上海网站建设助君网络7微信小程序制作个人版
小程序中门店信息是非常重要的,通常需要有门店地址、门店电话和营业时间等。采云小程序支持设置多个门店联系电话,避免客户无法联系到门店。而且,也支持设置多个营业时间时段。例如周一到周五早08:00 - 18:00 。客户在周末下单的时候,系统会自动把发货时间修改到周一。下面具体介绍如何设置二个参数。
1. 设置多个联系电话。
在门店设置处,门店电话后点击+,可以新增更多的门店电话。如果不需要此电话,点击后面的X,可以删除此电话。

2. 设置多个营业时间。
在门店设置处,营业时间后点击+,可以新增更多的营业时间。例如第一段营业时间是周一到周三,第二段是周五到周六。
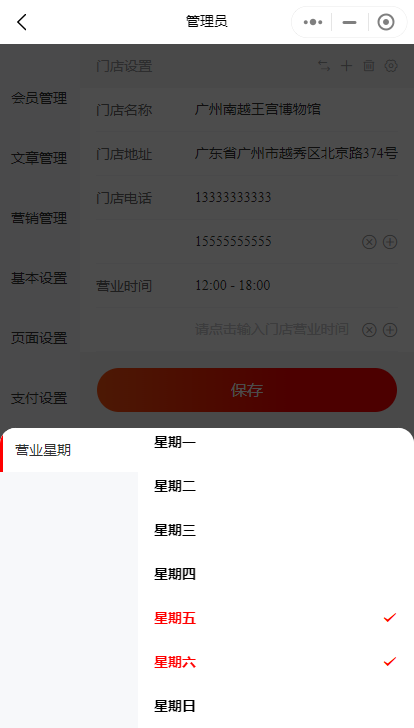


在小程序中设置多个联系电话和营业时间对于提升用户体验和方便用户获取门店信息是非常重要的。通过清晰地展示多个联系电话和营业时间,可以让用户更加方便地与门店取得联系并选择合适的时间前往门店或下单。如果你还没有这样的小程序,搜一搜采云去免费开通。