34线城市做网站推广优秀网站建设模版
目录
说明:
1. 工作空间(workspace) 结构:
2. 创建工作空间和功能包
创建工作空间
编译工作空间
创建功能包
设置环境变量
3. 注意
同一个工作空间下,不能存在同名的功能包;
不同工作空间下,可以存在同名的功能包。
说明:
1. 本系列学习笔记基于B站:古月居《ROS入门21讲》课程,且使用的Ubuntu与ROS系统版本与 课程完全一致;
| 虚拟机版本 | Linux系统版本 | ROS系统版本 |
|---|---|---|
| VMware WorkStation Pro 16 | Ubuntu18.04 | Melodic |
2. 本节是整个笔记的第7节,对应视频课程的第9节,请自行对应学习;
3. 整个系列笔记基本已经完结,但部分章节仍需润色修改 ,后面会陆续发布,请大家持续关注, 创作不易,感谢支持!
1. 工作空间(workspace) 结构:
存放工程开发相关文件的文件夹,包含以下4个主要文件夹:
1. src: 代码空间(Source Space),
用来放置功能包所有源码、配置文件、launch文件等;
2. build: 编译空间(Build Space),
用来放置编译过程中所产生的一些中间文件(二进制文件),基本用不到,不用操作;
3. devel: 开发空间(Development Space),
用来放置开发过程中编译生成的一些可执行文件、库、脚本,所以以后可能会查看里面的一些内容;
4. install:安装空间(Install Space),
通过install命令安装成功的一些东西,最终开发编译生成的可执行文件,都是在Install这个空间里;
(注意:devel 开发空间和 install 安装空间的功能类似,内容有一定程度的重复,install是开发完成后分享给客户使用的结果文件,但在ROS2里,对这一点做了修正,只保留了install 空间)
2. 创建工作空间和功能包
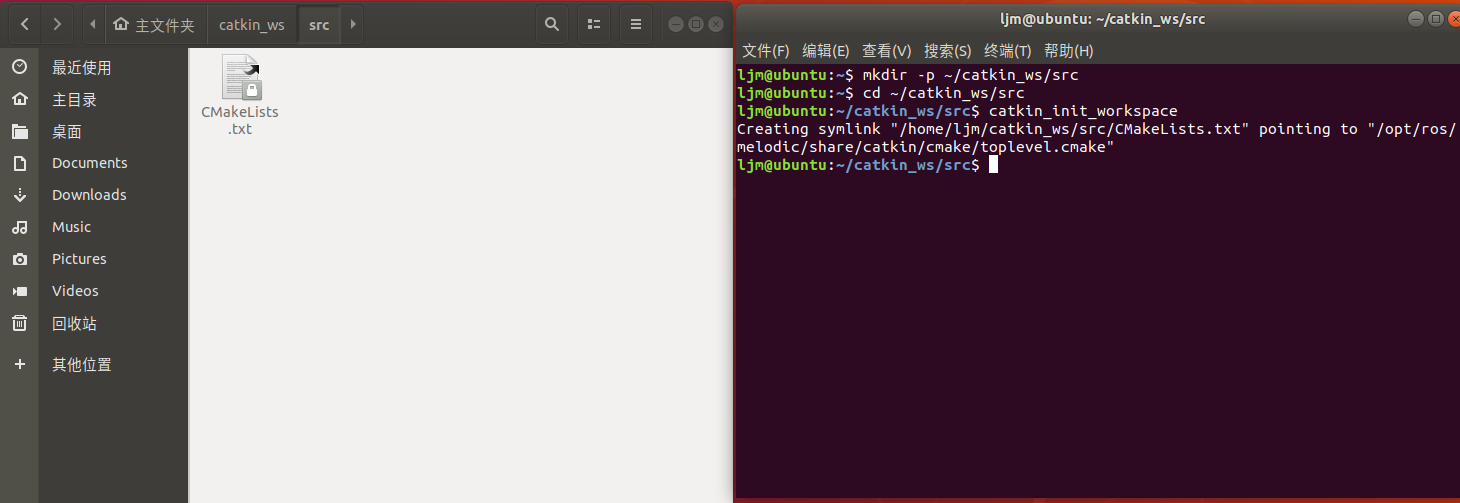
创建工作空间
mkdir -p ~/catkin_ws/src cd ~/catkin_ws/src catkin_init_workspace
-
-p:创建一个多级目录,若其父目录不存在,则系统会自动创建,而不是报错,比如,mkdir -p /home/a/b/c,如果没有a和b文件夹或者没有b文件夹,系统则会自动创建,并在b文件夹下创建c文件夹。
-
~:代表用户的home目录。
第(1)步:mkdir -p ~/catkin_ws/src,创建一个工作空间,
第(2)步: cd ~/catkin_ws/src, 切换到创建工作空间的src文件夹下,
第(3)步:catkin_init_workspace, 初始化当前文件夹,将创建的工作空间变成一个具有ROS属性的workspace,
这是一个属性的变化,然后会在catkin_ws/src下产生一个CMakeLists.txt文件,
代表初始化成功。
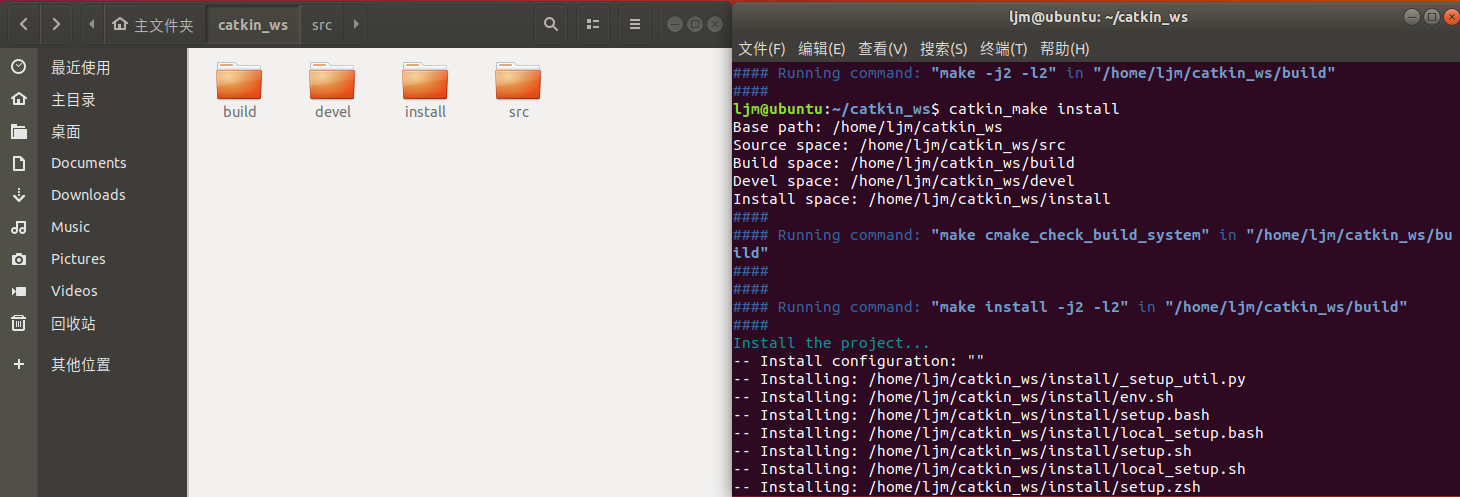
编译工作空间
cd ~/catkin_ws catkin_make catkin_make install
第(1)步:cd ~/catkin_ws, 先切换到catkin_ws功能空间根目录下,
第(2)步:catkin_make , 会在catkin_ws目录下生成,devel开发空间和build编译空间的文件夹,
第(3)步:catkin_make intsall, 产生install安装空间的文件;
-
注意:第二步catkin_make之后并不会在catkin_ws目录下生成Install安装空间的文件夹,install安装空间的文件夹需要再输入,catkin_make intsall命令
创建功能包
ROS里源码不可以直接放在工作空间下的src文件夹中直接编译,必须要创建功能包,因此功能包是ROS里源码的最小单元,
存放路径:home/catkin_ws/src
cd ~/catkin_ws/src catkin_create_pkg package_name 依赖1 依赖2 依赖3 cd ~/catkin_ws catkin_make
示例:
第(1)步:cd ~/catkin_ws/src, 先切换工作路径到catkin_ws/src目录下,
第(2)步:catkin_create_pkg test_pkg roscpp rospy std_msgs, 创建catkin_ws工作空间下的功能包,
创建功能包命令说明: rospy: 调用python的依赖库,
roscpp: 调用c++的依赖库
std_msgs: 调用ros定义的一些标准的消息结构的依赖
根据自己创建的功能包需要的用到哪些库,后面就跟哪些依赖,且数量不止可以调用3个,
顺序不分先后,
第(3)步:cd ~/catkin_ws, 再切换到catkin_ws功能空间根目录下,
第(4)步:catkin_make, 编译功能包
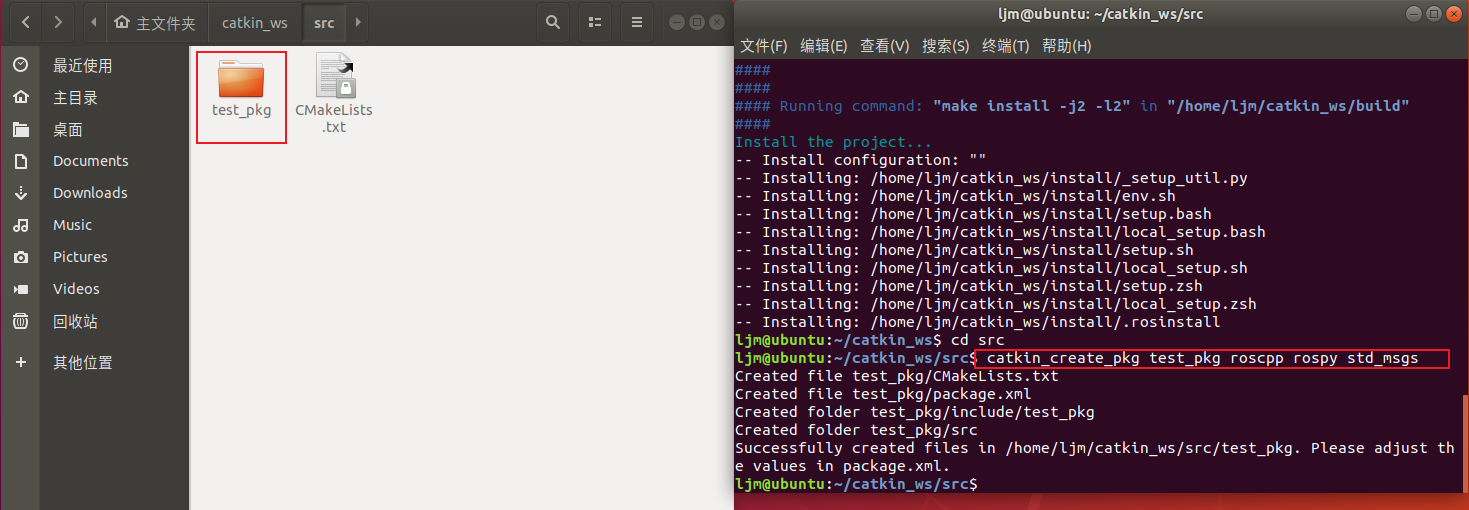
打开我们创建的test_pkg功能包文件夹如下:
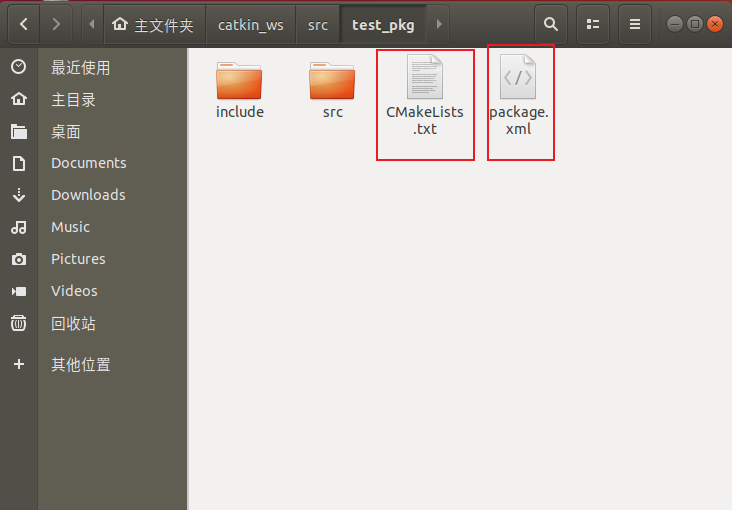
src: 放置功能包源码
include: 放置头文件,如c++里面的.h头文件
CMakeLists.txt 与 package.xml 是每个功能包文件夹中必须存在的两个文件,有这两个文件的存在才标志着你这个文件夹是功能包文件的属性而不是一个普通的文件夹。
编译功能包后如下:
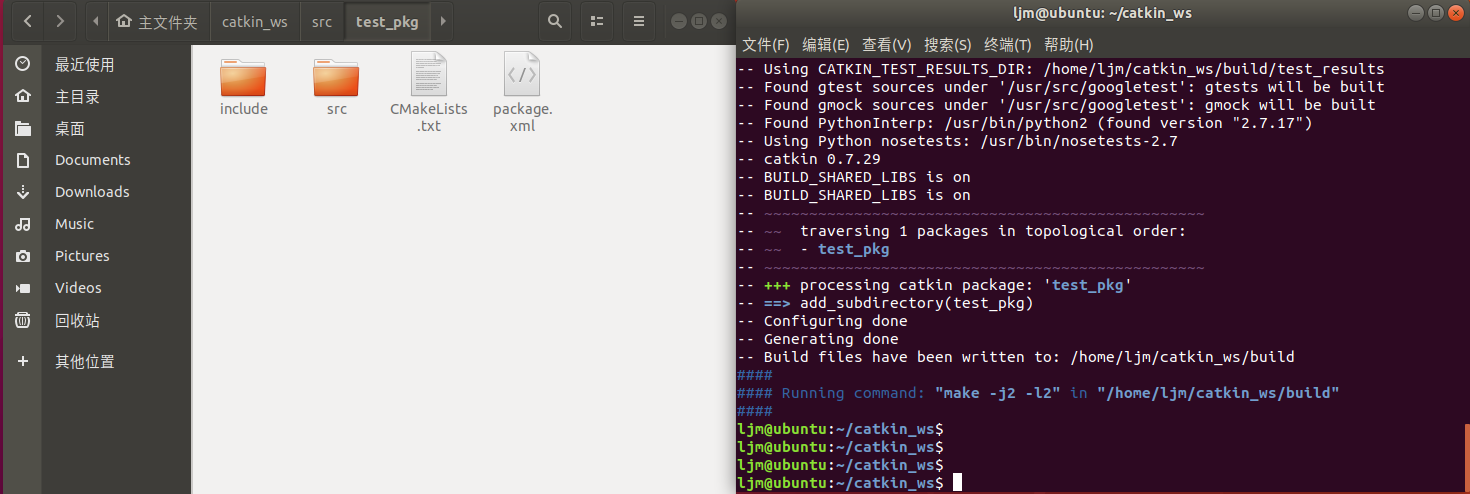
因为功能包内并没有什么代码,所以也并没有什么编译的效果。
编译完成之后,如果我们要运行我们创建的功能包中的某一个程序的话,
我们还需要去设置一下我们创建的工作空间的环境变量,如下:4
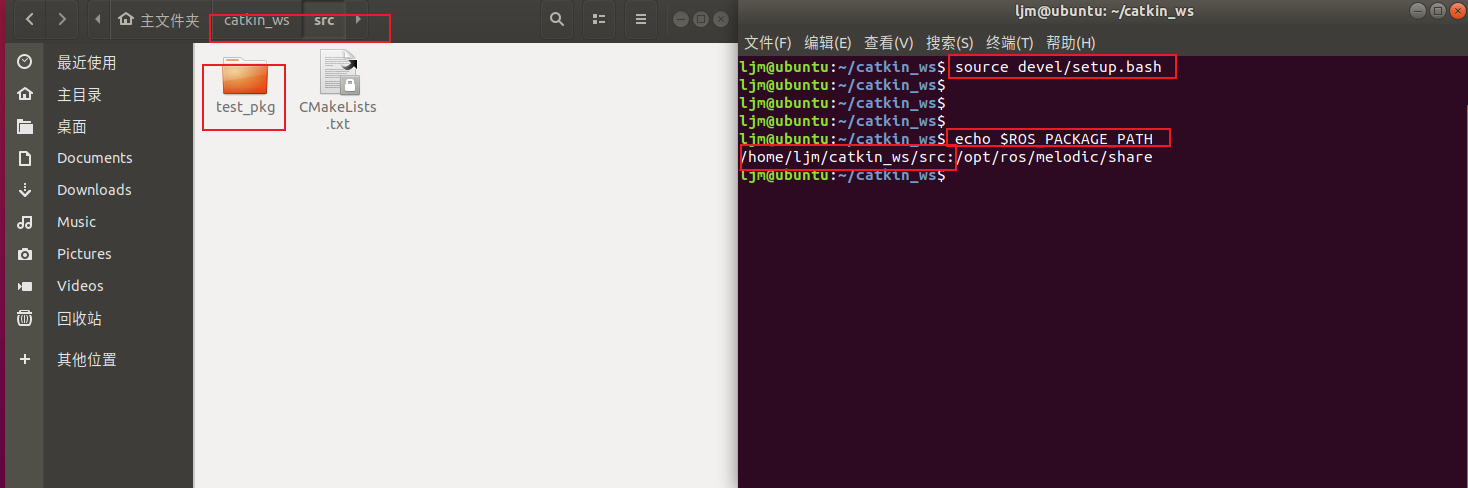
设置环境变量
cd ~/catkin_ws source devel/setup.bash echo $ROS_PACKAGE_PATH
第(1)步:cd ~/catkin_ws , 先切换到catkin_ws功能空间根目录下,
第(2)步:source devel/setup.bash, 对我们创建的catkin_ws工作空间进行环境变量设置,
setup.bash文件在home/catkin_ws/devel下,
只有对catkin_ws工作空间进行环境变量设置之后,
ROS系统才能找到我们创建的catkin_ws工作空间及其里面一些对应的功能包
第(3)步:echo $ROS_PACKAGE_PATH,
ROS_PACKAGE_PATH 是ROS本身的环境变量,
ROS系统里所有的功能包路径都是通过ROS_PACKAGE_PATH这个环境变量查找的,
所以只有上一步对我们创建的catkin_ws工作空间设置了环境变量之后,
我们创建的catkin_ws工作空间的路径才会加到ROS_PACKAGE_PATH中的PATH中。