsafe.setMemory(base, size, (byte) 0); if (pa && (base % ps != 0)) { // Round up to page boundary address = base + ps - (base & (ps - 1)); } else { address = base; } //创建Cleaner //参数1:DirectByteBuffer //参数2:Deallocator cleaner = Cleaner.create(this, new Deallocator(base, size, cap)); att = null; }
Cleaner继承自PhantomReference,内部维护了全局的队列和链表。
java //注意是static全局的 private static final ReferenceQueue<Object> dummyQueue = new ReferenceQueue(); //注意是static全局的,代表链表头 private static Cleaner first = null; private Cleaner next = null; private Cleaner prev = null;
Cleaner#create
java //var0参数:DirectByteBuffer //var1参数:Deallocator public static Cleaner create(Object var0, Runnable var1) { return var1 == null ? null : add(new Cleaner(var0, var1)); } //先看构造函数 //参数1:DirectByteBuffer //参数2:Deallocator //注意这个参数2 在释放内存的时候会用到哦 private Cleaner(Object var1, Runnable var2) { //注意父类是Reference super(var1, dummyQueue); this.thunk = var2; } //其实就是把DirectByteBuffer和ReferenceQueue作为参数封装到Reference //参数1:DirectByteBuffer //参数2:是Cleaner的全局属性ReferenceQueue Reference(T referent, ReferenceQueue<? super T> queue) { this.referent = referent; this.queue = (queue == null) ? ReferenceQueue.NULL : queue; } //然后把新创建的Cleaner放入Cleaner链表 private static synchronized Cleaner add(Cleaner var0) { if (first != null) { var0.next = first; first.prev = var0; } first = var0; return var0; }
JDK中使用DirectByteBuffer对象来表示堆外内存,每个DirectByteBuffer对象在初始化时,都会创建一个对用的Cleaner对象,这个Cleaner对象会在合适的时候执行unsafe.freeMemory(address),从而回收这块堆外内存。
当初始化一块堆外内存时,对象的引用关系如下:
首先我们看下,当初始化堆外内存时,内存中的对象引用情况如下图所示:
first 是 Cleaner 类中的静态变量,Cleaner 对象在初始化时会加入 Cleaner类的链表中。
DirectByteBuffer 对象包含堆外内存的地址、大小以及 Cleaner 对象的强引用。
DirectByteBuffer 被封装在ReferenceQueue 中。ReferenceQueue被封装在Cleaner中,Cleaner在队列中。
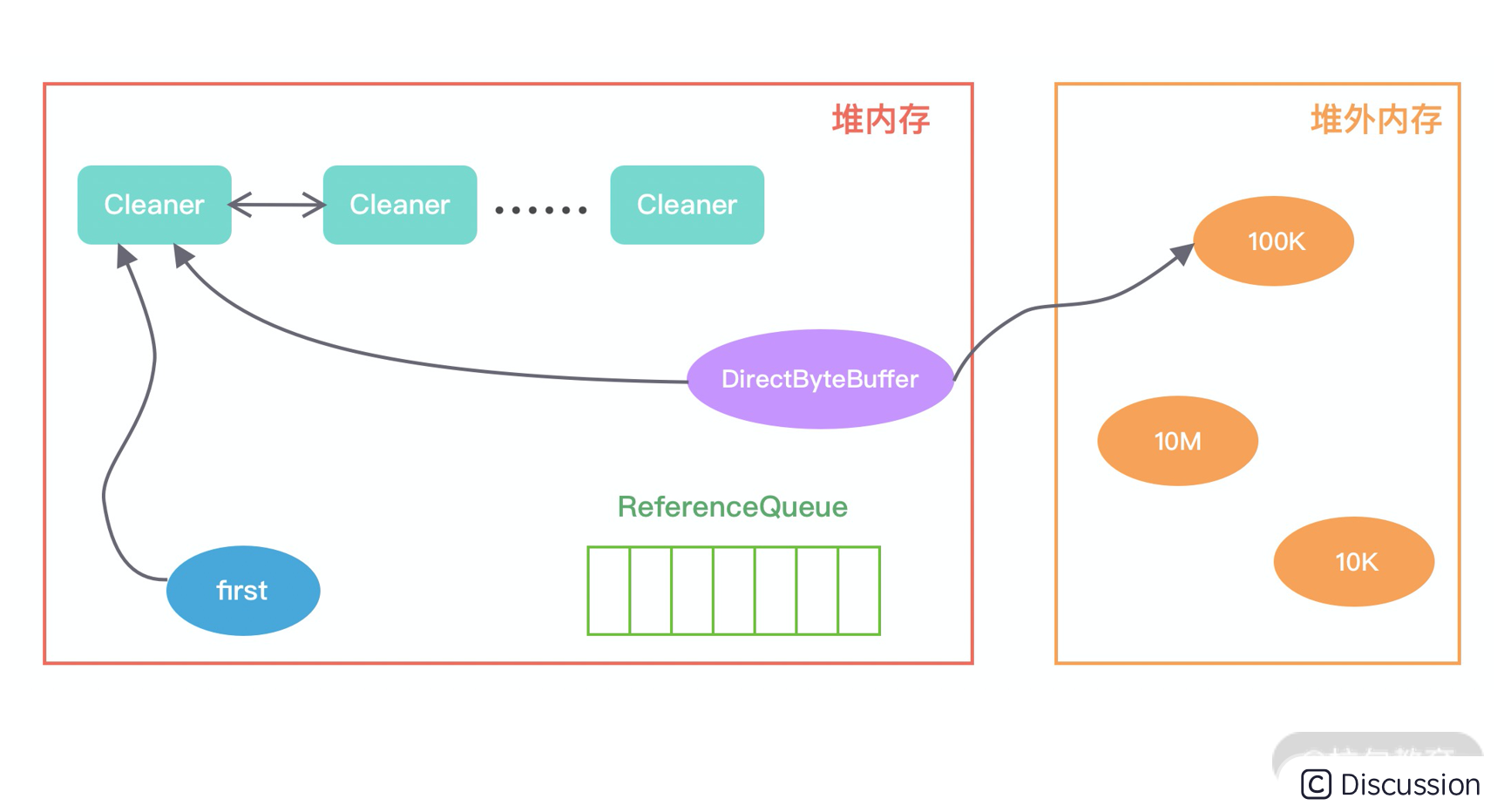
如果该DirectByteBuffer对象在一次GC中被回收了,DirectByteBuffer对象会被回收,但是堆外内存不会释放。
内存中的对象引用情况发生了如下变化:

Cleaner继承自PhantomReference。
此时Cleaner 对象不再有任何强引用关系,在下一次 GC 时:
该Cleaner对象就将被添加到ReferenceQueue 中,并执行 clean() 方法。
Cleaner继承自PhantomReference。
PhantomReference继承自Reference。
Reference中定义了1个clean方法。
在GC的过程中,以copy gc为例,所有存活的强引用都会被拷到新的survivor区域中,但是弱引用不会被拷贝。
同时会把WeakReference都使用它的discovered域串起来,在串的同时,把它的referent设置为 nul,如下图所示。

然后,在JVM中,会启动一个线程,叫做ReferenceHandler.
java static { ThreadGroup tg = Thread.currentThread().getThreadGroup(); for (ThreadGroup tgn = tg; tgn != null; tg = tgn, tgn = tg.getParent()); Thread handler = new ReferenceHandler(tg, "Reference Handler"); /* If there were a special system-only priority greater than * MAX_PRIORITY, it would be used here */ handler.setPriority(Thread.MAX_PRIORITY); handler.setDaemon(true); handler.start(); }
java.lang.ref.Reference.ReferenceHandler#run
java public void run() { for (;;) { Reference<Object> r; synchronized (lock) { if (pending != null) { r = pending; pending = r.discovered; r.discovered = null; } else { try { try { lock.wait(); } catch (OutOfMemoryError x) { } } catch (InterruptedException x) { } continue; } } // Fast path for cleaners if (r instanceof Cleaner) { //注意这里 ((Cleaner)r).clean(); continue; } ReferenceQueue<Object> q = r.queue; if (q != ReferenceQueue.NULL) q.enqueue(r); } } } clean() 方法主要做两件事情:
1.将Cleaner 对象从 Cleaner 链表中移除;
2.调用 unsafe.freeMemory 方法清理堆外内存。
java public void clean() { if (remove(this)) { try { this.thunk.run(); } catch (final Throwable var2) { AccessController.doPrivileged(new PrivilegedAction<Void>() { public Void run() { if (System.err != null) { (new Error("Cleaner非正常终止", var2)) .printStackTrace(); } System.exit(1); return null; } }); } } } //thunk是DirectByteBuffer.Deallocator //java.nio.DirectByteBuffer.Deallocator#Deallocator public void run() { if (address == 0) { // Paranoia return; } unsafe.freeMemory(address); address = 0; Bits.unreserveMemory(size, capacity); }
如果JVM一直没有执行FGC的话,无效的Cleaner对象就无法放入到ReferenceQueue中,从而堆外内存也一直得不到释放,内存岂不是会爆?
其实在DirectByteBuffer的构造方法中,在代码Bits.reserveMemory(size, cap)中,如果当前堆外内存的条件很苛刻时,会主动调用System.gc()强制执行FGC。

不过很多线上环境的JVM参数有-XX:+DisableExplicitGC,导致了System.gc()等于一个空函数,根本不会触发FGC,这一点在使用Netty框架时需要注意是否会出问题。
至此,堆外内存的回收已经介绍完了,下次再排查内存泄漏问题的时候先回顾下这些最基本的知识,做到心中有数。
强弱软虚
强引用
当我们使用 new 这个关键字创建对象时创建出来的对象就是强引用(new出来对象为强引用) 如Object obj = new Object() 这个obj就是一个强引用了,如果一个对象具有强引用。垃圾回收器就不会回收有强引用的对象。如当jvm内存不足时,具备强引用的对象,虚拟机宁可会抛出OutOfMemoryError(内存空间不足),使程序终止,也不会靠垃圾回收器去回收该对象来解决内存不足。
软引用-Soft
如果一个对象只具有软引用,那就类似于可有可物的生活用品。如果内存空间足够,垃圾回收器就不会回收它,如果内存空间不足了,就会回收这些对象的内存。只要垃圾回收器没有回收它,该对象就可以被程序使用。
软引用的作用:软引用可用来实现内存敏感的高速缓存。 软引用可以和一个引用队列(ReferenceQueue)联合使用,如果软引用所引用的对象被垃圾回收,Java虚拟机就会把这个软引用加入到与之关联的引用队列中。
弱引用-Weak-ThreadLocal
如果一个对象只具有弱引用,那就类似于可有可物的生活用品。弱引用与软引用的区别在于:只具有弱引用的对象拥有更短暂的生命周期。在垃圾回收器线程扫描它所管辖的内存区域的过程中,一旦发现了只具有弱引用的对象,不管当前内存空间足够与否,都会回收它的内存。不过,由于垃圾回收器是一个优先级很低的线程, 因此不一定会很快发现那些只具有弱引用的对象。 弱引用可以和一个引用队列(ReferenceQueue)联合使用,如果弱引用所引用的对象被垃圾回收,Java虚拟机就会把这个弱引用加入到与之关联的引用队列中。
弱引用简单来说就是将对象留在内存的能力不是那么强的引用。使用WeakReference,垃圾回收器会帮你来决定引用的对象何时回收并且将对象从内存移除。创建弱引用如下
WeakReference weakWidget = new WeakReference(widget);
使用weakWidget.get()就可以得到真实的Widget对象,因为弱引用不能阻挡垃圾回收器对其回收,你会发现(当没有任何强引用到widget对象时)使用get时突然返回null。
解决上述的widget序列数记录的问题,最简单的办法就是使用Java内置的WeakHashMap类。WeakHashMap和HashMap几乎一样,唯一的区别就是它的键(不是值!!!)使用WeakReference引用。当WeakHashMap的键标记为垃圾的时候,这个键对应的条目就会自动被移除。这就避免了上面不需要的Widget对象手动删除的问题。使用WeakHashMap可以很便捷地转为HashMap或者Map。
虚引用-Phantom-Cleaner
上面的直接内存用的就是虚引用
“虚引用”顾名思义,就是形同虚设,和其他几种引用都不同,虚引用并不会决定对象的生命周期。
如果一个对象仅持有虚引用,那么它就和没有任何引用一样,在任何时候都可能被垃圾回收器回收。
虚引用主要用来跟踪对象被垃圾回收器回收的活动。
虚引用与软引用和弱引用的一个区别在于:虚引用必须和引用队列(ReferenceQueue)联合使用。
当垃圾回收器准备回收一个对象时,如果发现它还有虚引用,就会在回收对象的内存之前,把这个虚引用加入到与之 关
联的引用队列中。
ReferenceQueue queue = new ReferenceQueue (); //虚引用对象
PhantomReference pr = new PhantomReference (object, queue);//程序可以通过判断引用队列中是否已经加入了虚引用,来了解被引用的对象是否将要被垃圾回收。
如果程序发现某个虚引用已经被加入到引用队列,那么就可以在所引用的对象的内存被回收之前采取必要的行动。 Jvm虚拟机专门的gc线程管理堆外内存

总结
堆外内存是一把双刃剑,在网络 I/O、文件读写、分布式缓存等领域使用堆外内存都更加简单、高效,此外使用堆外内存不受 JVM 约束,可以避免 JVM GC 的压力,降低对业务应用的影响。当然天下没有免费的午餐,堆外内存也不能滥用,使用堆外内存你就需要关注内存回收问题,虽然 JVM 在一定程度上帮助我们实现了堆外内存的自动回收,但我们仍然需要培养类似 C/C++ 的分配/回收的意识,出现内存泄漏问题能够知道如何分析和处理。
https://www.cnblogs.com/frankltf/p/12662401.html)