苏州网站建站公司360网站建设基本情况
目录
一.在钉钉群里添加机器人
二.配置钉钉告警脚本
1.安装python依赖模块python-requests
2.配置钉钉告警配置脚本zabbix_ding.conf
3.创建告警日志并且授权。
4.配置钉钉告警执行脚本dingding.py
5.测试
三.配置zabbix告警
1.创建媒介
2.给用户添加报警媒介
3.配置动作
4.测试
一.在钉钉群里添加机器人
通过自定义webhook接入自定义服务
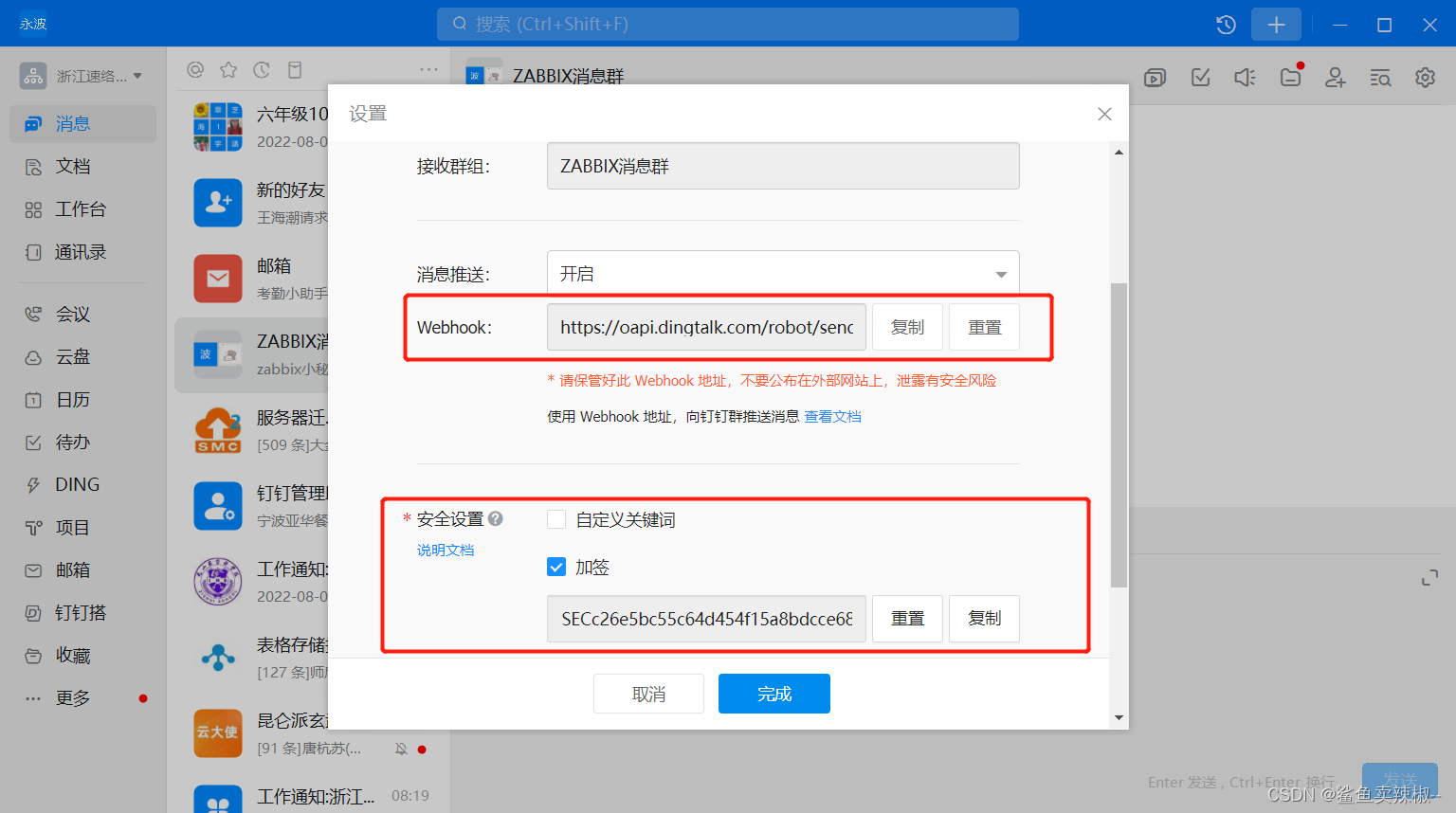
注意:webbhook:记住webhhook地址和;
安全设置:设置加签,只有信息内容包含签才会被机器人发送。
二.配置钉钉告警脚本
1.安装python依赖模块python-requests
yum -y install python3 python3-requests2.配置钉钉告警配置脚本zabbix_ding.conf
在/etc/zabbix下创建zabbix_dinf.conf 。
[root@server01 ~]# vim /etc/zabbix/zabbix_ding.conf
[config]
log_path=/var/log/zabbix/zabbix_ding.log
webhook=https://oapi.dingtalk.com/robot/send?access_token=2d691339c865c548c6f2d19af32094eefd054e63d520815f39098bb373fd3516
secret=SEC3e31084bf8b8fbe4897918035a6049359c125bb3a204048045ce68b034c2596d3.创建告警日志并且授权。
[root@server01 ~]# touch /var/log/zabbix/zabbix_ding.log
[root@server01 ~]# chown zabbix.zabbix /var/log/zabbix/zabbix_ding.log 4.配置钉钉告警执行脚本dingding.py
注意: 系统需要同步时间
- 在/usr/lib/zabbix/alertscripts目录中执行的脚本dingding.py的内容
[root@server01 ~]# cd /usr/lib/zabbix/alertscripts/
[root@server01 alertscripts]# vim dingding.py
#!/usr/bin/env python3
# coding:utf8
#
import configparser
import os
import time
import hmac
import hashlib
import base64
import urllib.parse
import requests
import json
import sysconfig = configparser.ConfigParser()
config.read('/etc/zabbix/zabbix_ding.conf', encoding='utf-8')
log_path = config.get('config', 'log_path')
api_url = config.get('config', 'webhook')
api_secret = config.get('config', 'secret')
log_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())# 钉钉机器人文档说明
# https://ding-doc.dingtalk.com/doc#/serverapi2/qf2nxq
def get_timestamp_sign():timestamp = str(round(time.time() * 1000))secret = api_secretsecret_enc = secret.encode('utf-8')string_to_sign = '{}\n{}'.format(timestamp, secret)string_to_sign_enc = string_to_sign.encode('utf-8')hmac_code = hmac.new(secret_enc, string_to_sign_enc, digestmod=hashlib.sha256).digest()sign = urllib.parse.quote_plus(base64.b64encode(hmac_code))return timestamp, sign# 获取加签后的链接
def get_signed_url():timestamp, sign = get_timestamp_sign()webhook = api_url + "×tamp=" + timestamp + "&sign=" + signreturn webhook# 定义消息模式
def get_webhook(mode):if mode == 0: # only 关键字webhook = api_urlelif mode == 1 or mode == 2: # 关键字和加签 或 # 关键字+加签+ipwebhook = get_signed_url()else:webhook = ""print("error! mode: ", mode, " webhook : ", webhook)return webhookdef get_message(text, user_info):# 和类型相对应,具体可以看文档 :https://ding-doc.dingtalk.com/doc#/serverapi2/qf2nxq# 可以设置某个人的手机号,指定对象发送message = {"msgtype": "text", # 有text, "markdown"、link、整体跳转ActionCard 、独立跳转ActionCard、FeedCard类型等"text": {"content": text # 消息内容},"at": {"atMobiles": [user_info,],"isAtAll": False # 是否是发送群中全体成员}}return message# 消息发送日志
def log(info):if os.path.exists(log_path):log_file = open(log_path, "a+")else:log_file = open(log_path, "w+")log_file.write(info)def send_ding_message(text, user_info):# 请求的URL,WebHook地址# 主要模式有 0 : 关键字 1:# 关键字 +加签 3:关键字+加签+IPwebhook = get_webhook(1)# 构建请求头部header = {"Content-Type": "application/json","Charset": "UTF-8"}# 构建请求数据message = get_message(text, user_info)# 对请求的数据进行json封装message_json = json.dumps(message)# 发送请求info = requests.post(url=webhook, data=message_json, headers=header).json()code = info["errcode"]errmsg = info["errmsg"]if code == 0:log(log_time + ":消息已发送成功 返回信息:%s %s\n" % (code, errmsg))else:log(log_time + ":消息发送失败 返回信息:%s %s\n" % (code, errmsg))print(log_time + ":消息发送失败 返回信息:%s %s\n" % (code, errmsg))exit(3)if __name__ == "__main__":text = sys.argv[3]user_info = sys.argv[1]send_ding_message(text, user_info)- 在zabbix_server.conf中配置告警脚本的路径
[root@server01 ~]# vim /etc/zabbix/zabbix_server.conf
AlertScriptsPath=/usr/lib/zabbix/alertscripts
- 设置脚本所有权和执行权
[root@server01 ~]# chown zabbix.zabbix -R /usr/lib/zabbix/alertscripts/
[root@server01 ~]# cd /usr/lib/zabbix/alertscripts/
[root@server01 alertscripts]# chmod +x dingding.py
[root@server01 alertscripts]# ll
总用量 4
-rwxr-xr-x 1 zabbix zabbix 3334 11月 15 17:50 dingding.py
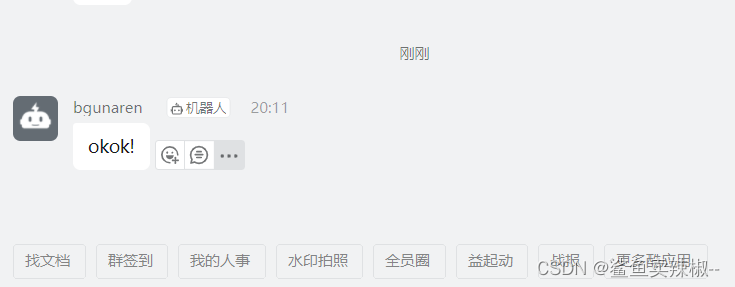
5.测试
[root@server01 alertscripts]# ./dingding.py user subject okok!
三.配置zabbix告警
1.创建媒介
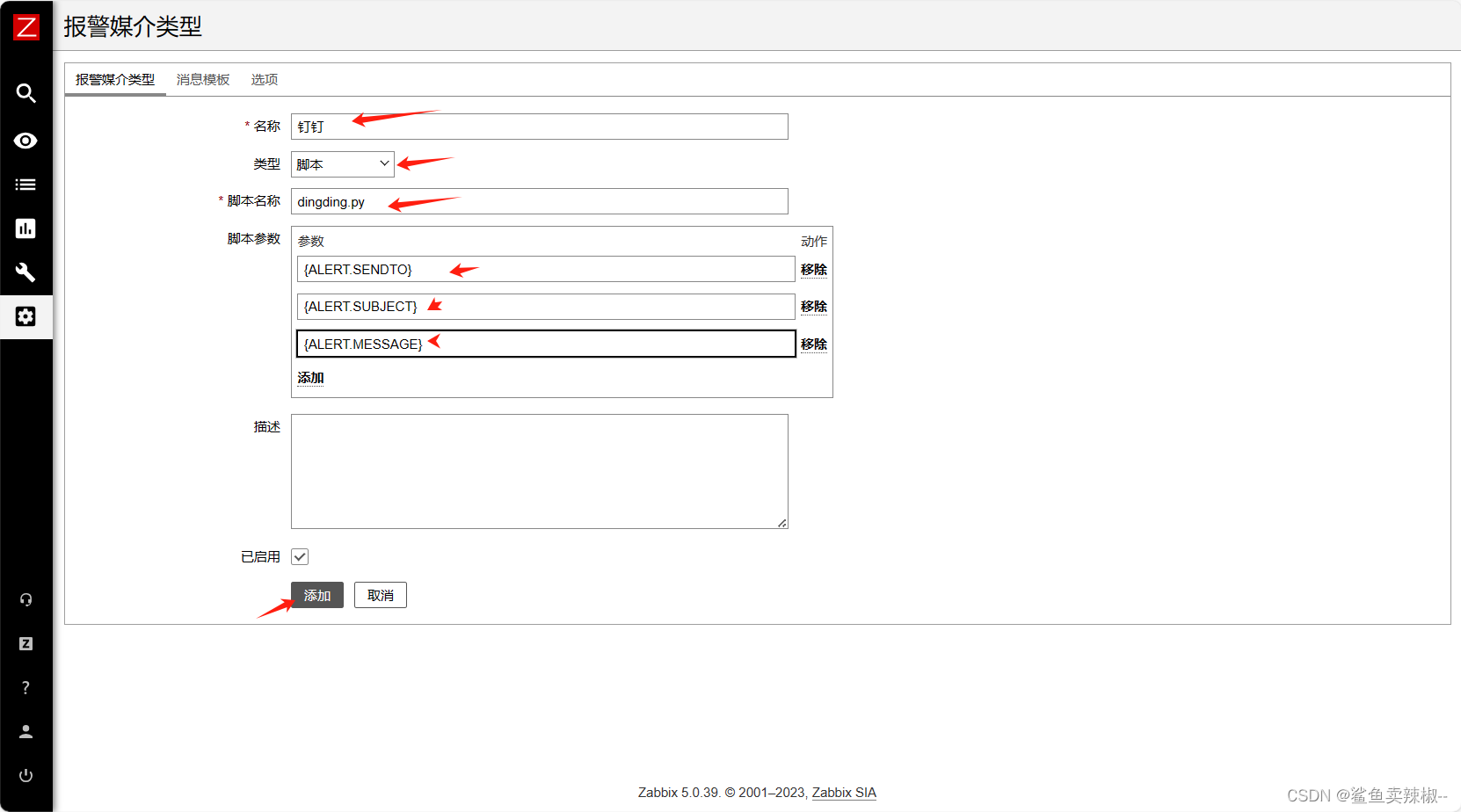
管理--->报警媒介类型--->创建报警媒介类型
脚本参数:{ALERT.SENDTO}
{ALERT.SUBJECT}
{ALERT.MESSAGE}
创建消息模板:添加问题模板和问题恢复模板。

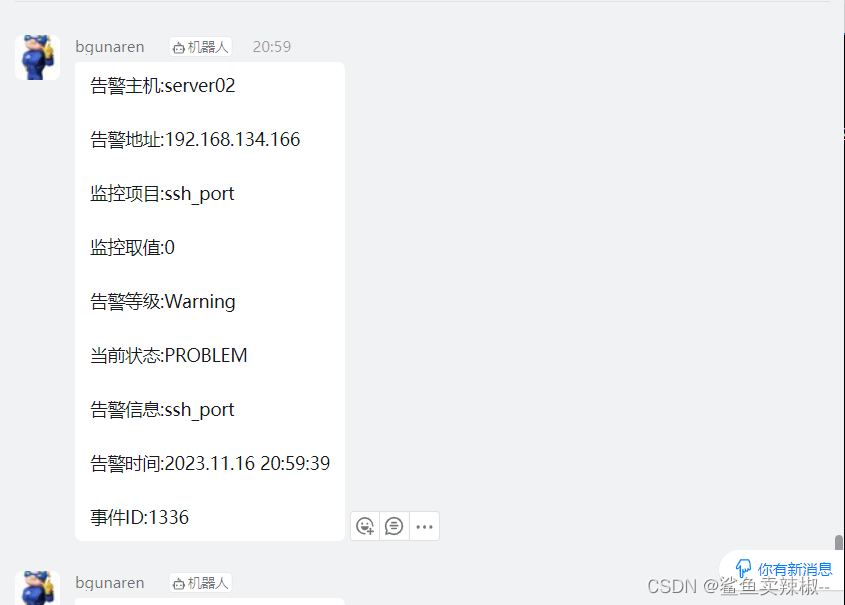
消息模板:
主题:服务器报警
消息:
告警主机:{HOST.NAME}
告警地址:{HOST.IP}
监控项目:{ITEM.NAME}
监控取值:{ITEM.LASTVALUE}
告警等级:{TRIGGER.SEVERITY}
当前状态:{TRIGGER.STATUS}
告警信息:{TRIGGER.NAME}
告警时间:{EVENT.DATE} {EVENT.TIME}
事件ID:{EVENT.ID}
主题:服务器已恢复
消息:
告警主机:{HOST.NAME}
告警地址:{HOST.IP}
监控项目:{ITEM.NAME}
监控取值:{ITEM.LASTVALUE}
告警等级:{TRIGGER.SEVERITY}
当前状态:{TRIGGER.STATUS}
告警信息:{TRIGGER.NAME}
告警时间:{EVENT.DATE} {EVENT.TIME}
事件ID:{EVENT.ID}
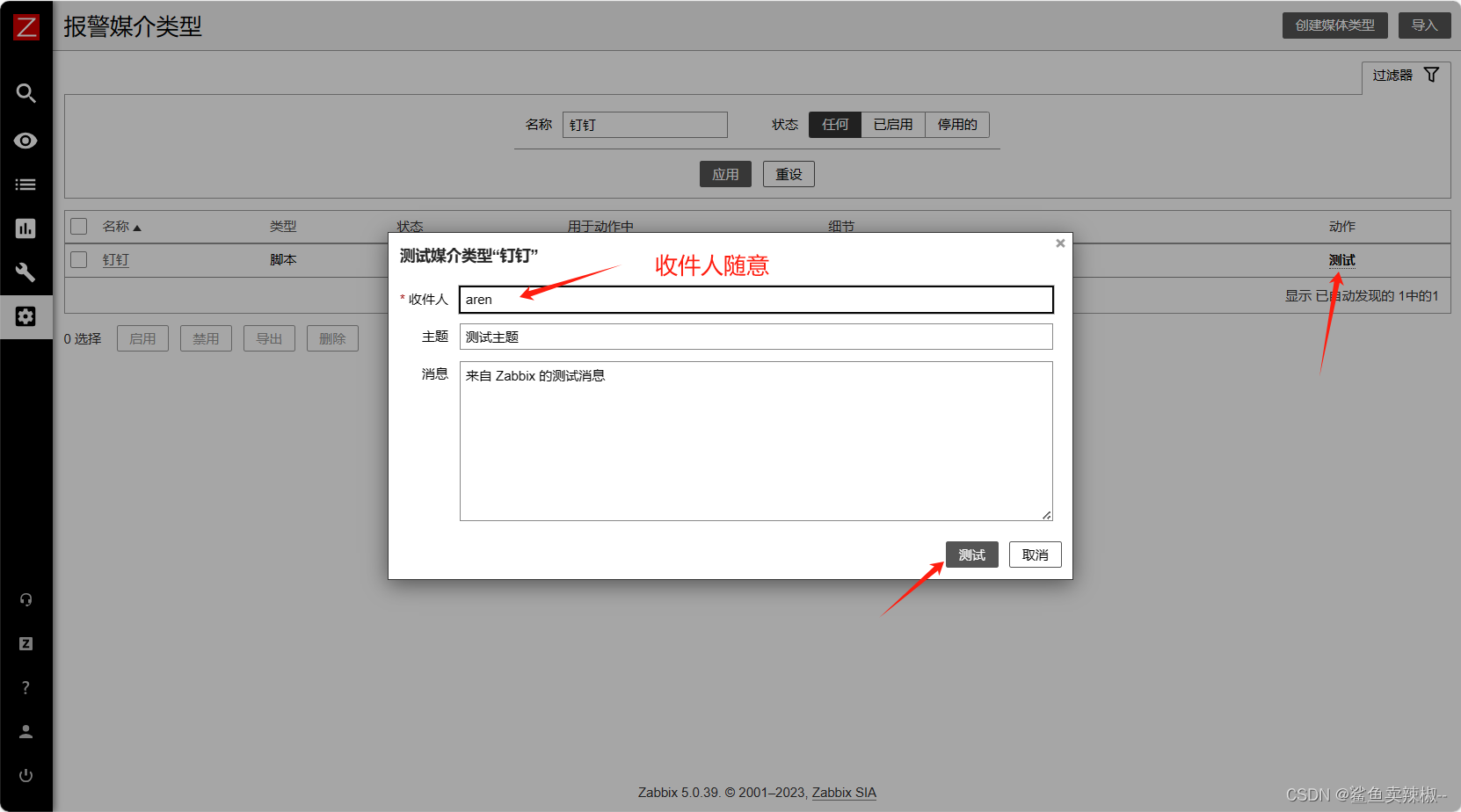
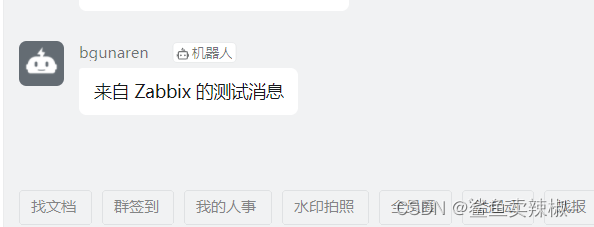
测试媒介:
可以看出机器人已发送测试消息。
2.给用户添加报警媒介
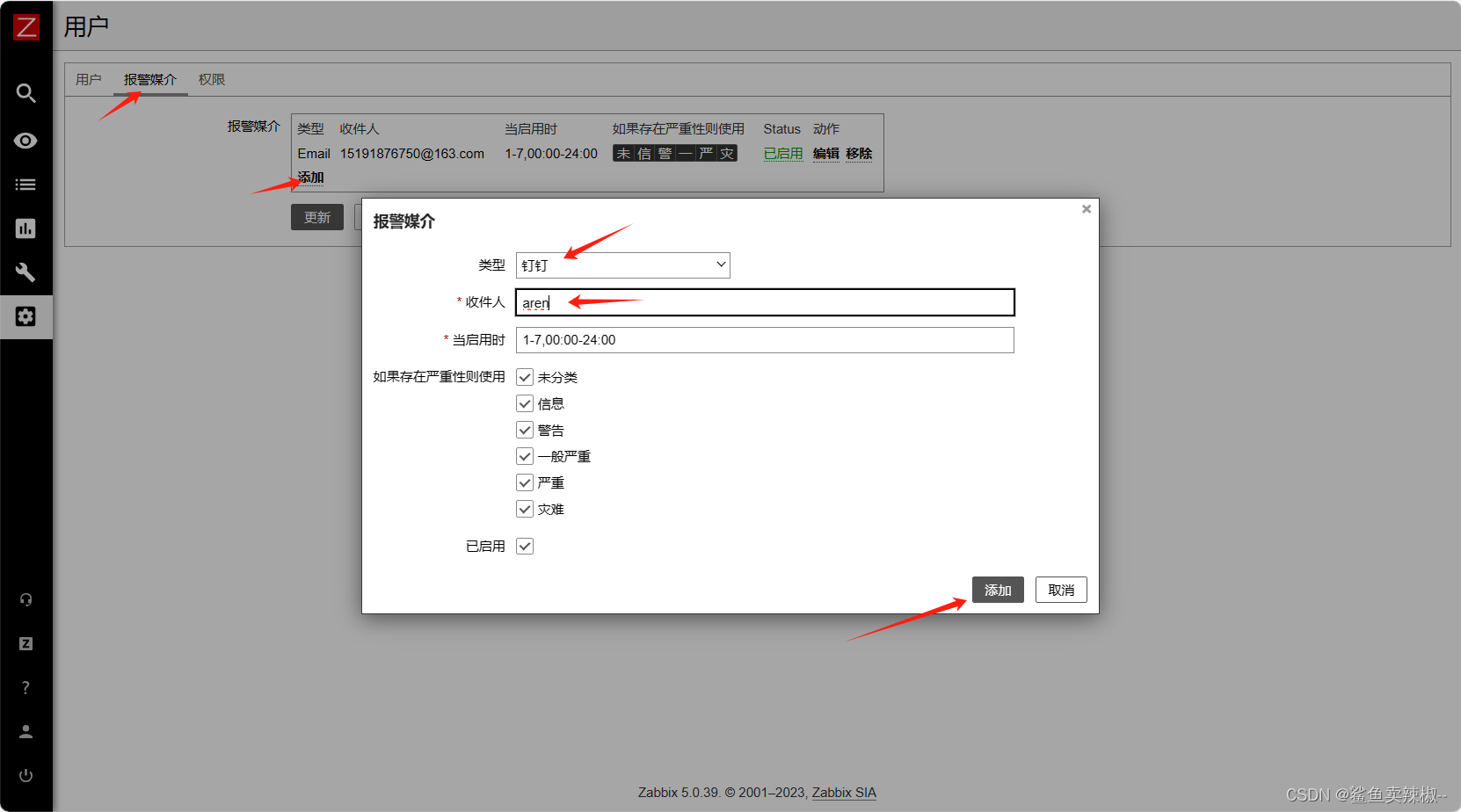
管理-->用户-->Admin
添加后需要更新
3.配置动作
这里需要有触发器才能配置动作。
配置--->动作
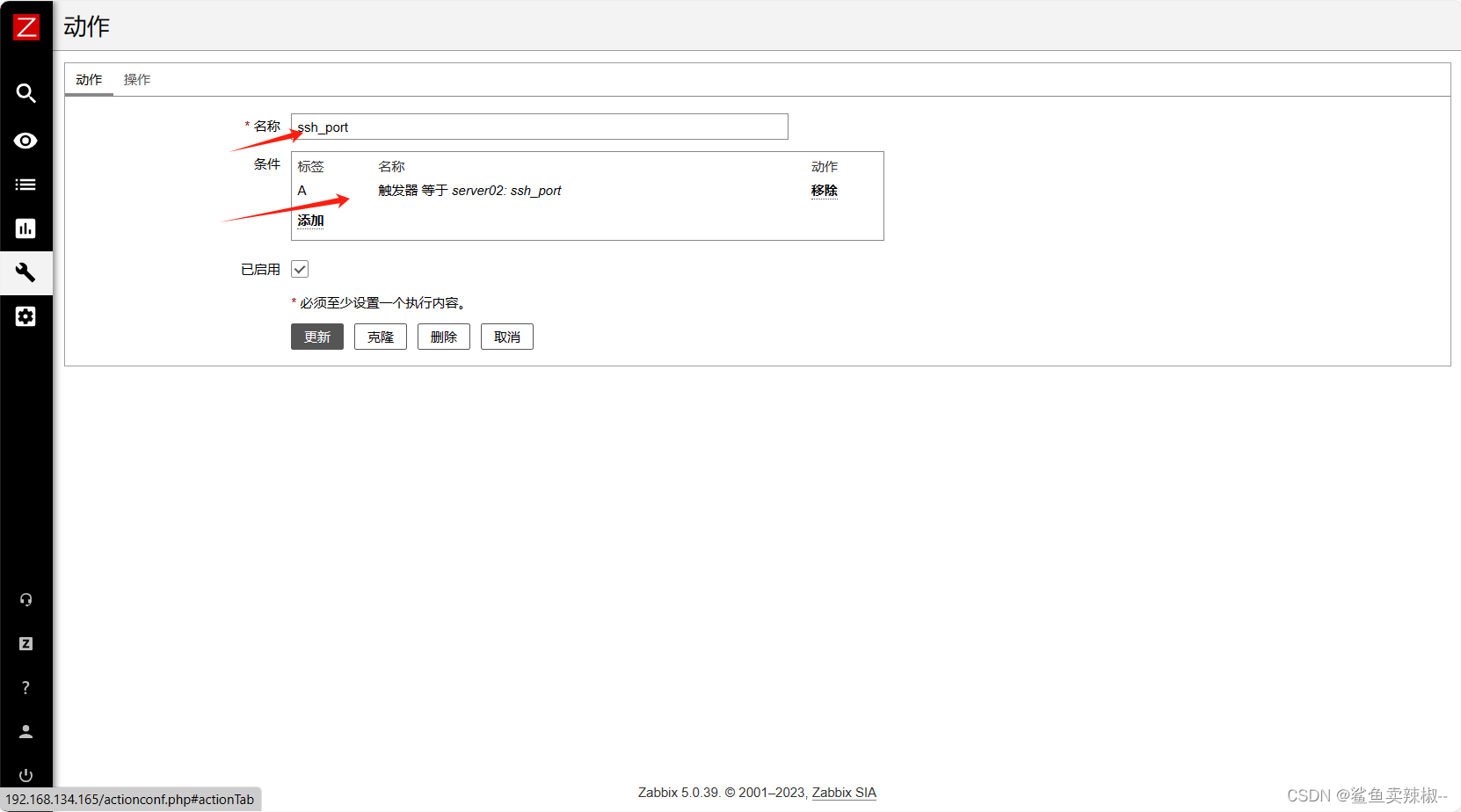
- 添加具体操作
操作:
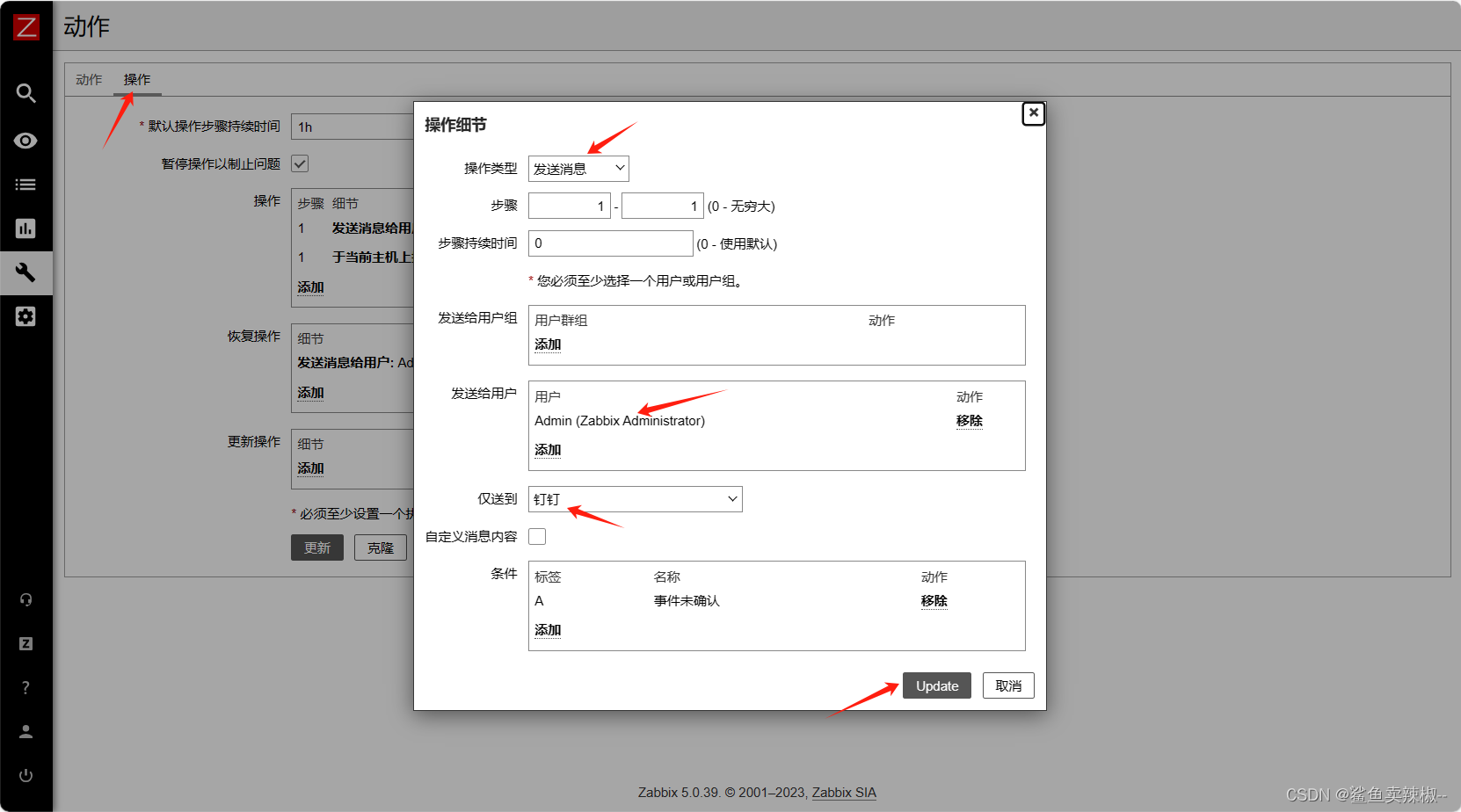
还需要在虚拟机上进行两项操作,一是修改sudo配置文件使zabbix用户能够临时拥有管理员权限;二是修改zabbix配置文件使其允许接收远程命令。我们进行如下操作:
[root@server02 ~]# visudo #相当于“vim /etc/sudoers”## Allow root to run any commands anywhereroot ALL=(ALL) ALLzabbix ALL=(ALL) NOPASSWD: ALL #添加的一行,表示不需要输入密码 [root@server02 ~]# vim /etc/zabbix/zabbix_agentd.conf EnableRemoteCommands=1 #允许接收远程命令 修改原有的值,不要在末尾追加LogRemoteCommands=1 #把接收的远程命令记入日志 [root@server02 ~]# systemctl restart zabbix-agent.service
恢复操作:
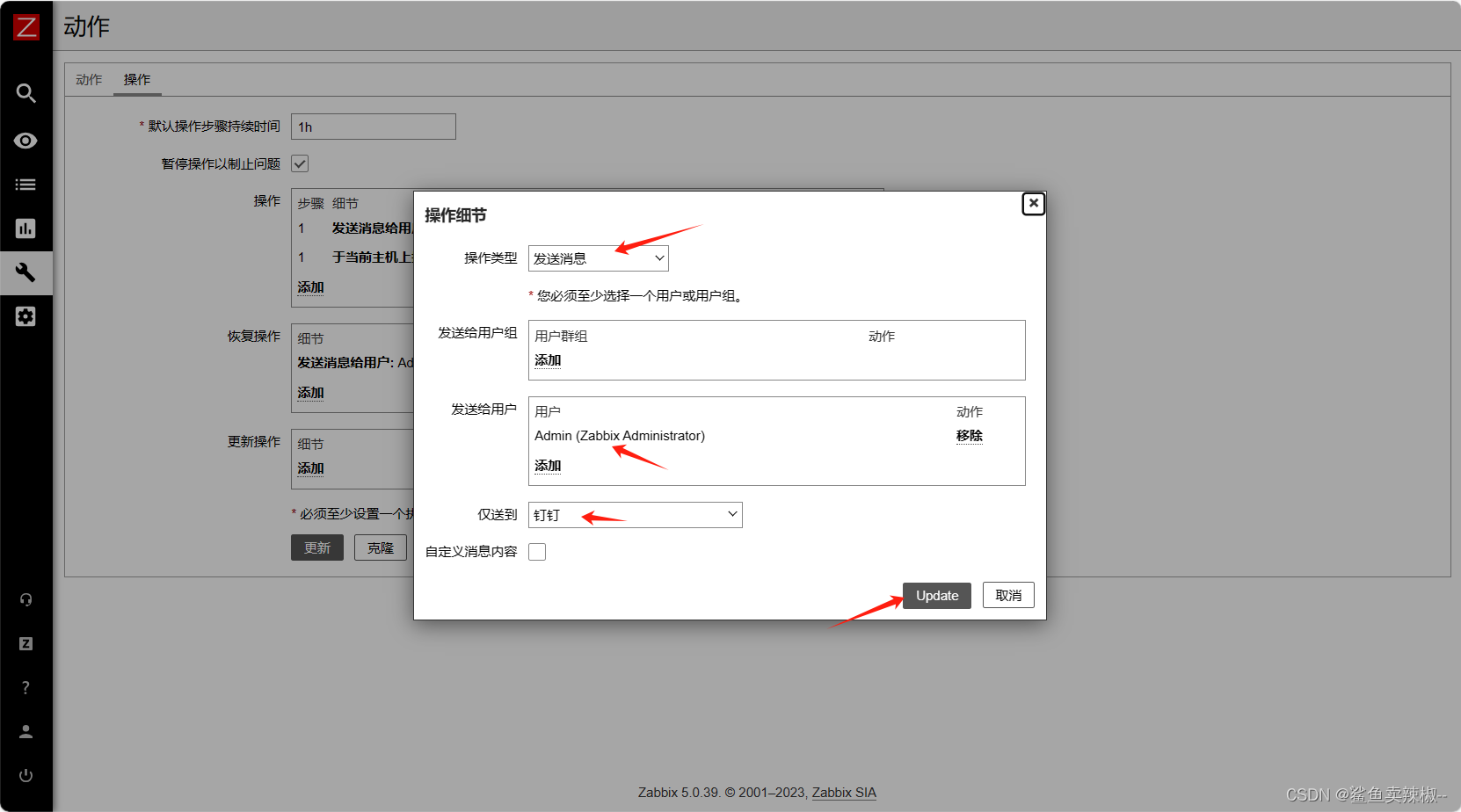
4.测试
这里我们监控的是客户端的22端口,将22端口停掉。机器人会发出警告。
[root@server02 ~]# systemctl stop sshd